
Books read in 2021: Part 1

Each year Gazettabyte asks industry figures to pick their reads of the year. Paul Brooks and Maxim Kuschnerov kick off this year’s recommended reads.
Dr. Paul Brooks, Optical Transport Director, VIAVI Solutions
Having spent a very happy time serving in the Royal Navy, I am always reading about all things connected with its history.
As a young midshipman, I managed to sleep through many of the history lessons at BRNC Dartmouth so I am using my spare time to catch up on the lessons I missed all those years ago.
One book which I have very much enjoyed this year has been Stephen Taylor’s Sons of the Waves: The Common Seaman in the Heroic Age of Sail.
While many books are written about major figures such as Nelson and Blake, the ordinary sailor with his robustness, loyalty and sense of duty was the key element in the success of the Royal Navy.
This well-researched book is a joy to read as it brings to life the heroic men. I must confess I did hum ‘Heart of Oak’ as I reached for my tot of rum as I read about the jolly Jack Tar on the Victory at Trafalgar!
For any student of history, and indeed anyone interested in social history, this is one for your Christmas list.
Dr. Maxim Kuschnerov, Director of the Optical & Quantum Communications Laboratory
No Rules Rules: Netflix and the Culture of Reinvention, by Reed Hastings and Erin Meyer, got good press last year, so when I saw it at the airport, it was a no brainer to get it.
The book offers a radical approach to management, focusing on totally open feedback and the removal of most controls, whether it’s the lack of vacation policy (take as much as you want) or the absence of higher approvals for most business dealings. Salary adjustments are governed by external market references and not internal processes, which is generally not a bad thing.
Naturally, looking at this corporate culture through the glasses of a German dependency of a Chinese company makes for a big contrast and it would be hard to imagine a German company functioning without any kind of rules. But what the book achieves is to shift the normal operational bias towards a more modern view of team management and it helped me to make adjustments in everyday work, changing the way that I interpreted my role within my team.
This brings me straight to another, older, book by Erin Meyer, The Culture Map: Breaking Through the Invisible Boundaries of Global Business. It reads like a compressed tutorial of inter-cultural communication and decision making, although I have to admit it was almost more fun to naively learn all of this in the field than to have all the findings confirmed at a later point by the conclusions in this book.
I found it particularly interesting to see the historical context for some present cultural behaviour, by which I don’t mean the obvious teaching of Confucius for Chinese people but also current social traits in Europe dating back to the Roman Empire.
So when a Chinese colleague, who recently moved to Germany, described the German personality as a coconut after the first weeks of adjusting to life in Munich, it made me think that we should be providing this book as a compulsory read within the company, just to soften the blow.
Lastly, looking at how big data and analytics started to change our lives in many domains and found their way into sport in the classic Moneyball book, I believe that no other sport has been changed as drastically by a statistical approach to analytics as basketball.
Kirk Goldberry’s Sprawlball: A Visual Tour of the New Era of the NBA explains the dramatic change in the game by findings that, in hindsight, are so obvious that one can only wonder how we all didn’t see it coming in the 1990s when the GOAT Michael Jordan redefined the art of playing ball.
Goldberry explains the historical context for modern-day greats like LeBron James, James Harden and Steph Curry, while also giving a shout-out to my other personal favourite, Dirk Nowitzki, whose 2011 finals run will stay at the top of my sporting moments.
I just wish I could have told my 14-year-old self to stop practising baby hooks and post ups and go straight to 3-point drills.

Waiting for buses: PCI Express 6.0 to arrive on time

- PCI Express 6.0 (PCIe 6.0) continues the trend of doubling the speed of the point-to-point bus every 3 years.
- PCIe 6.0 uses PAM-4 signalling for the first time to achieve 64 giga-transfers per second (GT/s).
- Given the importance of the bus for interconnect standards such as the Compute Express Link (CXL) that supports disaggregation, the new bus can’t come fast enough for server vendors.
The PCI Express 6.0 specification is expected to be completed early next year.
So says Richard Solomon, vice-chair of the PCI Special Interest Group (PCI-SIG) which oversees the long-established PCI Express (PCIe) standard, and that has nearly 900 member companies.
The first announced products will then follow later next year while IP blocks supporting the 6.0 standard exist now.
When the work to develop the point-to-point communications standard was announced in 2019, developing lanes capable of 64 giga transfers-per-second (GT/s) in just two years was deemed ambitious, especially given 4-level pulse amplitude modulation (PAM-4) would be adopted for the first time.
But Solomon says the global pandemic may have benefitted development due to engineers working from home and spending more time on the standard. Demand from applications such as storage and artificial intelligence (AI)/ machine learning have also been driving factors.
Applications
The PCIe standard uses a dual simplex scheme – serial transmissions in both directions – referred to as a lane. The bus can be configured in several lane configurations: x1, x2, x4, x8, x12, x16 and x32, although x2, x12 and x32 are rarely used in practice.
PCIe 6.0’s transfer rate of 64GT/s is double that of the PCIe 5.0 standard that is already being adopted in products.
The PCIe bus is used for storage, processors, AI, the Internet of Things (IoT), mobile, and automotive especially with the advent of advanced driver assistance systems (ADAS). “Advanced driver assistance systems use a lot of AI; there is a huge amount of vision processing going on,” says Solomon.
For cloud applications, the bus is used for servers and storage. For servers, PCIe has been adopted by general-purpose processors and more specialist devices such as FPGAs, graphics processor units (GPUs) and AI hardware.
IBM’s latest 7nm POWER10 16-core processor, for example, is an 18-billion transistor device. The chip uses the PCIe 5.0 bus as part of its input-output.
In contrast, IoT applications typically adopt older generation PCIe interfaces. “It will be PCIe at 8 gigabit when the industry is on 16 and 32 gigabit,” says Solomon.
PCIe is being used for IoT because of it being a widely adopted interface and because PCIe devices interface like memory, using a load-store approach.
The CXL standard – an important technology for the data centre that interconnects processors, accelerator devices, memory, and switching – also makes use of PCIe, sitting on top of the PCIe physical layer.

PCIe roadmap
The PCIe 4.0 came out relatively late but then PCI-SIG quickly followed with PCIe 5.0 and now the 6.0 specification.
The PCIe 6.0 specification built into the schedule an allowance for some slippage while still being ready for when the industry would need the technology. But even with the adoption of PAM-4, the standard has kept to the original ambitious schedule.
PCIe 4.0 incorporated an important change by extending the number of outstanding commands and data. Before the 4.0 specification, PCIe allowed for up to 256 commands to be outstanding. With PCIe 4.0 that was tripled to 768.
To understand why this is needed, a host CPU system may support several add-in cards. When a card makes a read request, it may take the host a while to service the request, especially if the memory system is remote.
A way around that is for the add-in card to issue more commands to hide the latency.
“As the bus goes faster and faster, the transfer time goes down and the systems are frankly busier,” says Solomon. “If you are busy, I need to give you more commands so I can cover that latency.”
The PCIe technical terms are tags, a tag identifying each command, and credits which refers to how the bus takes care of flow control.
“You can think of tags as the sheer number of outstanding commands and credits as more as the amount of overall outstanding data,” says Solomon.
Both tags and credits had to be changed to support up to 768 outstanding commands. And this protocol change has been carried over into PCI 5.0.
In addition to the doubling in transfer rate to 32GT/s, PCI 5.0 requires an enhanced link budget of 36dB, up from 28dB with the PCIe 4.0. “As the frequency [of the signals] goes up, so does the loss,” says Solomon.
PCI 6.0
Moving from 32GT/s to 64GT/s and yet keep ensuring the same typical distances requires PAM-4.
More sophisticated circuitry at each end of the link is needed as well as a forward-error correction scheme which is a first for a PCI express standard implementation.
One advantage is that PAM-4 is already widely used for 56 and 112 gigabit-per-second high-speed interfaces. “That is why it was reasonable to set an aggressive timescale because we are leveraging a technology that is out there,” says Solomon. Here, PAM-4 will be operated at 64Gbps.
The tags and credits have again been expanded for PCI 6.0 to support 16,384 outstanding commands. “Hopefully, it will not be needed to be extended again,” says Solomon.
PCIe 6.0 also supports FLITs – a network packet scheme – that simplifies data transfers. FLITs are introduced with PCIe 6.0, but silicon designed for PCIe 6.0 could use FLITs at lower transfer speeds. Meanwhile, there are no signs of PCI Express needing to embrace optics as the interface speeds continue to advance.
“There is a ton of complexity and additional stuff we have to do to move to 6.0; optical would add to that,” says Solomon. “As long as people can do it on copper, they will keep doing it on copper.”
PCI-SIG is not yet talking about PCIe 7.0 but Solomon points out that every generation has doubled the transfer rate.

