
Xilinx delivers 58G serdes and showcases a 112G test chip
In the first of two articles, electrical input-output developments are discussed, focussing on Xilinx’s serialiser-deserialiser (serdes) work for its programmable logic chips. In Part 2, the Imec nanoelectronics R&D centre’s latest silicon photonics work to enable optical I/O for chips is detailed.
Part 1: Electrical I/O
Processor and memory chips continue to scale exponentially. The electrical input-output (I/O) used to move data on and off such chips scales less well. Electrical interfaces are now transitioning from 28 gigabit-per-second (Gbps) to 56Gbps and work is already advanced to double the rate again to 112Gbps. But the question as to when electrical interfaces will reach their practical limit continues to be debated.
 Gilles Garcia“Some two years ago, talking to the serdes community, they were seeing 100 gigabits as the first potential wall,” says Gilles Garcia, communications business lead at Xilinx. “In two years, a lot of work has happened and we can now demonstrate 112 gigabits [electrical interfaces].”
Gilles Garcia“Some two years ago, talking to the serdes community, they were seeing 100 gigabits as the first potential wall,” says Gilles Garcia, communications business lead at Xilinx. “In two years, a lot of work has happened and we can now demonstrate 112 gigabits [electrical interfaces].”
The challenge of moving to higher-speed serdes is that the reach shortens with each doubling of speed. The need to move greater amounts of data on- and off-chip also has power-consumption implications, especially with the extra circuitry needed when moving from non-return-to-zero signalling to the more complex 4-level pulse-amplitude modulation (PAM-4) signalling scheme.
PAM-4 is already used for 56-gigabit electrical I/O for such applications as 400 Gigabit Ethernet optical modules and leading edge 12.8-terabit switch chips. Having 112-gigabit serdes at least ensures one further generation of switch chips and optical modules but what comes after that is still to be determined. Even if more can be squeezed out of copper, the trace lengths will shorten and optics will continue to get closer to the chip.
58-gigabit serdes
Xilinx announced in March its first two Virtex Ultrascale+ FPGAs that will feature 58Gbps serdes. The company also demonstrated the technology at the OFC show. “No one else on the show floor had the same [58G serdes] capabilities in terms of bit error rate, noise floor, the demonstration across backplane technology, and transmitting and receiving data simultaneously,” says Garcia.
The two FPGAs are the VU27P that features 32 of the 58Gbps serdes as well as 32, 33Gbps serdes, while the second device, the VU29P, has 48, 58Gbps serdes as well as 32, 33Gbps ones. Both FPGA devices will ship by the year-end, says Xilinx. Moreover, customers have already used Xilinx’s 58Gbps test chip to validate its working over their systems’ backplanes in preparation for the arrival of the FPGAs.
No one else on the show floor had the same [58G serdes] capabilities in terms of bit error rate, noise floor, the demonstration across backplane technology, and transmitting and receiving data simultaneously
The Ultrascale+ FPGAs are constructed using several dice attached to a single silicon interposer to form a 2.5D chip design, what Xilinx calls its stacked silicon interconnect technology. The 58Gbps serdes are integrated into each FPGA slice. “Consider each slice as a monolithic implementation,” says Garcia.
 Source: Xilinx.
Source: Xilinx.
The two FPGAs with 58Gbps serdes are suited for such telecom applications as next-generation router and packet optical line cards that will use 200-gigabit and 400-gigabit client-side optical modules. The VU29P with its 48, 58Gbps serdes will be able to support line cards with up to six QSFP-DD or OSPF 400 Gigabit Ethernet modules (see the diagram of an example line card).
112-gigabit test chip
Xilinx also showcased its 112Gbps serdes test chip at the OFC show in March. “What we showed was it operating in full duplex mode - transmitting and receiving - running on the same board as the 58-gigabit serdes,” says Garcia. “The point being the 112-gigabit demo worked on a printed circuit board not designed for a 112-gigabit serdes.”
Xilinx stresses that the 112-gigabit serdes will appear on its next generation of FPGA devices implemented using a 7nm CMOS process. “It [the FPGA portfolio] will coincide with when the market needs 112 gigabits,” he says.
One obvious market indicator will be the emergence of optical modules that use electrical lanes operating at 112 gigabits. “The holy grail of optical modules is to use four [electrical] lanes for 400 gigabits,” says Garcia. The IEEE is working on such a specification and the work is expected to be completed at the end of 2019. Optical module vendors will likely have first samples in 2020. Then there is the separate timeline associated with next-generation 25.6-terabit switch chips.
“You need to have the full ecosystem before customers really implement 112Gbps serdes,” says Garcia.
ONF advances its vision for the network edge
The Open Networking Foundation’s (ONF) goal to create software-driven architectures for the network edge has advanced with the announcement of its first reference designs.
In March, eight leading service providers within the ONF - AT&T, Comcast, China Unicom, Deutsche Telekom, Google, NTT Group, Telefonica and Turk Telekom - published their strategic plan whereby they would take a hands-on approach to the design of their networks after becoming frustrated with what they perceived as foot-dragging by the systems vendors.
 Timon SloaneThree months on, the service providers have initial drafts of the the first four reference designs: a broadband access architecture, a spine-leaf switch for network functions virtualisation (NFV), a more general networking fabric that uses the P4 packet forwarding programming language, and the open disaggregated transport network (ODTN).
Timon SloaneThree months on, the service providers have initial drafts of the the first four reference designs: a broadband access architecture, a spine-leaf switch for network functions virtualisation (NFV), a more general networking fabric that uses the P4 packet forwarding programming language, and the open disaggregated transport network (ODTN).
The ONF also announced four system vendors - Adtran, Dell EMC, Edgecore Networks, and Juniper Networks - have joined to work with the operators on the reference design programmes.
“We are disaggregating the supply chain as well as disaggregating the technology,” says Timon Sloane, the ONF’s vice president of marketing and ecosystem. “It used to be that you’d buy a complete solution from one vendor. Now operators want to buy individual pieces and put them together, or pay somebody to do it for them.”
We are disaggregating the supply chain as well as disaggregating the technology
CORD and Exemplars
The ONF is known for various open-source initiatives such as its ONOS software-defined networking (SDN) controller and CORD. CORD is the ONF’s cloud optimised remote data centre work, also known as the central office re-architected as a data centre. That said, the ONF points out that CORD can be used in places other than the central office.
“CORD is a hardware architecture but it is really about software,” says Sloane. “It is a landscape of all our different software projects.”
However, the ONF received feedback last year that service providers were putting the CORD elements together slightly differently. “Vendors were using that as an excuse to say that CORD was too complicated and that there was no critical mass: ‘We don’t know how every operator is going to do this and so we are not going to do anything’,” says Sloane.
It led to the ONF’s service providers agreeing to define the assemblies of common components for various network platforms so that vendors would know what the operators want and intend to deploy. The result is the reference designs.
The reference designs offer operators some flexibility in terms of the components they can use. The components may be from the ONF but need not be; they can also be open-source or a vendor’s own solution.
