
Data centre disaggregation with Gen-Z and CXL

Part 1: CXL and Gen-Z
- The Gen-Z and Compute Express Link (CXL) protocols have been shown working in unison to implement a disaggregated processor and memory system at the recent Supercomputing 21 show.
- The Gen-Z Consortium’s assets are being subsumed within the CXL Consortium. CXL will become the sole industry standard moving forward.
- Microsoft and Meta are two data centre operators backing CXL.
Pity Hiren Patel, tasked with explaining the Gen-Z and CXL networking demonstration operating across several booths at the Supercomputing 21 (SC21) show held in St. Louis, Missouri in November.
Not only was Patel wearing a sanitary mask while describing the demo but he had to battle to be heard above cooling fans so loud, you could still be at St. Louis Lambert International Airport.
Gen-Z and CXL are key protocols supporting memory and server disaggregation in the data centre.
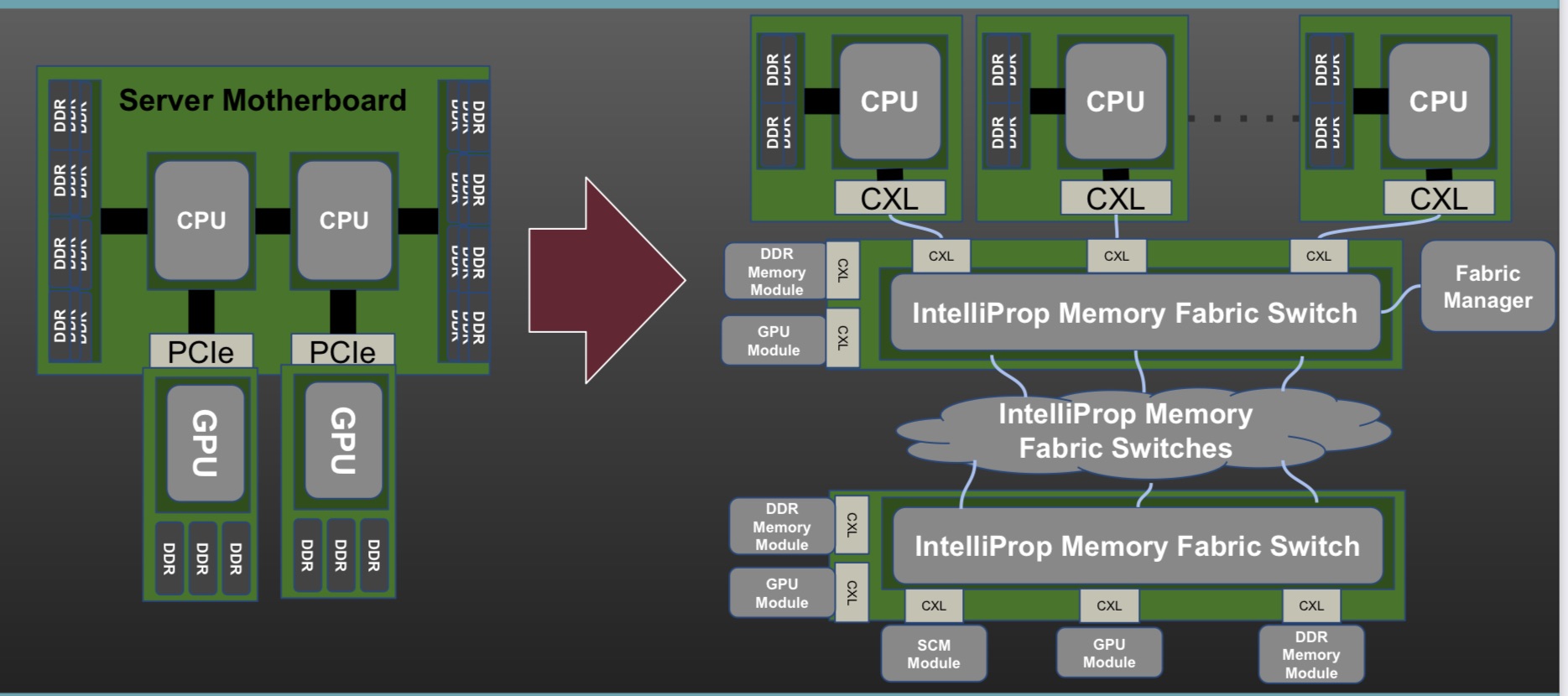
The SC21 demo showed Gen-Z and CXL linking compute nodes to remote ‘media boxes’ filled with memory in a distributed multi-node network (see diagram, bottom).
CXL was used as the host interface on the various nodes while Gen-Z created and oversaw the mesh network linking equipment up to tens of meters apart.
“What our demo showed is that it is finally coming to fruition, albeit with FPGAs,” says Patel, CEO of IP specialist, IntelliProp, and President of the Gen-Z Consortium.
Interconnects
Gen-Z and CXL are two of a class of interconnect schemes announced in recent years.
The interconnects came about to enable efficient ways to connect CPUs, accelerators and memory. They also address a desire among data centre operators to disaggregate servers so that key components such as memory can be pooled separately from the CPUs.
The idea of disaggregation is not new. The Gen-Z protocol emerged from HPE’s development of The Machine, a novel memory-centric computer architecture. The Gen-Z Consortium was formed in 2016, backed by HPE and Dell, another leading high-performance computing specialist. The CXL consortium was formed in 2019.