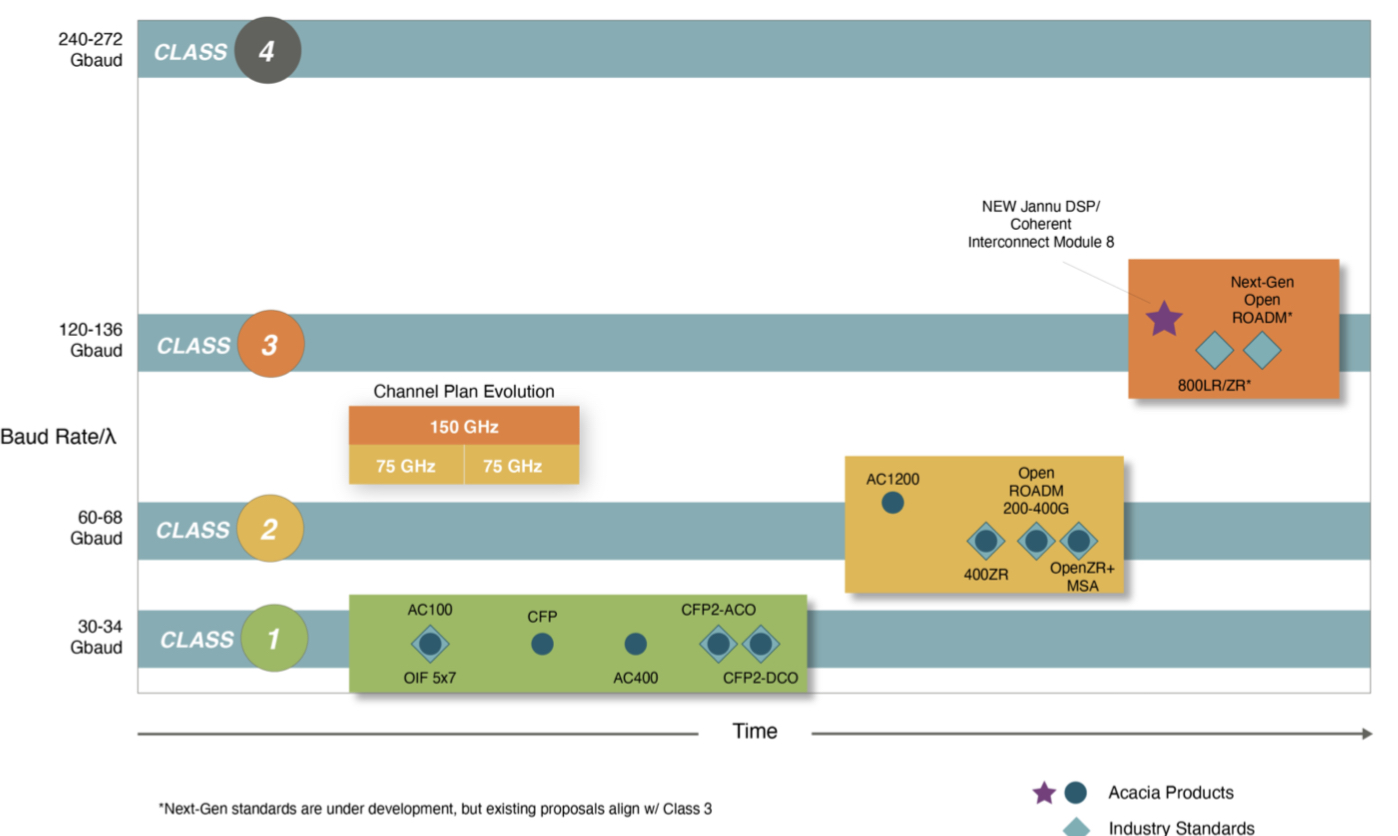
Acacia's single-wavelength terabit coherent module

- Acacia has developed a 140-gigabaud, 1.2-terabit coherent module
- The module, using 16-ary quadrature amplitude modulation (16-QAM), can deliver an 800-gigabit wavelength over 90 per cent of the links of a North American operator.
Acacia Communications, now part of Cisco, has announced the first 1.2-terabit single-wavelength coherent pluggable transceiver.
And the first vendor, ZTE, has already showcased a prototype using Acacia’s single-carrier 1.2 terabit-per-second (Tbps) design.
The coherent module operates at a symbol rate of up to 140 gigabaud (GBd) using silicon photonics technology. Until now, indium phosphide has always been the material at the forefront of each symbol rate hike.
The module uses Acacia’s latest Jannu coherent digital signal processor (DSP), implemented in 5nm CMOS. The coherent transceiver also uses a custom form-factor pluggable dubbed the Coherent Interconnect Module 8 (CIM-8).
Trends
Acacia refers to its 1.2-terabit coherent pluggable as a multi-haul design, a break from its product categorisation as either embedded or pluggable.
“We are introducing a pluggable module that supports what has traditionally been the embedded market,” says Tom Williams, senior director of marketing at Acacia. “It supports high-capacity edge applications all the way out to long-haul and submarine.”
Pluggables are the fastest-growing segment of the coherent market. Whereas the mix of custom embedded designs to pluggable interoperable is 2:1, that is forecast to change with coherent pluggables accounting for two-thirds of the total ports.
Acacia highlights the growth of coherent pluggables with two examples.
Data centre operator Microsoft used Inphi’s (now Marvell’s) ColorZ direct-detect 100-gigabit modules for data centre interconnect for up to 80km whereas now the industry is moving to the 400ZR coherent MSA.
In turn, while proprietary embedded coherent solutions would be used for reconfigurable optical add-drop multiplexers (ROADMs), now, interoperable pluggable coherent modules are being adopted with the OpenROADM MSA.
“There is still a significant need in the market for full-performance multi-haul solutions but we think their development needs to be informed and influenced by pluggables,” says Williams.
1.2-terabit capacity
As coherent technology matures, the optical transmission performance is approaching the theoretical limit as defined by Claude Shannon.
“There is still opportunity for improvement,” says Williams. “We still have performance enhancements with each generation but it is becoming more incremental.”
Williams highlights how its latest design offers a 20–25 per cent spectral efficiency improvement compared to Acacia’s AC1200 that uses two wavelengths to deliver up to 1.2Tbps.
“As we increase baud rate, that alone does not give any improvement in spectral efficiency,” says Williams. It is the algorithmic enhancements that still boost performance.
Acacia is adopting an enhanced probabilistic constellation shaping (PCS) algorithm as well as an improved forward-error correction scheme. “There are also some benefits of a single carrier as opposed to using multiple carriers,” says Williams.
Design
The latest design is a natural extension of the AC1200 which can send 400 gigabits over ultra-long-haul distances, 800 gigabits using two wavelengths over most spans, and three 400-gigabit payloads over shorter, network-edge reaches. Now, this can all be done using a single wavelength.
A 150GHz channel is used when transmitting the module’s full rate of 1.2Tbps. And with the module’s adaptive baud rate feature, the rate can be reduced to fit a wavelength in a 75GHz-wide channel. Existing 800-gigabit transmissions use 112.5GHz channel widths and the multi-rate module also supports this spacing.
Williams says 16-QAM is the favoured signalling scheme used for transmission. This is what has been chosen for the 400ZR standard at 64GBd. Doubling the symbol rate means 800 gigabits can be sent using 16-QAM.
Acacia also highlights that future generation coherent designs, what it calls class 4 (see diagram above), will double the symbol rate again to some 240GBd. But the company is not saying whether the technology enabling such rates will be silicon photonics.
The company has long spoken of the benefits of using a silicon packaging approach for its coherent modules in terms of size, power and automated manufacturing. But as the symbol rate doubles, packaging plays a key role to help tackle challenging radio frequency (RF) design issues.
Acacia stacks the driver and trans-impedance amplifier (TIA) circuitry directly on top of its photonic integrated circuit (PIC) while its coherent DSP is also packaged as part of the design. “This gives us much better signal integrity than if we have the optics and DSP packaged separately,” says Williams.
The key to the design is getting the silicon photonics – the optical modulator, in particular – operating at 140GBd. “If you can, the packaging advantages of silicon are significant,” says Williams.
Acacia points out that with the migration of traffic from 100GbE to 400GbE it makes sense to offer a single-wavelength multi-rate design. And 400GbE will remain the mainstay traffic for a while. But once the transition to 800 gigabit occurs, the idea of supporting two coherent wavelengths – a future dual-wavelength “AC2400” – may make sense.
CIM-8
Acacia is using its own form factor and not a multi-source agreement (MSA) because the 1.2-terabit technology exceeds all existing client-side data rates.
In turn, the power consumption of the 1.2-terabit coherent module requires a custom form factor while launching an MSA based on the CIM-8 would have tipped off the competition, says Williams.
That said, Acacia has made no secret that its next high-end design following on from its 64GBd AC1200 would double the symbol rate and that the company would skip the 96GBd rate used by vendors such as Ciena, Huawei and Infinera already offering 800-gigabit wavelength systems.
For Acacia’s multi-rate design that needs to address submarine applications, the goal is to maximise transmission performance. In contrast, for a ZR+ coherent design that fits in a QSFP-DD, the limited power budget of the module constrains the design’s performance.
With 5nm Jannu DSP, Acacia realised it could not fit the design in the QSFP-DD or OSFP. But it could produce a pluggable multi-haul design with its CIM-8 that is slightly larger than the CFP2 form factor. And pluggables are advantageous when 4-8 can be fitted in a one-rack-unit (1RU) platform.
Acacia says its 140GBd module using 16-QAM will deliver an 800-gigabit wavelength over 90 per cent of the links of a North American operator. For the remaining, longest-distance links (the 10 per cent), it will revert to 400 gigabits.
In contrast, existing 800-gigabit systems operating at 96GBd cover up to 20 per cent of the links before having to revert to the slower speed, says Acacia.
Applications
Hyperscaler data centre operators are the main drivers for 1.2Tbps interconnects. The interface would typically be used in the metro to link smaller data centres to a larger aggregation data centre.
“The 1.2-terabit interface is just trying to maximise cost per bit; pushing more bits over the same set of optics,” says Williams.
The communications service providers’ requirements, meanwhile, are focussed on 400 gigabits and at some point will migrate to 800 gigabits, says Williams.
Several system vendors are expected to announce products using the new module in the coming months.