 Source: ONF
Source: ONF
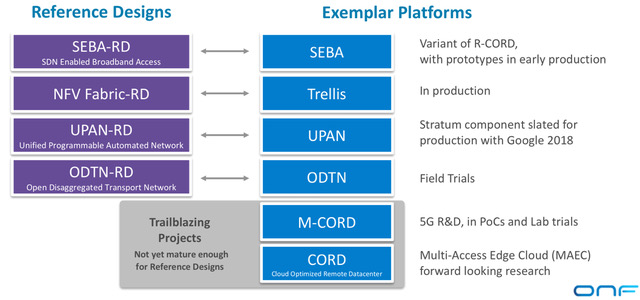
The ONF has also announced the exemplar platforms aligned with the reference designs (see diagram). An exemplar platform is an assembly of open-source components that builds an example platform based on a reference design. “The exemplar platforms are the open source projects that pull all the pieces together,” says Sloane. “They are easy to download, trial and deploy.”
The ONF admits that it is much more experienced with open source projects and exemplar platforms that it is with reference designs. The operators are adopting an iterative process involving all three - open source components, exemplar designs and reference designs - before settling on the solutions that will lead to deployments.
Two of the ONF exemplar platforms announced are new: the SDN-enabled broadband access (SEBA) and the universal programmable automated network (UPAN).
Reference designs
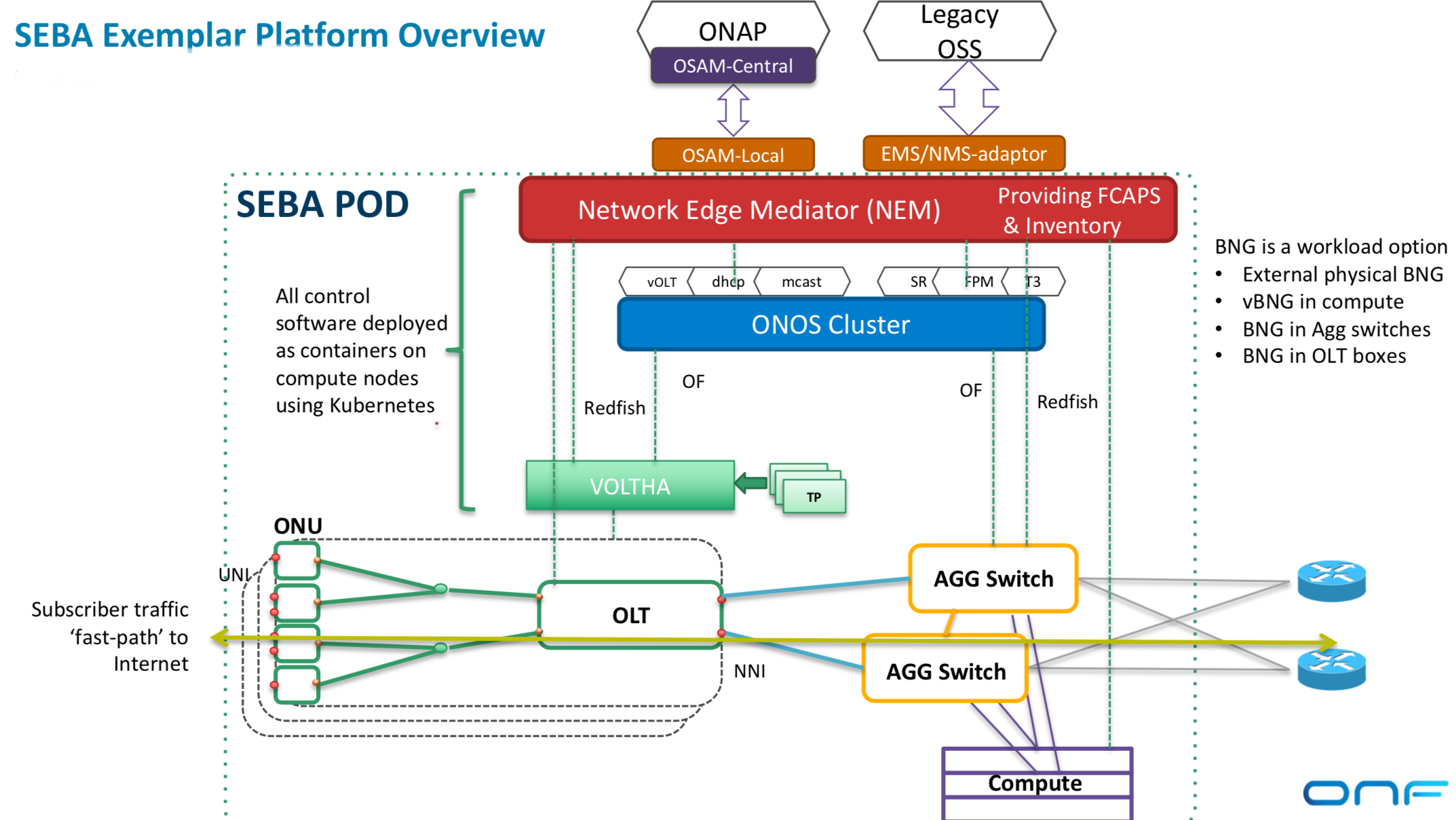
The SEBA reference design is a broadband variant of the ONF’s CORD work and addresses residential and backhauling applications. The design uses Kubernetes, the cloud-native orchestration system that automates the deployment, scaling and management of container-based applications, while the use of the OpenStack platform is optional. “OpenStack is only used if you want to support a virtual machine-based virtual network function,” says Sloane.
 Source: ONF
Source: ONF
SEBA uses VOLTHA, the open-source virtual passive optical networking (PON) optical line terminal (OLT) developed by AT&T and contributed to the ONF, and provides interfaces to both legacy operational support systems (OSS) and the Linux Foundation’s Open Networking Automation Platform (ONAP).
SEBA also features FCAPS and mediation. FCAPS is an established telecom capability for network management that can identify faults while the mediation presents information from FCAPS in a way the OSS understands.
“In its slimmest implementation, SEBA doesn’t need CORD switches, just a pair of aggregation switches,” says Sloane. The architecture can place sophisticated forwarding rules onto the optical line terminal and the aggregation switches such that servers and OpenStack are not required. “That has tremendous performance and scale implications,” says Sloane. “No other NFV architecture does this kind of thing.”
The second reference design - the NFV Fabric - ties together two ONF projects - Trellis and ONOS - to create a spine-leaf data centre fabric for edge services and applications.
The two remaining reference designs are UPAN and ODTN.
UPAN can be viewed as an extension of the NFV fabric that adds the P4 data plane programming language. P4 brings programmability to the data plane while the SDN controller enables developers to specify particular forwarding behaviour. “The controller can pull in P4 programs and do intelligent things with them,” says Sloane. “This is a new world where you can write custom apps that will push intelligence into the switch.”
Meanwhile, the ODTN reference design is used to add optical capabilities including reconfigurable optical add-drop multiplexers (ROADMs) and wide-area-network support.
There are also what the ONF calls two trailblazer projects - Mobile CORD (M-CORD) and CORD - that are not ready to become reference designs as they depend on 5G developments that are still taking place.
CORD represents the ONF’s unifying project that brings all the various elements together to address multi-access edge cloud. Also included as part of CORD is an edge cloud services platform. “This is the ultimate vision: what is the app store for edge applications?” says Sloane. “If you write a latency-sensitive application for eyeglasses, for example, how does that get deployed across multiple operators and multiple geographies?”
The ONF says it has already achieved a ‘critical mass’ of vendors to work on the development of the reference designs three months after announcing its strategic plan. The supply chain for each of the reference designs is shown in the table.