Lumentum bulks up with NeoPhotonics buy

Lumentum is to acquire fellow component and module specialist, NeoPhotonics, for $918 million.
The deal will expand Lumentum’s optical transmission product line, broadening its component portfolio and boosting its high-end coherent line-side product offerings.
Gaining NeoPhotonics’ 400-gigabit coherent offerings will enable Lumentum to better compete with Cisco and Marvell. Lumentum will also gain a talented team of photonics experts as it looks to address new opportunities.
Alan Lowe, Lumentum’s president and CEO, stressed the importance of this collective optical expertise.
Speaking on the call announcing the agreement, Lowe said the expanded know-how would benefit Lumentum’s traditional markets and accelerate its entrance into other, newer markets.
Transaction details
Lumentum will pay $16 in cash for each share of NeoPhotonics, valuing the company at $918 million. Lumentum will also pay $50 million to NeoPhotonics “for growth capex and working capital.”
Cost savings of $50 million in annual run-rate are expected within two years of the deal closing, with 60 per cent of the savings coming from the cost of goods sold.
The deal is reminiscent of Lumentum’s acquisition of Oclaro for $1.8 billion in 2018. Oclaro was also focussed on transmission components and modules.
The acquisition is expected to close in the second half of 2022, subject to the approval of NeoPhotonics’ stockholders and regulatory bodies.
Background
Lumentum’s announcement follows its failed bid early this year for the laser company, Coherent. II-VI ended up winning the bid, paying $6.9 billion.
Coherent’s lasers are used in many markets and the deal would have diversified Lumentum’s business beyond communications and smartphones.
Now, the proposed acquisition of NeoPhotonics boosts Lumentum’s core communications business unit. NeoPhotonics’ focus is cloud and networking although the company has been using its coherent expertise to address LiDAR and medical markets.
Vladimir Kozlov, CEO of market research firm LightCounting, does not see any inconsistency in Lumentum’s strategy to first diversify and then strengthen its core business. “There are many directions to accelerate company growth,” he says.
Lumentum tried one way with Coherent, it didn’t work out, now it is trying another with NeoPhotonics. “You take opportunities as they come along,” says Kozlov.
NeoPhotonics has also been impacted by the trade restrictions on Huawei, a significant customer of the company. NeoPhotonics has had to adapt to on-off sales to Huawei in recent years. Huawei also has a long-term strategy to develop its optical components including tunable lasers for which NeoPhotonics has been their leading supplier.
“That certainly added pressure on NeoPhotonics to be acquired,” says Kozlov.
Business opportunities
Lumentum’s business is split 60 per cent cloud and networking and 40 per cent 3D Sensing, LiDAR, and commercial lasers for industrial applications.
Lumentum’s cloud and networking products include reconfigurable optical add-drop multiplexing (ROADM) sub-systems, optical components for high-speed client-side and line-side modules, and coherent optical modules.
NeoPhotonics brings ultra narrow-linewidth tunable lasers, silicon photonics-based components and transceivers, and high-speed coherent modules and components. NeoPhotonics also has passive and planar lightwave circuit components and an RF chip design capability using gallium arsenide and silicon germanium.
Tim Jenks, president, CEO and chairman of NeoPhotonics, said combining the two firms would accelerate its business developing high-speed optical communications.
In turn, their combined R&D and technology teams can address new markets such as the life sciences, industrial applications, and green markets such as energy efficiency, electric vehicles and climate change green manufacturing concerns.
But no detail was forthcoming on the call beyond Lowe saying the merger will expand the collective know-how and accelerate its entrance into these markets.
Lowe also highlighted the strong growth in high-speed ports due to the 30 per cent year-on-year growth in internet bandwidth.
LightCounting says the dense wavelength division multiplexing (DWDM) coherent market will experience a compound annual growth rate (CAGR) of 20 per cent over the next five years; the general optical market is growing at a 14 per cent CAGR.
Both companies have indium-phosphide components for coherent systems while NeoPhotonics has pluggable 400ZR and ZR+ products as well as silicon photonics components for coherent. Gaining NeoPhotonics’ ultra-narrow linewidth lasers will make Lumentum an even stronger laser supplier.
LightCounting’s Kozlov notes the importance of scale, especially when target markets are not huge and the number of large customers is limited. This is the case with 400ZR/ ZR+ coherent DWDM transceivers that NeoPhotonics started selling in 2021.
Amazon is the biggest buyer of such modules and it uses three suppliers. NeoPhotonics is a distant third in the race behind Acacia, now part of Cisco, and Inphi, part of Marvell. But unlike Acacia and Inphi, NeoPhotonics does not have its own coherent DSP.
Joining forces with Lumentum, NeoPhotonics is more likely to win a larger share of business at key customers, says LightCounting. The new Lumentum may still be third in the race, but it is no longer a distant third.
Recent announcements
Lumentum started shipping its 400-gigabit CFP2-DCO coherent module earlier this year. Its range of indium-phosphide coherent components operates at a 96-gigabaud (GBd) symbol rate that supports up to 800-gigabit wavelengths. Lumentum is developing components that will operate at 128GBd.
Lumentum also has a directly modulated laser (DML) supporting 100-gigabit wavelengths. Such a laser is used for 100-gigabit and 400-gigabit client-side pluggables. The company is also developing electro-absorption modulated laser (EML) technology that supports 200 gigabits and higher performance per lane.
Meanwhile, NeoPhotonics is shipping 400ZR QSFP-DD and OSFP 400ZR coherent optical modules. NeoPhotonics also has a multi-rate CFP2-DCO module with a reach of 1,500km at 400 gigabits. And like Lumentum, the company has indium-phosphide technology that supports 130GBd coherent components.
Kozlov believes Lumentum is in a good position.
On the call announcing the deal, Lumentum also delivered its latest quarterly results. “They can hardly keep up with demand,” he says.
The issue of shortages is getting worse. This is not because the shortages themselves are getting worse but that demand is ramping faster than the shortage issue can be resolved. “It’s a good problem to have,” says Kozlov.
Industry consolidation
The Lumentum-NeoPhotonics deal follows the recent announcement of the merger of two other mature optical players such as the systems vendors: ADTRAN and ADVA.
LightCounting’s Kozlov agrees consolidation is happening among mature optical component and optical networking companies but he points out that many new optical start-ups are emerging and not just in China.
“At the telecommunications part of CIOE (China International Optoelectronic Exposition), 500 companies were exhibiting,” says Kozlov. “And with the trade barriers, there is an extra incentive for companies in the West to double down on what they have been doing and maybe new companies to be formed.”
Companies have concerns about buying stuff from overseas so local companies are getting more business.
“We are going to see more consolidation but also new vendors entering the market and competing with the bigger guys,” says Kozlov.

Preparing for a post-pluggable optical module world

Part 1: OIF: ELSFP, XSR+, and CEI-112G-Linear
The OIF is working on several electrical and optical specifications as the industry looks beyond pluggable optical transceivers.
One initiative is to specify the external laser source used for co-packaged optics, dubbed the External Laser Small Form Factor Pluggable (ELSFP) project.
Industry interest in co-packaged optics, combining an ASIC and optical chiplets in one package, is growing as it becomes increasingly challenging and costly to route high-speed electrical signals between a high-capacity Ethernet switch chip and the pluggable optics on the platform’s faceplate.
The OIF is also developing 112-gigabit electrical interfaces to address not just co-packaged optics but also near package optics and the interface needs of servers and graphics processor units (GPUs).
Near package optics also surrounds the ASIC with optical chiplets. But unlike co-packaged optics, the ASIC and chiplets are placed on a high-performance substrate located on the host board.
ELSFP
Data centre operators have vast experience using pluggables and controlling their operating environment so that they don’t overheat. The thermal management of optics co-packaged with an ASIC that can dissipate hundreds of watts is far trickier.
“Of all the components, the one that hates heat the most is the laser,” says Nathan Tracy, TE Connectivity and the OIF’s vice president of marketing.
Players such as Intel and Juniper have integrated laser technology, allowing them to place the full transceiver on a chip. However, the industry trend is to use an external light source so that the laser is decoupled from the remaining optical transceiver circuitry.
“We bring fibre into and out of the co-packaged optical transceiver so why not add a couple more fibres and bring the laser source into the transceiver as well?” says Tracy.
Two approaches are possible. One is to box the lasers and place them within the platform in a thermally-controlled environment. Alternatively, the lasers can be boxed and placed on the equipment’s faceplate, as pluggable optics are today.
“We know how to do that,” says Tracy. “But it is not a transceiver, it is a module full of lasers.”
Such a pluggable laser approach also addresses a concern of the data centre operators: how to service the optics of a co-packaged design.
The OIF’s ELSFP project is working to specify such a laser pluggable module: its mechanical form factor, electrical interface, how light will exit the module, and its thermal management.
The goal is to develop a laser pluggable that powers up when inserted and has a blind-mate optical interface, ensuring light reaches the co-packaged optics transceivers on the host board with minimal optical loss.
“Optical interfaces are fussy things,” says Tracy. Such interfaces must be well-aligned, clean, and hold tight tolerances, says Tracy: “That is all captured under the term blind-mate.”
Optical fibre will deliver light from the laser module to the co-packaged optics but multi-core fibre may be considered in future.
One issue the OIF is discussing is the acceptable laser output power. The higher the output power, the more the source can be split to feed more co-packaged optics transceivers. But higher-power lasers have eye-safety issues.
Another topic being addressed is the fibre density the form factor should enable. The OIF wants a roadmap to ensure that future co-packaged optics’ needs are also met.
“The industry can then take that specification and go compete in the market, adding their differentiation on top of the standardisation,” says Tracy.
The OIF’s ELSFP members have submitted technical contributions and a draft specification exists. “Now we are in the iterative process with members building on that draft,” says Tracy.
Co-packaged optics and near package optics
As the capacity of switch chips continues to double, more interfaces are needed to get data in and out and the harder it is becoming to route the channels between the chip and the optical modules.
The chip package size is also increasing with the growing aggregate bandwidth and channels, says Tracy. These channels come out via the package’s solder balls that connect to the host board.
“You don’t want to make that ASIC package any bigger than it needs to be; packages have bad parasitics,” says Tracy
For a fully co-packaged design, a switch ASIC is surrounded by 16 optical engines. For next-generation 51.2-terabit switch ASICs, 3.2 terabits-per-second (Tbps) optical engines will be required. Add the optical engines and the switch package becomes even bigger.
“You are starting to get to the point where you are making the package bigger in ways that are challenging the industry,” says Tracy.
Near package optics offers an alternative approach to avoid cramming the optics with the ASIC. Here, the ASIC and the chiplets are mounted on a high-performance substrate that sits on the host card.
“Now the optical engines are a little bit further away from the switching silicon than in the co-packaged optics’ case,” says Tracy.
CEI-112G-Extra Short Reach Plus (XSR+) electrical interface
According to optical I/O specialist, Ayar Labs, near package optics and co-packaged optics have similar optical performance given the optical engines are the same. Where they differ is the electrical interface requirements.
With co-packaged optics, the channel length between the ASIC and the optical engine is up to 50mm and the channel loss is 10dB. With near package optics, the channel length is up to 150mm and a 13dB channel loss.
The OIF’s 112Gbps XSR+ electrical interface is to meet the longer reach needs of near package optics.
“It enables a little bit more margin or electrical channel reach while being focused on power reduction,” says Tracy. “Co-packaged optics is all about power reduction; that is its value-add.”
CEI-112G-Linear
A third ongoing OIF project – the CEI-112-Linear project – also concerns a 112Gbps chip-to-optical engine interface.
The project’s goal is to specify a linear channel so that the chip’s electrical transmitter (serdes) can send data over the link – made up of an optical transmitter and an optical receiver as well as the electrical receiver at the far end – yet requires equalisation for the transmitter and end receiver only.
“A linear link means we understand the transition of the signal from electrical to optical to electrical,” says Tracy. “If we are operating over a linear range then equalisation is straightforward.” That means simpler processing for the signal’s recovery and an overall lower power consumption.
By standardising such a linear interface, multiple chip vendors will be able to drive the optics of multiple I/O chiplet companies.
“Everything is about power savings, and the way to get there is by optimising the link,” says Tracy.
224-gigabit electrical interfaces
The OIF’s next-generation 224Gbps electrical interface work continues to progress. Member input to date has tackled the challenges, opportunities and the technologies needed to double electrical interface speeds.
“We are surveying the playing field to understand where the really hard parts are,” says Tracy.
A White Paper is expected in the coming year that will capture how the industry views the issues and the possible solutions.
“If you have industry consensus then it is easier to start a project addressing the specific implementation to meet the problem,” says Tracy.
Nokia's 4.8-terabit FP5 packet-processing chipset

Part 1: IP routing: Nokia’s latest FP5 and router platforms
Nokia has unveiled its latest packet-processing silicon that will be the mainstay of its IP router platforms for years to come.
The FP5 chipset is rated at 4.8 terabits-per-second (Tbps), a twelvefold improvement in Nokia’s packet-processing silicon performance in a decade. (See chart.)