 Source: ONF
Source: ONF
“We boldly stated that we were going to reconstitute the supply chain as part of this work and bring in partners more aligned to embrace enthusiastically open source and help this ecosystem form and thrive,” says Sloane. “It is a whole new approach and to be able to rally the ecosystem in a short timeframe is notable.”
Our expectation is that at least two of these reference designs will go through this transition this year. This is not a multi-year process.
Next steps
It is the partner operators that are involved in the development of the reference designs. For example, the partners working on ODTN are China Unicom, Comcast and NTT. Once the reference designs are ready, they will be released to ONF members and then publicly.
However, the ONF has yet to give timescales as to when that will happen. “Our expectation is that at least two of these reference designs will go through this transition this year,” says Sloane. “This is not a multi-year process.”
Optical module trends: A conversation with Finisar
Finisar demonstrated recently a raft of new products that address emerging optical module developments. These include:
- A compact coherent integrated tunable transmitter and receiver assembly
- 400GBASE-FR8 and -LR8 QSFP-DD pluggable modules and a QSFP-DD active optical cable
- A QSFP28 100-gigabit serial FR interface
- 50-gigabit SFP56 SR and LR modules
Rafik Ward, Finisar’s general manager of optical interconnects, explains the technologies and their uses.
Compact coherent
Finisar is sampling a compact integrated assembly that supports 100-gigabit and 200-gigabit coherent transmission.
The integrated tunable transmitter and receiver assembly (ITTRA), to give it its full title, includes the optics and electronics needed for an analogue coherent optics interface.
The 32-gigabaud ITTRA includes a tunable laser, optical amplifier, modulators, modulator drivers, coherent mixers, a photo-detector array and the accompanying trans-impedance amplifiers, all within a gold box. “An entire analogue coherent module in a footprint that is 70 percent smaller than the size of a CFP2 module,” says Ward. The ITTRA's power consumption is below 7.5W.
 Rafik WardFinisar says the ITTRA is smaller than the equivalent integrated coherent transmitter-receiver optical sub-assembly (IC-TROSA) design being developed by the Optical Internetworking Forum (OIF).
Rafik WardFinisar says the ITTRA is smaller than the equivalent integrated coherent transmitter-receiver optical sub-assembly (IC-TROSA) design being developed by the Optical Internetworking Forum (OIF).
“We potentially could take this device and enable it to work in that [IC-TROSA] footprint,” says Ward.
Using the ITTRA enables higher-density coherent line cards and frees up space within an optical module for the coherent digital signal processor (DSP) for a CFP2 Digital Coherent Optics (CFP2-DCO) design.
Ward says the CFP2 is a candidate for a 400-gigabit coherent pluggable module along with the QSFP-DD and OSFP form factors. “All have their pros and cons based on such fundamental things as the size of the form factor and power dissipation,” says Ward.
But given coherent DSPs implemented in 7nm CMOS required for 400 gigabit are not yet available, the 100 and 200-gigabit CFP2 remains the module of choice for coherent pluggable interfaces.
 The demonstration of the ITTRA implementing a 200-gigabit link using 16-QAM at OFC 2018. Source: Finisar
The demonstration of the ITTRA implementing a 200-gigabit link using 16-QAM at OFC 2018. Source: Finisar
400 gigabits
Finisar also demonstrated its first 400-gigabit QSFP-DD pluggable module products based on the IEEE standards: the 2km 400GBASE-FR8 and the 10km 400GBASE-LR8. The company also unveiled a QSFP-DD active optical cable to link equipment up to 70m apart.
The two QSFP-DD pluggable modules use eight 50-gigabit PAM-4 electrical signal inputs that are modulated onto eight lasers whose outputs are multiplexed and sent over a single fibre. Finisar chose to implement the IEEE standards as its first QSFP-DD products as they are low-power and lower risk 400-gigabit solutions.
The alternative 2km 400-gigabit design, developed by the 100 Lambda MSA, is the 400G-FR4 that uses four 100-gigabit optical lanes. “This has some risk elements to it such as the [PAM-4] DSP and making 100-gigabit serial lambdas work,” says Ward. “We think the -LR8 and -FR8 are complementary and could enable a fast time-to-market for people looking at these kinds of interfaces.”
The QSFP-DD active optical cable may have a reach of 70m but typical connections are 20m. Finisar uses its VCSEL technology to implement the 400-gigabit interface. At the OFC show in March, Finisar demonstrated the cable working with a Cisco high-density port count 1 rack-unit switch.
I sometimes get asked by customers what is the best way to get to higher-density 100 gigabit. I point to the 400-gigabit DR4.
QSFP28 FR
Finisar also showed it 2km QSFP28 optical module with a single wavelength 100-gigabit PAM-4 output. The QSFP28 FR takes four 25 gigabit-per-second electrical interfaces and passes them through a gearbox chip to form a 50-gigabaud PAM-4 signal that is used to modulate the laser.
The QSFP28 FR is expected to eventually replace the CWDM4 that uses four 25-gigabit wavelengths multiplexed onto a single fibre. “The end-game is to get a 100-gigabit serial module,” says Ward. “This module represents the first generation of that.”
Finisar is also planning a 500m QSFP28 DR. The QSFP28 DR and FR will work with the 500m IEEE 400GBASE-DR4 that has four outputs, each a fibre carrying a 100-gigabit PAM-4 signal, with the -DR4 outputs interfacing with up to four FR or DR modules.
“I sometimes get asked by customers what is the best way to get to higher-density 100 gigabit,” says Ward. “I point to the 400 gigabit DR4, even though we call it a 400-gigabit part, it is also a 4x100-gigabit DR solution.”
Ward says that the 500m reach of the DR is sufficient for the vast majority of links in the data centre.
SFP56 SR and LR
Finisar has also demonstrated two SFP56 modules: a short reach (SR) version that has a reach of 100m over OM4 multi-mode fibre and the 10km LR single-mode interface. The SR is VSCEL-based while the LR uses a directly-modulated distributed feedback laser.
The SFP is deployed widely at speeds up to and including 10 gigabits while the 25-gigabit SFP shipments are starting to ramp. The SFP56 is the next-generation SFP module with a 50-gigabit electrical input and a 50-gigabit PAM-4 optical output.
The SFP56 will be used for several applications, says Finisar. These include linking servers to switches, connecting switches in enterprise applications, and 5G wireless applications.
Finisar says its 50 and 100 gigabit-per-lane products will likely be released throughout 2019, in line with the industry. “The 8-channel devices will likely come out at least a few quarters before the 4-channel devices,” says Ward.
Juniper bolsters its MX routers with packet processing ASIC
Juniper Networks has developed its next-generation packet processor, a single-chip package that includes 3D-stacked high-bandwidth memory. The device’s first use will be to enhance three of Juniper’s flagship MX series edge routers.
The company has also announced software for the 5G cellular standard that separates the control and user planes, known as CUPS, and two new MX-series platforms that will use the company’s universal chassis.

The company’s MX series edge routers were first introduced in 2007. “The MX is a platform that is at the heart of our service provider customers globally, as well as a number of our cloud provider and enterprise customers,” says Sally Bament, Juniper’s vice president of service provider marketing (pictured).
The latest enhancements will provide the MX edge router customers with another decade of support to meet their evolving service requirements, says Bament.