Communications service provider (CSP) BT says Nokia’s 7750 router platforms equipped with the FP5 chipset will deliver every use case it needs for its Multi Service Edge; from core routing, MPLS-VPN, broadband network gateways (BNG), to mobile backhaul and Ethernet.
The FP5 announcement comes four years after Nokia unveiled its existing flagship router chipset, the FP4. The FP4 was announced as a 2.4Tbps chipset but Nokia upgraded its packet-processing rating to 3Tbps.
“We announced what we knew but then, through subsequent development and testing, the performance ended up at 3Tbps,” says Heidi Adams, head of IP and optical networks marketing at Nokia.
The FP5 may also exceed its initial 4.8Tbps rating.
Nokia will use the FP5 to upgrade its existing platforms and power new router products; it will not license the chipset nor will it offer it for use in open router platforms.
Nokia’s chipset evolution
At the heart of Nokia’s router silicon is a 2D array of packet processing cores.
The FP3, announced in 2011 by Alcatel-Lucent (acquired by Nokia in 2016), used 288 packet processing cores arranged in a 32×9 array. Each row of cores acted as a packet-processing pipeline that could be partitioned to perform independent tasks. The array’s columns performed table look-ups and each column could be assigned several tasks.
Nokia didn’t detail how the FP4 upgraded the array of cores. But the performance enhancement was significant; the FP4 delivers a 7.5x improvement in packet processing performance compared to the FP3.
The 16nm CMOS FP4 chipset includes a traffic manager (q-chip), packet processor (p-chip), the t-chip that interfaces to the router fabric, and what was then a new chip, the e-chip.
The e-chip acts as a media access controller (MAC) that parcels data from the router’s client-side pluggable optical modules for the p-chip.
Nokia even designed memory for the FP4 whereby instructions can be implemented during memory access and the memory can be allocated to perform different types of look-up and buffering, depending on requirements.
To maximise the memory’s performance, Nokia used advanced packaging for the FP4’s p-chip and q-chip. The resulting 2.5D-packaged p-chip comprises the packet processor die and stacks of memory. The q-chip is also a multi-chip module containing RISC processors and buffering memory.
The FP4 uses 56Gbps PAM-4 serialiser-deserialiser (serdes) interfaces, technology that Nokia secured from Broadcom.
FP5’s features
The FP5 builds on the major architectural upgrade undertaken with the FP4.
Using a 7nm CMOS process technology, Nokia’s FP5 designers have combined on-chip what were two separate FP4 chips: the packet processor (p-chip) and traffic manager (q-chip).
The FP5 chipset consumes a quarter of the power of the FP4 in terms of watts-per-gigabit (0.1W/Gig for the FP5 compared to the FP4’s 0.4W/Gig).
Consolidating two chips into one accounts for part of the power savings. Using 112Gbps serdes and a more advanced CMOS process are other factors.
Nokia has also added encryption hardware blocks to the chip’s ports. The hardware blocks implement the MACsec algorithm and can also encrypt layer 2.5 and layer 3 traffic.
The chipset can handle packet flows as large as 1.6 terabits. “We don’t have any physical interfaces that support flows at that rate,” says Adams. “It’s an indicator that the chipset is ready for much more.”
The e-chip, which Nokia describes as a tremendously important device, has also been upgraded. As well as the MAC function, it acts as an early-stage packet processor, performing pre-processing and pre-classification tasks on the traffic.
The e-chip also performs pre-buffering for the packer processor. Using multiple such devices allows the line card to expand the forwarding limit of the FP5’s packet processor. This enables Nokia’s routers to perform what it calls intelligent aggregation (IA). “We can bring in more traffic, increase the number of ingress ports even if those ports start to get fully loaded, because of the chipset architecture being fully buffered,” says Adams. “The result is a 30 per cent uplift in the stated capacity numbers.”
The FP5 chipset has been taped out and the silicon is being tested in Nokia’s lab.
Router platforms
IP core routers are tasked with moving large amounts of IP traffic across a network backbone. IP edge routers, in contrast, typically aggregate a variety of services such as mobile transport, residential traffic or act as gateways.
The platforms that will use the FP5 are classified by Nokia as edge routers. “The boundaries have blurred,” says Adams. “It is more important to look at how applications are deployed and what the requirements are.”
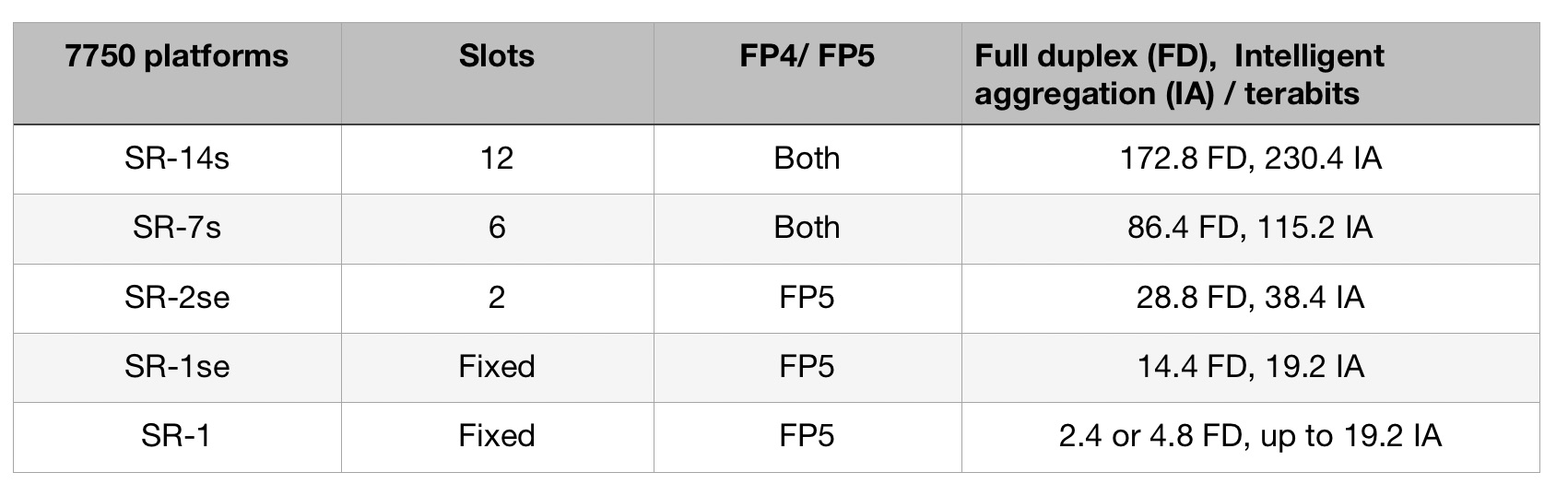
The platforms using the FP5 are the existing 7750 SR-14s and 7750-SR7s routers that were announced with the launch of the FP4.
These chassis were designed to accommodate Nokia’s current and next-generation router cards. “This allows operators to retain the same chassis and support a mix of FP4 and FP5 cards, growing into them gradually,” says Adams.
Nokia has announced three other platforms: two mid-range platforms, the 7750 SR2-se and the 7750 SR1-se, and the 7750 SR-1 that will be available in six variants. “They [the SR-1 boxes] are going to be available in a range of configurations and different port speeds,” says Adams.
Platforms using the FP5 chipset will ship in the first half of 2022, starting with the SR-1.
Nokia also announced an FP5 expandable media adaptor (XMA) line card for the non-fixed platforms (the 7750 SR-14s/ SR-7s and SR-2se). The card supports 36 pluggable slots and with 400 Gigabit Ethernet (GbE) has a capacity of 14.4Tbps full-duplex or 19.2Tbps in intelligent aggregation mode.
The card will also support 400ZR and ZR+ coherent modules and is ready for 800GbE pluggables that will double the card’s capacity ratings.
Nokia says the FP5 improves the throughput of the XMA card by a factor of three: Nokia’s 4.8Tbps XMA (12Tbps IA) uses four FP4 chipsets while the latest 14.4Tbps (19.2Tbps IA) XMA uses six FP5 chipsets.
Custom silicon versus disaggregated designs
Nokia says the benefits of having its own chipset justify the intellectual effort and development expense, even when advanced merchant silicon is available and certain CSPs are embracing open disaggregated routers.
“We feel there is a need in the industry for platforms based on this kind of technology,” says Adams.
What is important is the total cost of ownership and that Nokia’s systems are deployed in critical networks where resiliency, reliability, the feature set and network security are all critical, says Adams.
Nokia also points to the progress it has made since the launch of the FP4. “We have secured 350 projects, two-thirds of which were new footprints or competitive displacements,” says Adams. Nokia’s IP revenues in 2020 were $3.2 billion.
That said, Nokia also partners with merchant silicon vendors: the 7250 IXR interconnect router uses merchant silicon, for example.
“If I look at disaggregation, absolutely, it is an interesting area,” says Adams. “But I think it is very early days.”
Neil McRae, managing director and chief architect at BT, says that while some operators are looking at disaggregated software and hardware, BT doesn’t believe this is necessarily the best solution in terms of performance, reliability or cost.
“Increasingly, the ratio of capital investment in core networking is moving towards optical transceivers than router silicon,” says McRae. “But to get the most out of the network and the router, using custom silicon for the most demanding cases still delivers the best outcomes.
“In our live network but also in our testing, the integrated solution is more reliable, easier to operate and a significant improvement from a total cost of ownership point of view,” says McRae.
BT says it will be able to scale interfaces on the 7750 from 1-400Gbs using the FP5 and Nokia’s SR-OS routing networking software.
BT also highlights the importance of reliability under demand, pointing out how the CSP’s traffic has doubled during the pandemic without impacting its customers.
“Nokia’s understanding of how the underlying silicon is going to react in different situations gives them a significant advantage in building the software on top that performs in challenging situations,” says McRae.
Chip Strategy
Nokia says that were it to sell its FP5 silicon as a standalone product, it would enter a very different design environment.
“You are designing to the requirements of multiple customers versus designing for your systems,” says Adams.
Nokia’s belief is that there is strong demand for platforms designed to purpose.
“We are staying true to that strategy,” says Adams.
Microchip’s compact, low-power 1.6-terabit PHY

Microchip Technology’s latest physical layer (PHY) chip has been developed for next-generation line cards.
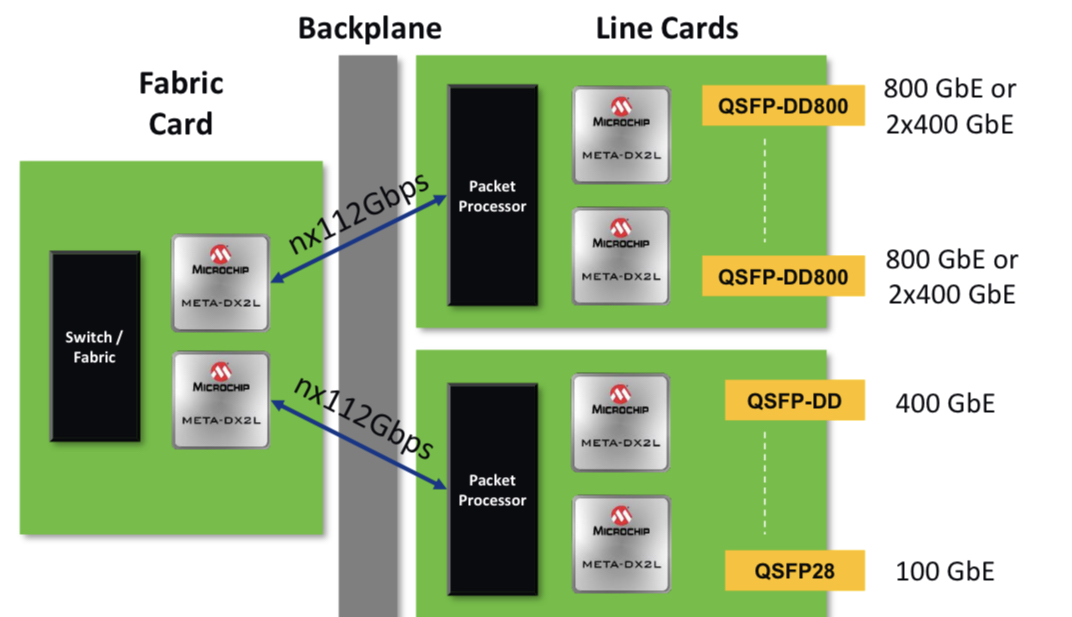
The PM6200 Meta-DX2L (the ‘L’ is for light) 1.6-terabit chip is implemented using TSMC’s 6nm CMOS process. It is Microchip’s first PHY to use 112-gigabit PAM-4 (4-level pulse-amplitude modulation) serialiser/ deserialisers (serdes) interfaces.
Microchip’s existing 16nm CMOS Meta-DX1 PHY devices are rated at 1.2 terabits and use 56-gigabit PAM-4 serdes.
System vendors developing line cards that double the capacity of their switch, router or transport systems are being challenged by space and power constraints, says Microchip. To this aim, the company has streamlined the Meta-DX2L to create a compact, lower-power chip.
“One of the things we have focussed on is the overall footprint of our [IC] design to ensure that people can realise their cards as they go to the 112-gigabit PAM-4 generation,” says Stephen Docking, manager, product marketing, communications business unit, at Microchip.
The company says the resulting package measures 23x30mm and reduces the power per port by 35 per cent compared to the Meta-DX1.
IC architecture
The Meta-DX1 family of 1.2-terabit physical layer (PHY) Ethernet chips effectively comprise three 400-gigabit cores and support the OIF’s Flexible Ethernet (FlexE) protocol and MACsec encryption.

The Meta-DX1 devices, launched in 2019, support the Precision Time Protocol (PTP) used to synchronise clocks across a network with high accuracy that is a requirement for 5G.
The new Meta-DX2L is a single chip although Microchip hints that other family devices will follow.
The Meta-DX2L can be viewed as comprising two 800-gigabit cores. The chip does away with FlexE and the PTP protocol but includes retiming and gearbox modes. The gearbox is used to translate between 28, 56 and 112-gigabit rates.
“We still see customers working on FlexE designs, so the lack of it [with the Meta-DX2L] is not due to limited market demand but how we chose to optimise the chip,” says Docking.
The same applies to PTP. The Meta-DX1 performs time stamping that meets 5G’s Class C and Class D front-haul clocking requirements. “The difference with the Meta-DX2L is that it is not doing time stamping,” says Docking. But it can work with devices doing the time stamping.
“In a 5G system, if you add a PHY, you need to do it in such a way that it doesn’t add any uncertainty in the overall latency of the system,” says Docking. ”So we have focussed on the device have a constant latency.” This means the Meta-DX2L can be used in systems meeting Class C or Class D clocking requirements.
The chip also features a 16×16 crosspoint switch that allows customers to use different types of optical modules and interface them to a line card’s ASIC or digital signal processor (DSP).
The Meta-DX2L’s two cores are flexible and support rates from 1 to 800 Gigabit Ethernet, says Docking.
As well as Ethernet rates, the device supports proprietary rates common with artificial intelligence (AI) and machine learning.
For AI, an array of graphic processor units (GPUs) talk to each other on the same line card. “But to scale the system, you have to have multiple line cards talk to each other,” says Docking. “Different companies that design GPUs have chosen their own protocols to optimise their communications.”
Such links are not aligned with the Ethernet rates but the Meta-DX2L supports these proprietary rates.
Microchip says the Meta-DX2L will sample this quarter.
1.6 terabits, system resilience and design challenges
The PHY’s 1.6-terabit capacity was chosen based on customers’ requirements.
“If you look at the number of ports people want to support, it is often an even multiple of 800-gigabit ports,” says Docking.
The Meta-DX2L, like its predecessor PHY family, has a hitless 2:1 multiplexer. The multiplexer function is suited for centralised switch platforms where the system intelligence resides on a central card while the connecting line cards are relatively simple, typically comprising PHYs and optical modules.
In such systems, due to the central role of the platform’s switch card, a spare card is included. Should the primary card fail, the backup card kicks in, whereby all the switch’s line cards connect to the backup. The 2:1 multiplexer in the PHY means each line card is interfaced to both switch cards: the primary one and backup.

For line cards that will have 32 or 36 QSFP-DD800 pluggable modules, space is a huge challenge, says Docking: “So having a compact PHY is important.”
“The physical form factor has always been a challenge and then density plays into it and thermal issues,” says Kevin So, associate director, product line management and marketing, communications business unit, at Microchip. “And when you overlay the complexity of the transition from 56 to 112 gigabits, that makes it extremely challenging for board designers.”
Applications
The 1.6-terabit PHY is aimed at switching and routing platforms, compact data centre interconnect systems, optical transport and AI designs.
Which application takes off first depends on several developments. On one side of the PHY chip sits the optics and on the other the ASIC, whether a packet processor, switch chip, processor or DSP. “It’s the timing of those pieces that drive what applications you will see first,” says So.
“Switching and packet processor chips are transitioning to 112-gigabit serdes and you are also starting to see QSFP-DD or OSFP optics with 112-gigabit serdes becoming available,” adds Docking. “So the ecosystem is starting for those types of systems.”
The device is also being aimed at routers for 5G backhaul applications. Here data rates are in the 10- to the 100-gigabit range. “But you are already starting to hear about 400-gigabit rates for some of these access backhaul routers,” says So.
And with 400 Gigabit Ethernet being introduced on access pizza-box routers for 5G this year, in two years, when Microchip’s customers release their hardware, there will likely be denser versions, says So.
“And by then we’ll be talking about a DX3, who knows?” quips So.