 Source: Gazettabyte, Juniper Networks
Source: Gazettabyte, Juniper Networks
Penta silicon
Juniper’s latest single-chip packet processor has a 500 gigabit-per-second (Gbps) duplex throughput and is implemented using a 16nm CMOS process. This compares to Juniper’s existing 120Gbps duplex 65nm CMOS Trio packet processor that is a four-device chipset that powers the MX platforms and was unveiled in 2009. The single packaged chip with its 3D-stacked memory reduces packaging by 83 per cent compared to the four-chip Trio chipset.
The Penta is being readied for the advent of 400–gigabit client-side interfaces and features 50Gbps serialiser/ deserialisers (serdes).
Juniper will use the Penta Silicon on its latest MPC10E linecard that has a capacity of 1.5 terabit-per-second (Tbps). The linecard will be used to enhance its MX240, MX480 and MX960 edge routers. The current MPC7E linecard, powered by the Trio, has a 480Gbps capacity.
 The MPC10E linecard showing the client interface options and the three Penta ICs. Source: Juniper Networks
The MPC10E linecard showing the client interface options and the three Penta ICs. Source: Juniper Networks
The company highlights the Penta programmability, enabling it to accommodate new emerging routing protocols.
The custom chip is also the first with hardware acceleration for Layer 2 MACsec and Layer 3 IPsec encryption protocols, claims Juniper.
“The benefit [of hardware acceleration] is that you don’t have to trade off encryption with processing performance and scale,” says Bament. “We can terminate thousands of IPSec sessions without any performance impact.”
The Penta also supports the FlexEthernet standard.
CUPS
Juniper claims it is the first vendor to implement CUPS, developed by the 3GPP standards body.
CUPS stands for Control and User Plane Separation of Evolved Packet Core (EPC) nodes. “By decoupling the control and user planes, you can scale them independently,” says Bament.
Such a separation brings several benefits. CUPS can be used to reduce latency by moving user plane nodes closer to the radio access network. Low latency is required to enable emerging network edge applications such as self-driving cars and virtual reality-augmented reality.
Adding more user plane nodes will also help service providers cope with the continual increase in mobile data traffic. AT&T says data in its mobile network has grown 3,600x since 2007 and it expects a further near-10x growth by 2022.
With CUPS, service providers can combine different vendors’ control plane and user plane solutions in their network. “We can now interoperate with third-party 5G control planes from vendors,” says Bament. Juniper already partners with Affirmed Networks, a virtualised 5G control plane vendor.
Service providers also have a choice for the user plane itself: they can use physical hardware such as Juniper’s MX platforms or virtualised user plane solutions from third-party vendors, or both solutions in their networks.
Universal chassis
Juniper has also unveiled two additional MX platforms that use its universal chassis announced a year ago. Having a universal chassis simplifies inventory management and operational costs.
The common chassis is already used for Juniper’s PTX packet transport core routers and its QFX switches for the data centres. At the time of the universal chassis launch, Juniper said it would also support MX linecards.
The two new MX edge routers using the universal platform are the MX10008 and MX10016. The 13 rack unit (13RU) MX10008 has a 19.2-terabit capacity while the 21RU MX10016 doubles it to 38.4 terabits.
White boxes
The leading service providers are increasingly promoting the adoption of white boxes yet the Juniper announcement includes all the classical elements of traditional telecom equipment: chassis, line cards and custom silicon.
“There is certainly a trend towards white-box implementations and certainly customers are buying software from us and putting it on white boxes,” says Bament. “But it is limited; there is still a way to go in terms of broad adoption.”
Bament points to Juniper’s software-based vMX virtual edge routing solution as well as its CUPS software to show that it is pursuing virtual network function solutions as well as enhancing its MX platforms to benefit service providers’ existing investments.
The two MX platforms will be available in the second half of this year, the Penta ASIC-based MPC10E line card for the MX240, MX480 and MX960 will be available in the first quarter of next year while the CUPS software is due in the first half of 2019.
Further information
Juniper Trio white paper, click here
The key elements of NFV usage: A guide
Orchestration, service assurance, service fulfilment, automation and closed-loop automation. These are important concepts associated with network functions virtualisation (NFV) technology being adopted by telecom operators as they transition their networks to become software-driven and cloud-based.
Prayson Pate (pictured), CTO of the Ensemble division at ADVA Optical Networking, explains the technologies and their role and gives each a status update.
Orchestration
Network functions virtualisation (NFV) is based on the idea of replacing physical appliances - telecom boxes - with software running on servers performing the same networking role.
 Using NFV speeds up service development and deployment while reducing equipment and operational costs.
Using NFV speeds up service development and deployment while reducing equipment and operational costs.
It also allows operators to work with multiple vendors rather than be dependent on a single vendor providing the platform and associated custom software.
Operators want to adopt software-based virtual network functions (VNFs) running on standard servers, storage and networking, referred to as NFV infrastructure (NFVI).
In such an NFV world, the term orchestration refers to the control and management of virtualised services, composed of virtual network functions and executed on the NFV infrastructure.
The use of virtualised services has created the need for a new orchestration layer that sits between the existing operations support system-billing support system (OSS-BSS) and the NFV infrastructure (see diagram below). This orchestration layer performs the following tasks:
- Manages the catalogue of virtual network functions developed by vendors and by the open-source communities.
- Translates incoming service requests to create the virtualised implementation using the underlying infrastructure.
- Links the virtual network functions as required to create a service, referred to as a service chain. This service chain may be on one server or it may be distributed across the network.
- Performs the various management tasks for the virtual network functions: setting them up, scaling them up and down, updating and upgrading them, and terminating them - the ‘lifecycle management’ of virtual network functions. The orchestrator also ensures their resiliency.
The ETSI standards body, the NFV Industry Specification Group (ETSI NFV ISG), leads the industry effort to define the architecture for NFV, including orchestration.
Several companies are providing proprietary and pre-standard NFV orchestration solutions, including ADVA Optical Networking, Amdocs, Ciena, Ericsson, IBM, Netcracker and others. In addition, there are open source initiatives such as the Linux Foundation Networking Fund’s Open Network Automation Platform (ONAP), ETSI NFV ISG’s Open Source MANO (OSM) and OpenStack’s Tacker initiative.
 Source: ETSI GS NFV 002
Source: ETSI GS NFV 002
Service assurance
Service providers promise that their service will meet a certain level of performance defined in the service level agreement (SLA).
Service assurance refers to the measurement of parameters such as packet loss and latency associated with a service; parameters which are compared against the SLA. Service assurance also remedies any SLA shortfalls. More sophisticated parameters can also be measured such as privacy and responses to distributed denial-of-service (DDOS) attacks.
NFV enables telcos to create and launch services more quickly and economically. But an end customer only cares about the service, not the underlying technology. Customers will not stand for a less reliable service or a service with inferior performance just because it is implemented as a virtual function on a server.
Service assurance is not a new concept, but the nature of a virtualised implementation means a new approach is required. No longer is there a one-to-one association between services and network elements, so the linkages between services, the building-block virtual network functions, and the underlying virtual infrastructure need to be understood. Just as the services are virtualised, so the service assurance process needs virtualised components such as virtual probes and test heads.
The telcos’ operations groups are concerned about how to deploy and support virtualised services. Innovations in service assurance will make their job easier and enable them to do what they could not do before.
EXFO, Ixia, Spirent, and Viavi supply virtual probes and test heads. These may be used for initial service verification, ongoing monitoring, and active troubleshooting. Active troubleshooting is a powerful concept as it enables an operator to diagnose issues without dispatching a technician and equipment.
Service fulfilment
Service fulfilment refers to the configuration and delivery of a service to a customer at one or more locations.
Service fulfilment is essential for an operator because it is how orders are turned into revenue. The more quickly and accurately a service is fulfilled, the sooner the operator gets paid. Prompt fulfilment also leads to greater customer satisfaction and reduced churn.
Early-adopter operators see NFV as a way to improve service fulfilment. Verizon is using its NFV-based service offering to speed up service fulfilment. When a customer orders a service, Verizon instructs the manufacturer to ship a server to the customer. Once connected and powered at the customer’s site, the server calls home and is configured. Combined with optional LTE, a customer can get a service on demand without waiting for a technician. This significantly improves the traditional model where a customer may wait weeks before being able to use the telco’s service.
Network automation
Network automation uses machines instead of trained staff to operate the network. For NFV, the automated software tasks include configuration, operation and monitoring of network elements.
The benefits of network automation include speed and accuracy of service fulfilment - humans can err - along with reduced operational costs.
Telcos have been using network automation for high-volume services and to manage complexity. That said, many operators include manual steps in their process. Such a hands-on approach doesn’t work with cloud technologies such as NFV. Cloud customers can acquire, deploy and operate services without any manual interaction from the webscale players. Likewise, NFV must be automated if telecom operators are to benefit from its potential.
Network automation is closely tied to orchestration. Commercial suppliers and open-source groups are working to ensure that service orders flow automatically from high-level systems down to implementation, dubbed flow-through provisioning and that ‘zero-touch’ provisioning that removes all manual steps becomes a reality. But for this to happen, open and standard interfaces are needed.
Closed-loop automation
Closed-loop automation adds a feedback loop to network automation. The feedback enables the automation to take into account changing network conditions such as loading and network failures, as well as dynamic service demands such as bandwidth changes or services wanted by users.
Closed-loop automation compares the network’s state against rules and policies, replacing what were previously staff decisions. These systems are sometimes referred to as intent-based, as they focus on the desired intent or result rather than on the inputs to the network controls.
Service providers are also investigating adding artificial intelligence and machine learning to closed loop automation. Artificial intelligence and machine learning can replace the hard-coded rules with adaptive and dynamic pattern recognition, allowing anomalies to be detected, adapted to, and even predicted.
Closed-loop automation offloads operational teams not only from manual control but also from manual management processes. Human decisions and planning are replaced by policy-driven control, while human reasoning is replaced by artificial intelligence and machine learning algorithms.
Policy systems or ‘engines’ have existed for a while for functions such as network and file access, but these engines were not closed-loop; there was no feedback. These policy concepts have now been updated to include desired network state, such that a feedback loop is needed to compare the current status with the desired one.
A closed-loop automation system makes dynamic changes to ensure a targeted operational state is reached even when network or service conditions change. This approach enables service providers to match capacity with demand, solve traffic management and network quality issues, and manage 5G and Internet of Things upgrades.
Closed loop automation is complex. Employing artificial intelligence and machine learning will require interfaces to be defined that allow network data into the intelligent systems and enable the outputs to be used.
Several suppliers have announced products supporting closed-loop automation or intent-based networking, including Apstra, Cisco Systems, Forward Networks, Juniper Networks, Nokia, and Veriflow Systems. In addition, the open source ONAP project is also pursuing work in this area.
400ZR will signal coherent’s entry into the datacom world
- 400ZR will have a reach of 80km and a target power consumption of 15W
- The coherent interface will be available as a pluggable module that will link data centre switches across sites
- Huawei expects first modules to be available in the first half of 2020
- At OFC, Huawei announced its own 250km 400-gigabit single-wavelength coherent solution that is already being shipped to customers
Coherent optics will finally cross over into datacom with the advent of the 400ZR interface. So claims Maxim Kuschnerov, senior R&D manager at Huawei.
 Maxim Kuschnerov400ZR is an interoperable 400-gigabit single-wavelength coherent interface being developed by the Optical Internetworking Forum (OIF).
Maxim Kuschnerov400ZR is an interoperable 400-gigabit single-wavelength coherent interface being developed by the Optical Internetworking Forum (OIF).
The 400ZR will be available as a pluggable module and as on-board optics using the COBO specification. The IEEE is also considering a proposal to adopt the 400ZR specification, initially for the data-centre interconnect market. “Once coherent moves from the OIF to the IEEE, its impact in the marketplace will be multiplied,” says Kuschnerov.
But developing a 400ZR pluggable represents a significant challenge for the industry. “Such interoperable coherent 16-QAM modules won’t happen easily,” says Kuschnerov. “Just look at the efforts of the industry to have PAM-4 interoperability, it is a tremendous step up from on-off keying.”
Despite the challenges, 400ZR products are expected by the first half of 2020.
400ZR use cases
The web-scale players want to use the 400ZR coherent interface to link multiple smaller buildings, up to 80km apart, across a metropolitan area to create one large virtual data centre. This is a more practical solution than trying to find a large enough location that is affordable and can be fed sufficient power.
Once coherent moves from the OIF to the IEEE, its impact in the marketplace will be multiplied
Given how servers, switches and pluggables in the data centre are interoperable, the attraction of the 400ZR is obvious, says Kuschnerov: “It would be a major bottleneck if you didn't have [coherent interface] interoperability at this scale.”
Moreover, the advent of the 400ZR interface will signal the start of coherent in datacom. Higher-capacity interfaces are doubling every two years or so due to the webscale players, says Kuschnerov, and with the advent of 800-gigabit and 1.6-terabit interfaces, coherent will be used for ever-shorter distances, from 80km to 40km and even 10km.
At 10km, volumes will be an order of magnitude greater than similar-reach dense wavelength-division multiplexing (DWDM) interfaces for telecom. “Datacom is a totally different experience, and it won’t work if you don’t have a stable supply base,” he says. “We see the ZR as the first step combining coherent technology and the datacom mindset.”
Data centre players will plug 400ZR modules into their switch-router platforms, avoiding the need to interface the switch-router to a modular, scalable DWDM platform used to link data centres.
The 400ZR will also find use in telecom. One use case is backhauling residential traffic over a cable operator’s single spans that tend to be lossy. Here, ZR can be used at 200 gigabits - using 64 gigabaud signalling and QPSK modulation - to extend the reach over the high-loss spans. Similarly, the 400ZR can also be used for 5G mobile backhaul, aggregating multiple 25-gigabit streams.
Another application is for enterprise connectivity over distances greater than 10km. Here, the 400ZR will compete with direct-detect 40km ER4 interfaces.
Having several use cases, not just data-centre interconnect, is vital for the success of the 400ZR. “Extending ZR to access and metro-regional provides the required diversity needed to have more confidence in the business case,” says Kuschnerov.
The 400ZR will support 400 gigabits over a single wavelength with a reach of 80km, while the target power consumption is 15W.
The industry is still undecided as to which pluggable form factor to use for 400ZR. The two candidates are the QSFP-DD and the OSFP. The QSFP-DD provides backward compatibility with the QSFP+ and QSFP28, while the OSFP is a fresh design that is also larger. This simplifies the power management at the expense of module density; 32 OSFPs can fit on a 1-rack-unit faceplate compared to 36 QSFP-DD modules.
The choice of form factor reflects a broader industry debate concerning 400-gigabit interfaces. But 400ZR is a more challenging design than 400-gigabit client-side interfaces in terms of trying to cram optics and the coherent DSP within the two modules while meeting their power envelopes.