The future of optical I/O is more parallel links

Chris Cole has a lofty vantage point regarding how optical interfaces will likely evolve.
As well as being an adviser to the firm II-VI, Cole is Chair of the Continuous Wave-Wavelength Division Multiplexing (CW-WDM) multi-source agreement (MSA).
The CW-WDM MSA recently published its first specification document defining the wavelength grids for emerging applications that require eight, 16 or even 32 optical channels.
And if that wasn’t enough, Cole is also the Co-Chair of the OSFP MSA, which will standardise the OSFP-XD (XD standing for extra dense) 1.6-terabit pluggable form factor that will initially use 16, 100 gigabits-per-second (Gbps) electrical lanes. And when 200Gbps electrical input-output (I/O) technology is developed, OSFP-XD will become a 3.2-terabit module.
Directly interfacing with 100Gbps ASIC serialiser/ deserialiser (serdes) lanes means the 1.6-terabit module can support 51.2-terabit single rack unit (1RU) Ethernet switches without needing 200Gbps ASIC serdes required by eight-lane modules like the OSFP.
“You might argue that it [the OSFP-XD] is just postponing what the CW-WDM MSA is doing,” says Cole. “But I’d argue the opposite: if you fundamentally want to solve problems, you have to go parallel.”
CW-WDM specification
The CW-WDM MSA is tasked with specifying laser sources and the wavelength grids for use by higher wavelength count optical interfaces.
The lasers will operate in a subset of the O-band (1280nm-1320nm) building on work already done by the ITU-T and IEEE standards bodies for datacom optics.
In just over a year since its launch, the MSA has published Revision 1.0 of its technical specification document that defines the eight, 16 and 32 channels.
The importance of specifying the wavelengths is that lasers are the longest lead items, says Cole: “You have to qualify them, and it is expensive to develop more colors.”
In the last year, the MSA has confirmed there is indeed industry consensus regarding the wavelength grids chosen. The MSA has 11 promoter members that helped write the specification document and 35 observer status members.
“The aim was to get as many people on board as possible to make sure we are not doing something stupid,” says Cole.
As well as the wavelengths, the document addresses such issues as total power and wavelength accuracy.
Another issue raised is four-wavelength mixing. As the channel count increases, the wavelengths are spaced closer together. Four-wavelength mixing refers to an undesirable effect that impacts the link’s optical performance. It is a well-known effect in dense WDM transport systems where wavelengths are closely spaced but is less commonly encountered in datacom.
“The first standard is not a link budget specification, which would have included how much penalty you need to allocate, but we did flag the issue,” says Cole. “If we ever publish a link specification, it will include four-wavelength mixing penalty; it is one of those things that must be done correctly.”
Innovation
The MSA’s specification work is incomplete, and this is deliberate, says Cole.
“We are at the beginning of the technology, there are a lot of great ideas, but we are going to resist the temptation to write a complete standard,” he says.
Instead, the MSA will wait to see how the industry develops the technology and how the specification is used. Once there is greater clarity, more specification work will follow.
“It is a tricky balance,” says Cole. “If you don’t do enough, what is the value of it? But if you do too much, you inhibit innovation.”
“The key aspect of the MSA is to help drive compliance in an emerging market,” says Matt Sysak of Ayar Labs and editor of the MSA’s technical specification. “This is not yet standardised, so it is important to have a standard for any new technology, even if it is a loose one.”
The MSA wants to see what people build. “See which one of the grids gain traction,” says Sysak.
Ayar Labs’ SuperNova remote light source for co-packaged optics is one of the first products that is compliant with the CW-WDM MSA.
Sysak notes that at recent conferences co-packaged optics is a hot topic but what is evident is that it is more of a debate.
“The fact that the debate doesn’t seem to coagulate around particular specification definitions and industry standards is indicative of the fact that the entire industry is struggling here,” says Sysak.
This is why the CW-WDM MSA is important, to help promote economies of scale that will advance co-packaged optics.

Applications
Cole notes that, if anything, the industry has become more entrenched in the last year.
The Ethernet community is fixed on four-wavelength module designs. To be able to support such designs as module speeds increase, higher-order modulation schemes and more complex digital signal processors (DSPs) are needed.
“The problem right now is that all the money is going into signal processing: the analogue-to-digital converters and more powerful DSPs,” says Cole.
His belief is that parallelism is the right way to go, both in terms of more wavelengths and more fibers (physical channels).
“This won’t come from Ethernet but emerging applications like machine learning that are not tied to backward compatibility issues,” says Cole. “It is emerging applications that will drive innovation here.”
Cole adds that there is hyperscaler interest in optical channel parallelism. “There is absolutely a groundswell interest here,” says Cole. “This is not their main business right now, but they are looking at their long-term strategy.”
The likelihood is that laser companies will step in to develop the laser sources and then other companies will develop the communications gear.
“It will be driven by requirements of emerging applications,” says Cole. “This is where you will see the first deployments.”
First co-packaged optics switches set for next year
Ranovus says two of its lead customers will deploy co-packaged optics next year.
They will deploy 25.6-terabit Ethernet switch chips but these will be proof-of-concept designs rather than volume deployments.
The deployments will be used to assess the software and gain experience with their maintenance including replacing optics if needed.
“I do think 2024 is going to be the volume year,” says Hamid Arabzadeh, CEO of Ranovus, who expects to announce the customers before the year-end.
Disaggregated server untangles compute, memory and storage elements
Applications
Ranovus is focussed on the emerging integrated optical input-output (I/O) market for Ethernet switches and disaggregated server designs.
A disaggregated server untangles the compute, memory and storage elements found on a server card and pools them separately. This enables a CPU or compute node to access far more memory. It also means each of the server elements can be upgraded independently.
Pooling the memory suits artificial intelligence (AI)/ machine learning applications that process huge data sets. Such applications also require considerable computing.
For machine learning applications, graphic processing unit (GPU) chips are tightly coupled in clusters. But it is a challenge to continually grow the number of GPUs in a cluster and support inter-cluster communications using eletrical interfaces.
Data centre operators want processing performance that scales linearly as more GPUs are adding to a cluster and more clusters are used. This requires longer-reach, high-bandwidth, low-latency links. Limiting the power consumption of such links is also key.
Such system design challenges explain the industry’s interest in adding optical I/O to high-end processors like GPUs. The same applies to Ethernet switch-chips that are doubling in capacity every two years. Moving from electrical to optical interfaces promises longer, energy efficient (measured in pJ/bit), low-latency links.
For Ethernet switch designs, the optical I/O end-point bandwidth needed is at least 3.2 terabits per second (Tbps), says Arabzadeh, whereas for AI it is 0.5-1Tbps.
Odin optical engine
Ranovus recently expanded its optical interconnect portfolio by developing an Odin design that doesn’t need an accompanying retimer chip.
The optical engine combines CMOS and silicon photonics circuits in a monolithic chip, resulting in a smaller, cheaper and power-efficient design.
This second-generation Odin means Ranovus can now offer digital and analogue drive options for co-packaged optics and address more cost-conscious applications such as chip interconnect in servers.
Arabzadeh says its first Odin design that uses a retimer chip helped secure its lead customers.
“We have two lead customers where we are doing the co-packaging of their [switch] chips operating at 100-gigabit PAM-4,” he says. “And we also have an AI customer, where their chip talks PCI Express 5.0 (PCIe 5.0) to our Odin.”
Ranovus first unveiled its Odin-8 800-gigabit design at OFC 2020 and demonstrated it sending eight 100 gigabit PAM-4 (4-level pulse-amplitude modulation) signals, each on a separate fibre.
The design includes a digital retimer IC which takes the OIF-standard extra short reach (XSR) signal – for example, from a switch chip – and recreates (retimes) the PAM-4 signal before forwarding it to Ranovus’ chip. Such a configuration is referred to as a digital-drive design.

“This retimer is not a chip we do and it is expensive,” says Arabzadeh. “It also consumes half the power of the [Odin] chiplet design.”
Ranovus also detailed over a year ago its Odin-32 design that supports four wavelengths per fibre for a total bandwidth of 3.2Tbps.
Since then, Ranovus has developed its Odin-8 for use in an 800-gigabit DR8 optical module. The module will sample and be in the hands of customers for testing in the coming quarter.
The Odin-based 800G-DR8 optical module has a power consumption of 13W; 4W less than rival designs, says Arabzadeh, adding that the optical engine is cost-effective at 400 gigabits, even when using half its capacity.
ODIN version 2.0
The latest monolithic chip is an analogue-drive design. It features radio frequency (RF) drivers, trans-impedance amplifiers (TIAs), silicon photonics transmitters and receivers, and control logic to oversee the components.
The chip does away with clock data recovery (CDR) while integrating the TIAs on-chip. This reduces system costs. “We have the first TIA at 100 gigabits in CMOS,” says Arabzadeh.
To work without the retimer, the monolithic chip is placed much closer to the driving ASIC, with both sharing a common substrate. “It works because it is parked right next to the other chip,” says Arabzadeh.
Ranovus uses a software model of a vendor’s ASIC’s serialiser/ deserialiser (serdes) to ensure the serdes will drive its analogue input.
Being an analogue drive, it is bit-rate and protocol agnostic. “This allows us to get customers beyond the Ethernet market,” says Arabzadeh. These include 100-gigabit PAM-4 signals and the PCIe 5.0 protocol, as mentioned.
For machine learning applications, a proprietary protocol can be used between the end points. NVLink, a serial multi-lane communications link developed by Nvidia, is one such protocol.
Arabzadeh says Ranovus has achieved 1 terabit-per-mm in pitch interface densities: “The stuff we have got involved in with folks in machine learning and AI dwarfs the Ethernet market.”
Laser source
Ranovus’ co-packaged designs use an external laser source. But the company has patented technlogy that allows lasers to be attached directly to the monolithic chip.
This is done at the wafer level, before slicing a wafer to its constituent die. As a result, Ranovus now has two Odin-8 optical engines, one that uses an external laser source (Odin-8ELS) and one with integrated lasers (Odin-8IL)
The laser-attach technology suits optical module designs and expands the company’s optical interconnect toolkit.
The industry has yet to decide whether to adopt a digital or analogue drive approach for co-packaged optics, but the latest Odin design means Ranovus can do both.
Packaging
The company has also been addressing the tricky issue of packaging the chip. “The packaging is a very difficult challenge,” says Arabzadeh.
Ranovus has used the Odin-8 to verify its packaging approach. Two sets of eight fibres are required for the optical I/O (a set to send and a set to receive) and four more fibres are used for the external laser source.
The Odin-32 will use the same packaging and fibre count. What will change is the chip that will support four wavelengths per fibre; instead of the single ring resonator modulator per output, four will be used.
Arabzadeh says each ring modulator is 25 micron so using one or four per path has little impact on the chip’s area.
Market development
Ranovus is addressing both the co-packaged optics and module designs with its Odin designs.
At the OFC conference and exhibition this summer, Arista Networks outlined how pluggable optics will be able to address 102.4 terabit Ethernet switches while Microsoft said it expects to deploy co-packaged optics by the second half of 2024.
Because of the uncertainty as to when co-packaged optics will take off, Ranovus will also supply its optics for the 400-gigabit and 800-gigabit pluggable module market.
“That is why we have yet to tape out the Odin-32,” he says. “We didn’t want to have the technology and there is nobody on the other side of it.”
But the key is to have an optical interface portfolio that secures designs early.
“If you can get the wins and through that, modify your chip, then you are designed in,” says Arabzadeh.