The OSFP is specified to support 15W while simulation results published at OFC 2018 suggest that the QSFP-DD will meet the 15W target. Meanwhile, the 15W power consumption will not be an issue for COBO on-board optics, given that the module sits on the line card and differs from pluggables in not being confined within a cage.
Kuschnerov says that even if it proves that only the OSFP of the two pluggables supports 400ZR, the interface will still be a success given that a pluggable module will exist that delivers the required face-plate density.
400G coherent
Huawei announced at OFC 2018 its own single-wavelength 400-gigabit coherent technology for use with its OptiX OSN 9800 optical and packet OTN platform, and it is already being supplied to customers.
The 400-gigabit design supports a variety of baud rates and modulation schemes. For a fixed-grid network, 34 gigabaud signalling enables 100 gigabits using QPSK, and 200 gigabits using 16-QAM, while at 45 gigabaud 200 gigabits using 8-QAM is possible. For flexible-grid networks, 64 gigabaud is used for 200-gigabit transmission using QPSK and 400 gigabits using 16-QAM.
Huawei uses an algorithm called channel-matched shaping to improve optical performance in terms of data transmission and reach. This algorithm includes such techniques as pre-emphasis, faster-than-Nyquist, and Nyquist shaping. According to Kuschnerov, the goal is to squeeze as much capacity out of a network’s physical channel so that advanced coding techniques such as probabilistic constellation shaping can be used to the full. For Huawei’s first 400-gigabit wavelength solution, constellation shaping is not used but this will be added in its upcoming coherent designs.
Huawei has already demonstrated the transmission of 400 gigabits over 250km of fibre. “Current generation 400G-per-lambdas does not enable long-haul or regional transmission so the focus is on shorter reach metro or data-centre-interconnect environments,” says Kuschnerov.
When longer reaches are needed, Huawei can offer two line cards, each supporting 200 gigabits, or a single line card hosting two 200-gigabit modules. The 200-gigabits-per-wavelength is achieved using 64 gigabaud and QPSK modulation, resulting in a 2,500km reach.
Up till now, such long-haul distances have been served using 100-gigabitwavelengths. Now, says Kuschnerov, 200 gigabit at 64 gigabaud is becoming the new norm in many newly built networks while the 34 gigabaud 200 gigabit is being favoured in existing networks based on a 50GHz grid.
Oclaro uses Acacia’s Meru DSP for its CFP2-DCO
Oclaro will use Acacia Communications’ coherent DSP for its pluggable CFP2 Digital Coherent Optics (CFP2-DCO) module. The module will be compatible with Acacia’s own CFP2-DCO, effectively offering customers a second source.
 Tom Williams This is the first time Acacia is making its coherent DSP technology available to a fellow module maker, says Tom Williams, Acacia’s senior director, marketing.
Tom Williams This is the first time Acacia is making its coherent DSP technology available to a fellow module maker, says Tom Williams, Acacia’s senior director, marketing.
Acacia benefits from the deal by expanding the market for its technology, while Oclaro gains access to a leading low-power coherent DSP, the Meru, and can bring to market its own CFP2-DCO product.
Williams says the move was encouraged by customers and that having a second source and achieving interoperability will drive CFP2-DCO market adoption. That said, Acacia is not looking for further module partners. “With two strong suppliers, we don’t see a need to add additional ones,” says Williams.
“This agreement is a sign that the market is reaching maturity, with suppliers transitioning from grabbing market share at all costs to more rational strategies,” says Vladimir Kozlov, CEO and founder of LightCounting Market Research.
CFP2-DCO
The CFP2-DCO is a dense wavelength-division multiplexing module that supports 100-gigabit and 200-gigabit data rates.
With the CFP2-DCO design, the coherent DSP sits within the module, unlike the CFP2 Analog Coherent Optics (CFP2-ACO) where the DSP chip is external, residing on the line card.
According to Kevin Affolter, Oclaro’s vice president strategic marketing, the company looked at several merchant and non-merchant coherent DSPs but chose the Meru due to its low power consumption and its support for 200 gigabits using 8-ary quadrature amplitude modulation (8-QAM) as well as the 16-QAM scheme. Using 8-QAM extends the optical reach of 200-gigabit wavelengths.
This agreement is a sign that the market is reaching maturity, with suppliers transitioning from grabbing market share at all costs to more rational strategies
At 100 gigabits the CFP2-DCO achieves long-haul distances of 2,000km whereas at 200 gigabit at 8-QAM, the reach is in excess of 1,000km. The 8-QAM requires a wider passband than the 16-QAM, however, such that in certain metro networks where the signal passes through several ROADM stages, it is better to use the 16-QAM mode, says Acacia.
 Source: Acacia, Gazettabyte
Source: Acacia, Gazettabyte
Oclaro’s design will combine the Meru with its indium phosphide-based optics whereas Acacia’s CFP2-DCO uses silicon photonics technology. The power consumption of the CFP2-DCO module is of the order of 20W.
The two companies say their CFP2-DCO modules will be compatible with the multi-source agreement for open reconfigurable add-drop multiplexers (ROADMs). The Open ROADM MSA is backed by 16 companies, eight of which are operators. The standard currently only defines 100-gigabit transmission based on a hard-decision forward-error correction.
“There are several carriers, AT&T being the most prominent, within Open ROADM,” says Affolter. “It makes sense for both companies to make sure the needs of Open ROADM are addressed.”
Coherent shift
In 2017, Oclaro was one of three optical module companies that signed an agreement with Ciena to use the systems vendor’s WaveLogic Ai coherent DSP to develop a 400-gigabit transponder.
 Kevin Affolter
Kevin Affolter
Affolter says the Ciena and Acacia agreements should be seen as distinct; the 400-gigabit design is a large, 5x7-inch non-pluggable module designed for maximum reach and capacity. “The deals are complementary and this announcement has no impact on the Ciena announcement,” says Affolter.
Does the offering of proprietary DSPs to module makers suggest a shift in coherent that has always been seen as a strategic technology that allows for differentiation?
Affolter thinks not. “There are several vertically integrated vendors with their own DSPs that will continue to leverage their investment as much as they can,” he says. “But there is also an evolution of end customers and network equipment manufacturers that are moving to more pluggable solutions and that is where the -DCO really plays.”
Oclaro expects to have first samples of its CFP2-DCO by year-end. Meanwhile, Acacia’s CFP2-DCO has been generally available for over six months.
How ONAP is blurring network boundaries
Telecom operators will soon be able to expand their networks by running virtualised network functions in the public cloud. This follows work by Amdocs to port the open-source Open Network Automation Platform (ONAP) onto Microsoft’s Azure cloud service.
 Source: Amdocs, Linux Foundation
Source: Amdocs, Linux Foundation
According to Craig Sinasac, network product business unit manager at Amdocs, several telecom operators are planning to run telecom applications on the Azure platform, and the software and services company is already working with one service provider to prepare the first trial of the technology.
Deploying ONAP in the public cloud blurs the normal understanding of what comprises an operator’s network. The development also offers the prospect of web-scale players delivering telecom services using ONAP.
ONAP
ONAP is an open-source network management and orchestration platform, overseen by the Linux Foundation. It was formed in 2017 with the merger of two open-source orchestration and management platforms: AT&T’s ECOMP platform, and Open-Orchestrator (Open-O), a network functions virtualisation platform initiative backed by companies such as China Mobile, China Telecom, Ericsson, Huawei and ZTE.
The ONAP framework’s aim is the become the telecom industry’s de-facto orchestration and management platform.
 Craig SinasacAmdocs originally worked with AT&T to develop ECOMP as part of the operator’s Domain 2.0 initiative.
Craig SinasacAmdocs originally worked with AT&T to develop ECOMP as part of the operator’s Domain 2.0 initiative.
“Amdocs has hundreds of people working on ONAP and is the leading vendor in terms of added lines of code to the open-source project,” says Sinasac.
Amdocs has make several changes to the ONAP code to port it onto the Azure platform.
The company is using Kubernetes, the open-source orchestration system used to deploy, scale and manage container-based applications. Containers, used with micro-services, offer several advantages compared to running networks functions on virtual machines.
Amdocs is also changing ONAP components to make use of TOSCA cloud generic descriptor files that are employed with the virtual network functions. The descriptor files are an important element to enable virtual network functions from different vendors to work on ONAP, simplifying the operator effort needed for their integration.
“There are also changes to the multiVIM component of ONAP, to enable Azure cloud control,” says Sinasac. MultiVIM is designed to decouple ONAP from the underlying cloud infrastructure.
Further work is needed so that ONAP can manage a multi-cloud environment. One task is to enable closed-loop control by completing work already underway to the ONAP Data Collection, Analytics, and Events (DCAE) component to run in containers. The DCAE is a component of ONAP that is of interest to several operators that recently joined ONAP.
Amdocs is making its changes available as open-source code.
Business opportunities
For Microsoft, porting ONAP onto Azure promises new operator customers. Microsoft is also keen for vendors like Amdocs to use Azure for their own development work.
Telecom operators could use the Azure platform in several ways. An operator running ONAP on its own cloud-based network could use the platform to spin up additional network functions on the Azure platform. This could be to expand network capacity, restore the network in case of a fault, or to host location-sensitive network functions where the operator has no presence.
A telco could also use Azure’s data centres to expand into regions where it has no presence.
Amdocs says cloud players could offer telecom and over-the-top services using ONAP. “As long as they have connectivity to their customers,” says Sinasac.
ONF’s operators seize control of their networking needs
- The eight ONF service providers will develop reference designs addressing the network edge.
- The service providers want to spur the deployment of open-source designs after becoming frustrated with the systems vendors failing to deliver what they need.
- The reference designs will be up and running before year-end.
- New partners have committed to join since the consortium announced its strategic plan
The service providers leading the Open Networking Foundation (ONF) will publish open designs to address next-generation networking needs.
Timon SloaneThe ONF service providers - NTT Group, AT&T, Telefonica, Deutsche Telekom, Comcast, China Unicom, Turk Telekom and Google - are taking a hands-on approach to the design of their networks after becoming frustrated with what they perceive as foot-dragging by the systems vendors.
“All eight [operators] have come together to say in unison that they are going to work inside the ONF to craft explicit plans - blueprints - for the industry for how to deploy open-source-based solutions,” says Timon Sloane, vice president of marketing and ecosystem at the ONF.
The open-source organisation will develop ‘reference designs’ based on open-source components for the network edge. The reference designs will address developments such as 5G and multi-access edge and will be implemented using cloud, white box, network functions virtualisation (NFV) and software-defined networking (SDN) technologies.
By issuing the designs and committing to deploy them, the operators want to attract select systems vendors that will work with them to fulfil their networking needs.
Remit
The ONF is known for such open-source projects as the Central Office Rearchitected as a Datacenter (CORD) and the Open Networking Operating System (ONOS) SDN controller.
The ONF’s scope has broadened over the years, reflecting the evolving needs of its operator members. The organisation’s remit is to reinvent the network edge. “To apply the best of SDN, NFV and cloud technologies to enable not just raw connectivity but also the delivery of services and applications at the edge,” says Sloane.
The network edge spans from the central office to the cellular tower and includes the emerging edge cloud that extends the ‘edge’ to such developments as the connected car and drones.
The operators have been hopeful the whole vendor community would step up and start building solutions and embracing this approach but it is not happening at the speed operators want, demand and need
“The edge cloud is called a lot of different things right now: multi-access edge computing, fog computing, far edge and distributed cloud,” says Sloane. “It hasn’t solidified yet.”
One ONF open-source project is the Open and Disaggregated Transport Network (ODTN), led by NTT. “ODTN is edge related but not exclusively so,” says Sloane. “It is starting off with a data centre interconnect focus but you should think of it as CORD-to-WAN connectivity.”
The ONF’s operators spent months formulated the initiative, dubbed the Strategic Plan, after growing frustrated with a supply chain that has failed to deliver the open-source solutions they need. “The operators have been hopeful the whole vendor community would step up and start building solutions and embracing this approach but it is not happening at the speed operators want, demand and need,” says Sloane.
The ONF’s initiative signals to the industry that the operators are shifting their spending to open-source solutions and basing their procurement decisions on the reference designs they produce.
“It is a clear sign to the industry that things are shifting,” says Sloane. “The longer you sit on the sidelines and wait and see what happens, the more likely you are to lose your position in the industry.”
If operators adopt open-source software and use white boxes based on merchant silicon, how will systems vendors produce differentiated solutions?
“All this goes to show why this is disruptive and creating turbulence in the industry,” says Sloane.
Open-source design equates to industry collaboration to develop shared, non-differentiated infrastructure, he says. That means system vendors can focus their R&D tackling new issues such as running and automating networks, developing applications and solving challenges such as next-generation radio access and radio spectrum management.
“We want people to move with the mark,” says Sloane. “It is not just building a legacy business based on what used to be unique and expecting to build that into the future.”
Reference designs
The operators have identified five reference designs: fixed and mobile broadband, multi-access edge, leaf-and-spine architectures, 5G at the edge, and next-generation SDN.
The ONF has already done much work in fixed and mobile broadband with its residential and mobile CORD projects. Multi-access edge refers to developing one network to serve all types of customers simultaneously, using cloud techniques to shift networking resources dynamically as needed.
At first glance, it is unclear what the ONF can contribute to leaf-and-spine architectures. But the ONF is developing SDN-controlled switch fabric that can perform advanced packet processing, not just packet forwarding.
The ONF’s initiative signals to the industry that the operators are shifting their spending to open-source solutions and basing their procurement decisions on the reference designs they produce.
Sloane says that many virtualised tasks today are run on server blades using processors based on the x86 instruction set. But offloading packet processing tasks to programmable switch chips - referred to as networking fabric - can significantly benefit the price-performance achieved.
“We can leverage [the] P4 [programming language for data forwarding] and start to do things people never envisaged being done in a fabric,” says Sloane, adding that the organisation overseeing P4 is going to merge with the ONF.
The 5G reference design is one application where such a switch fabric will play a role. The ONF is working on implementing 5G network core functions and features such as network slicing, using the P4 language to run core tasks on intelligent fabric.
The ONF has already done work separating the radio access network (RAN) controller from radio frequency equipment and aims to use SDN to control a pool of resources and make intelligent decisions about the placement of subscribers, workloads and how the available radio spectrum can best be used.
The ONF’s fifth reference design addresses next-generation SDN and will use work that Google has developed and is contributing to the ONF.
The ONF manages the OpenFlow protocol, used to define the separation between the control and data forwarding planes. But the ONF is the first to admit that OpenFlow overlooked such issues as equipment configuration and operational issues.