ADTRAN-ADVA's metro-access play

ADTRAN and ADVA have agreed to merge after a long courtship.
The two CEOs have spoken regularly over the years but several developments spurred them to act.
The merger combines ADTRAN’s expertise in access technologies with ADVA’s metro wavelength-division multiplexing (WDM) know-how to create a ‘metro-core-to-door’ company with revenues of $1.2 billion.
ADTRAN and ADVA a better path forward together than separately
As such, the merger promises to double their size and networking skills. Yet the stock market appeared underwhelmed by the announcement, with ADTRAN’s shares down 16% for the rest of the week after the deal was announced.
Market research analysts, however, are more upbeat.
“ADTRAN and ADVA have a better path forward together than separately,” said John Lively, principal analyst at LightCounting Market Research, in a research note.
The deal is expected to close in the second or third quarter of 2022 but only after several hurdles are overcome in what is described as a complex deal.
Motivation
The two companies describe the merger as a logical outcome given recent developments in the marketplace.
“Our combination will make us one of the largest Western suppliers for the markets we serve,” said Tom Stanton, CEO and chairman of ADTRAN, on the call announcing the deal. The word “Western” is noteworthy, reflecting how geopolitics is one catalyst motivating the merger.
The deal will also reposition the two companies with their rivals. ADTRAN will distance itself from broadband competitors such as Calix while ADVA will diversify its business from its current larger competitors, Ciena and Infinera. The new company’s revenues will also approach those of the two players.
The product portfolios of ADTRAN and ADVA have almost no overlap. ADTRAN offers fibre access and connectivity solutions while ADVA addresses metro WDM, data centre interconnect, business Ethernet, network synchronisation and network functions virtualisation (NFV) expertise.
Once combined, each company will seek to expand its sales in the other’s main market.
The US accounts for 74 per cent of ADTRAN’s revenues, while Europe accounts for 21 per cent. Meanwhile, Europe accounts for 62 per cent of ADVA’s business while the US is 29 per cent. The remaining revenues come from the Asia Pacific: ADTRAN, 5 per cent, and ADVA, 9 per cent.
Also cited as a factor is the wave of investment in fibre, not just by communications service providers (CSPs) and public utilities but also government-backed stimulus plans in the US and Europe.
In the US, $66 billion in investment was mentioned spread across programmes such as the infrastructure bill, the second phase of the Rural Digital Opportunity Fund (RDOF), and state-level funding for high-speed broadband.
In Europe, the sum is similar: $35 billion in government funding for high-speed broadband in the European Union, and $30 billion in public and private funding for fibre builds in the UK alone.
“There is an ongoing global fibre investment opportunity that we believe will create sustained momentum for years to come,” said Stanton.
Moreover, having access and second-mile technologies, the new company can better win business. “There is not a customer that we sell to today that, when they are upgrading their access infrastructure, is not also upgrading their middle-mile,” said Stanton.
Becoming a larger player will help, he said: “We see our customers making a significant capital investment to transition their supply chain to trusted vendors.”

Another merger catalyst is the opportunity created by US and European service providers that no longer use Chinese vendors and in some cases are replacing equipment already deployed.
In the US, this is less of an issue due to the fewer deployments while in Europe the process started 18 months ago. Stanton expects Latin America to follow.
“The market opportunity is not just created by all the stimulus but it is also because of the displacement of Eastern vendors,” said Stanton.
There is a land grab going on, he says, and the company that gets there first wins.
“Once you get entrenched in a carrier, regardless of size – the larger ones tend to have two [vendors] and the smaller ones, one – once you are entrenched, it is very difficult to get pulled out,” said Stanton.
Analysis
LightCounting’s view of the merger is positive.
Lively says the merger will not reshape the optical networking industry but it will be attractive to Tier 2 and Tier 3 CSPs that want to buy access and aggregation equipment from a single supplier.
LightCounting notes that the deal values ADVA at $931 million, 1.3x its most recent four quarters of sales.
This is a relatively low valuation: the 2015 Infinera-Transmode merger was 2.6x while the Cisco-Acacia Communications deal, which closed earlier this year, was 7.7x. Of recent deals, only the 2020 Ribbon-ECI Telecom deal was lower, at 1.2x.
LightCounting says one reason for the lower valuation could be ADVA’s port shipments; the vendor is one of the smallest dense WDM suppliers.
The merger’s impact will mostly be felt by the competitors of the existing two companies, says Lively. The new ADTRAN’s sales will be 20 per cent greater than Infinera but still a third of the size of Fiberhome and Ciena.

The importance of size is something both companies stress.
“Our industry has been consolidating and there is an underlying notion that scale matters,” says Stephan Rettenberger, senior vice president, marketing and investor relations at ADVA.
Doubling in size, the new company will be in the same bracket as Infinera while Ciena will be about 3x its size, notes Rettenberger: “The companies that we used to worry about the most are not as distant as before.”
At first glance, the merger between a US and an European company raises questions about the integration challenge. But both firms have American CEOs and both have operations in the US and Germany.
ADTRAN acquired Nokia Siemens Networks’ fixed-line broadband access unit in 2011 while ADVA more recently acquired US firms, MRV Communications and Overture.

Brian Protiva, CEO of ADVA and a co-founder of the company in 1994, is the longest-serving CEO in the optical industry. As such he will have thought long and hard about the deal.
“This business combination is not only about growing the business,” says Protiva. “These two businesses fit perfectly together to address existing market and technology requirements, and we are well-positioned to lead the transition to access and edge convergence.”
Service providers do not need separate infrastructure for business services, residential broadband, and/ or 5G xHauling, he says.
Mechanics
The proposed deal is an all-stock one with ADTRAN and ADVA combining to form ADTRAN Holdings.
Each ADVA share will be swapped for 0.8244 shares of the new company while ADTRAN shares will be exchanged on a one-for-one basis. ADTRAN shareholders will own 54 per cent of the combined company while ADVA shareholders will own 46 per cent, assuming all of the ADVA shares are swapped.
But the new holding company must first be approved by German regulators, expected to occur by November. A three-month offer period then starts during which a minimum of 70 per cent of ADVA shares must be surrendered.
Stanton will continue as CEO and chairman at the new company while ADVA’s Protiva will join as executive vice chairman.
“I’m convinced that Tom is the right person to run the combined company,” says Protiva. “He executes to plan, is well-liked by customers, and thinks very similarly to our ADVA leadership around people first and the customer experience.” Stanton is also a long-serving CEO, heading ADTRAN since 2005.
Protiva will support Stanton during the integration period and then be involved in the corporate strategic direction of ADTRAN, as a board member, using his many long-term relationships in the combined markets.
After that, Protiva says he may return to Egora, a holding company out of which ADVA was born.
ADVA’s CTO, Christoph Glingener, will retain his role with the new company. ADTRAN and ADVA will have a combined annual R&D budget of $250 million.
”The stock exchange offer needs to pass all types of regulatory groups and needs to be accepted by the ADTRAN and ADVA shareholders,” stresses Rettenberger. “There is still a long path to closing.”