The ONF is now engaged in a next-generation SDN initiative. “We are taking a step back and looking at the whole problem, to address all the pieces that didn’t get resolved in the past,” says Sloane.
Google has also contributed two interfaces that allow device management and the ONF has started its Stratum project that will develop an open-source solution for white boxes to expose these interfaces. This software residing on the white box has no control intelligence and does not make any packet-forwarding decisions. That will be done by the SDN controller that talks to the white box via these interfaces. Accordingly, the ONF is updating its ONOS controller to use these new interfaces.
 Source: ONF
Source: ONF
From reference designs to deployment
The ONF has a clear process to transition its reference designs to solutions ready for network deployment.
The reference designs will be produced by the eight operators working with other ONF partners. “The reference design is to help others in the industry to understand where you might choose to swap in another open source piece or put in a commercial piece,” says Sloane.
This explains how the components are linked to the reference design (see diagram above). The ONF also includes the concept of the exemplar platform, the specific implementation of the reference design. “We have seen that there is tremendous value in having an open platform, something like Residential CORD,” says Sloane. “That really is what the exemplar platform is.”
The ONF says there will be one exemplar platform for each reference design but operators will be able to pick particular components for their implementations. The exemplar platform will inevitably also need to interface to a network management and orchestration platform such as the Linux Foundation’s Open Network Automation Platform (ONAP) or ETSI’s Open Source MANO (OSM).
The process of refining the reference design and honing the exemplar platform built using specific components is inevitably iterative but once completed, the operators will have a solution to test, trial and, ultimately, deploy.
The ONF says that since announcing the strategic plan a month ago, several new partners - as yet unannounced - have committed to join.
“The intention is to have the reference designs up and running before the end of the year,” says Sloane.
Ciena goes stackable with 8180 'white box' and 6500 RLS
Ciena has unveiled two products - the 8180 coherent networking platform and the 6500 reconfigurable line system - that target cable and cellular operators that are deploying fibre deep in their networks, closer to subscribers.
The 6500 line system is also aimed at the data centre interconnect market given how the webscale players are experiencing a near-doubling of traffic each year.
 Source: Ciena
Source: Ciena
The cable industry is moving to a distributed access architecture (DAA) that brings fibre closer to the network’s edge and splits part of the functionality of the cable modem termination system (CMTS) - the remote PHY - closer to end users. The cable operators are deploying fibre to boost the data rates they can offer homes and businesses.
Both Ciena’s 8180 modular switch and the 6500 reconfigurable line system are suited to the cable network. The 8180 is used to link the master headend with primary and secondary hub sites where aggregated traffic is collected from the digital nodes (see network diagram). The 8180 platforms will use the modular 6500 line system to carry the dense wavelength-division multiplexed (DWDM) traffic.
 “The [cable] folks that are modernising the access network are not used to managing optical networking,” says Helen Xenos, senior director, portfolio marketing at Ciena (pictured). “They are looking for simple platforms, aggregating all the connections that are coming in from the access.”
“The [cable] folks that are modernising the access network are not used to managing optical networking,” says Helen Xenos, senior director, portfolio marketing at Ciena (pictured). “They are looking for simple platforms, aggregating all the connections that are coming in from the access.”
The 8180 can play a similar role for wireless operators, using DWDM to carry aggregated traffic for 4G and 5G networks.
Ciena says the 6500 optical line system will also serve the data centre interconnect market, complementing the WaveServer Ai, Ciena’s second-generation 1RU modular platform that has 2.4 terabits of client-side interfaces and 2.4 terabits of coherent capacity.
With the 8180, you are only using the capacity on the fibre that you have traffic for
“They [the webscale players] are looking for as many efficiencies as they can get from the platforms they deploy,” says Xenos. “The 6500 reconfigurable line system gives them the flexibility they need - a colourless, directionless, contentionless [reconfigurable optical add-drop multiplexer] and a flexible grid that extends to the L-band.”
A research note from analyst house, Jefferies, published after the recent OFC show where Ciena announced the platforms, noted that in many cable networks, 6-strand fibre is used: two fibre pairs allocated for business services and one for residential. Adding the L-band to the existing C-band effectively doubles the capacity of each fibre pair, it noted.
The 8180
Ciena’s 8180 is a modular packet switch that includes coherent optics. The 8180 is similar in concept to the Voyager and Cassini white boxes developed by the Telecom Infra Project. However, the 8180 is a two-rack-unit (2RU) 6.4-terabit switch compared to the 1RU, 2-terabit Voyager and the 1.5RU 3.2-terabit Cassini. The 8180 also uses Ciena’s own 400-gigabit coherent DSP, the WaveLogic Ai, rather than merchant coherent DSP chips.
The platform comprises 32 QSFP+/ QSFP28 client-side ports, a 6.4-terabit switch chip and four replaceable modules or ‘sleds’, each capable of accommodating 800 gigabits of capacity. The options include an initial 400-gigabit line-side coherent interface (a sled with two coherent WaveLogic Ai DSPs will follow), an 8x100-gigabit QSFP28 sled, a 2x400-gigabit sled and also the option for an 800-gigabit module once they become available.
 Source: Ciena
Source: Ciena
Using all four sleds as client-side options, the 8180 becomes a 6.4-terabit Ethernet switch. Using only coherent sleds instead, the packet-optical platform has a 1.6-terabit line-side capacity. And because there is a powerful switch chip integrated, the input ports can be over-subscribed.“With the 8180, you are only using the capacity on the fibre that you have traffic for,” says Xenos.
6500 line system
The 6500 reconfigurable line system is also a modular design. Aimed at the cable, wireless, and data centre interconnect markets, only a subset of Ciena’s existing optical line systems features is used.
“The 6500 software has a lot of capabilities that the content providers are not using,” says Xenos. “They just want to use it as a photonic layer.”
There are three 6500 reconfigurable line system platform sizes: 1RU, 2RU and 4RU. The chassis can be stacked and managed as one unit. Card options that fit within the chassis include amplifiers and reconfigurable optical add-drop multiplexers (ROADMs).
The amplifier options area dual-line Erbium-doped fibre amplifiercard that includes an integrated bi-directional optical time-domain reflectometer (OTDR) used to characterise the fibre. There is also a half-line-width RAMAN amplifier card. The line system will support the C and L bands, as mentioned.
The reconfigurable line system also has ROADM cards: a 1x12 wavelength-selective switch (WSS) with integrated amplifier, a colourless 16-channel add-drop that support channels of any size (flexible grid), and a full-width card 1x32 WSS. “The 1x32 would be used for colourless, directionless and directionless [ROADM] configurations,” says Xenos.
The 6500 reconfigurable line system also supports open application porgramming interfaces (APIs) for telemetry, with a user able to program the platform to define the data streamed.“The platform can also be provisioned via REST APIs; something a content provider will do,” she says.
Ciena is a member of the OpenROADM multi-source agreement and was involved in last year’s AT&T OpenROADM trial with its 6500 Converged Packet Optical Transport (POTS) platform.
Will the 6500 reconfigurable line system be OpenROADM-compliant?
“This card [and chassis form factor] could be used for OpenROADM if AT&T preferred this platform to the other [6500 Converged POTS] one,” says Xenos. “You also have to design the hardware to meet the specifications for OpenROADM.”
Ciena expects both platforms to be available by year-end. The 6500 reconfigurable line system will be in customer trials at the end of this quarter while the 8180 will be trialed by the end of the third quarter.