Other interconnects of recent years include the Open Coherent Accelerator Processor Interface (Open-CAPI), Intel’s own interconnect scheme Omni-Path which it subsequently sold off, Nvidia’s NVLink, and the Cache Coherent Interconnect for Accelerators (CCIX).
The emergence of the host buses was also a result of industry frustration with the prolonged delay in the release of the then PCI Express (PCIe) 4.0 specification.
All these interconnects are valuable, says Patel, but many are implemented in a proprietary manner whereas CXL and Gen-Z are open standards that have gained industry support.
“There is value moving away from proprietary to an industry standard,” says Patel.
Merits of pooling
Disaggregated designs with pooled memory deliver several advantages: memory can be upgraded at different stages to the CPUs, with extra memory added as required. “Memory growth is outstripping CPU core growth,” says Patel. “Now you need banks of memory outside of the server box.”
A disaggregated memory architecture also supports multiple compute nodes – CPUs and accelerators such as graphics processor units (GPUs) or FPGAs – collaborating on a common data set.
Such resources also become configurable: in artificial intelligence, training workloads require a hardware configuration different to inferencing. With disaggregation, resources can be requested for a workload and then released once a task is completed.
Memory disaggregation also helps data centre operators drive down the cost-per-bit of memory. “What data centres spend just on DRAM is extraordinarily high,” says Erich Hanke, senior principal engineer, storage and memory products, at IntelliProp.
Memory can be used more efficiently and need no longer to be stranded. A server can be designed for average workloads, not worse case ones as is done now. And when worst-case scenarios arise, extra memory can be requested.

“This allows the design of efficient data centres that are cost optimised while not losing out on the aggregate performance,” says Hanke.
Hanke also highlights another advantage, minimising data loss during downtimes. Given the huge number of servers in a data centre, reboots and kernel upgrades are a continual occurrence. With disaggregated memory, active memory resources need not be lost.
Gen-Z and CXL
The Gen-Z protocol allows for the allocation and deallocation of resources, whether memory, accelerators or networking. “It can be used to create a temporary or permanent binding of that resource to one or more CPU nodes,” says Hanke.
Gen-Z supports native peer-to-peer requests flowing in any direction through a fabric, says Hanke. This is different to PCIe which supports tree-type topologies.
Gen-Z and CXL are also memory-semantic protocols whereas PCIe is not.
With a memory-semantic protocol, a processor natively issues data loads and stores into fabric-attached components. “No layer of software or a driver is needed to DMA (direct memory access) data out of a storage device if you have a memory-semantic fabric,” says Hanke.
Gen-Z is also hugely scalable. It supports 4,096 nodes per subnet and 64,000 subnets, a total of 256 million nodes per fabric.
The Gen-Z specification is designed modularly, comprising a core specification and other components such as for the physical layer to accommodate changes in serialiser-deserialiser (serdes) speeds.
For example, the SC21 demo using an FPGA implemented 25 giga-transfers a second (25GT/s) but the standard will support 50 and 112GT/s rates. In effect, the Gen-Z specification is largely done.
What Gen-Z does not support is cache coherency but that is what CXL is designed to do. Version 2.0 of the CXL specification has already been published and version 3.0 is expected in the first half of 2022.
CXL 2.0 supports three protocols: CXL.io which is similar to PCIe – CXL uses the physical layer of the PCIe bus, CXL.memory for host-memory accesses, and CXL.cache for coherent host-cache accesses.
“More and more processors will have CXL as their connect point,” says Patel. “You may not see Open-CAPI as a connect point, you may not see NVLink as a connect point, you won’t see Gen-Z as a connect point but you will see CXL on processors.”
SC21 demo
The demo’s goal was to show how computing nodes – hosts – could be connected to memory modules through a switched Gen-Z fabric.
The equipment included a server hosting the latest Intel Sapphire Rapids processor, a quad-core A53 ARM processor on a Xilinx FPGA implemented with a Bittware 250SoC FPGA card, as well as several media boxes housing memory modules.
The ARM processor was used as the Fabric Manager node which oversees the network to allow access to the storage endpoints. There is also a Fabric Adaptor that connects to the Intel processor’s CXL bus on one side and the other to the memory-semantic fabric.
“CXL is in the hosts and everything outside that is Gen-Z,” says Patel.
The CXL V1.1 interface is used with four hosts (see diagram below). The V1.1 specification is point-to-point and as such can’t be used for any of the fabric implementations, says Patel. The 128Gbps CXL host interfaces were implemented as eight lanes of 16Gbps, using the PCIe 4.0 physical layer.
The Intel Sapphire Rapids processor supports a CXL Gen5x16 bus supporting 512Gbps (PCIe 5.0 x 16 lanes) but that is too fast for IntelliProp’s FPGA implementation. “An ASIC implementation of the IntelliProp CXL host fabric adapter would run at the 512Gpbs full rate,” says Patel. With an ASIC, the Gen-Z port court could be increased from 12 to 48 ports while the latency of each hop would be 35ns only.
The media box is a two-rack-unit (2RU) server without a CPU but with fabric-attached memory modules. Each memory module has a switch that enables multipath accesses. A memory module of 256Gbytes could be partitioned across all four hosts, for example. Equally, memory can be shared among the hosts. In the SC21 demo, memory in a media box was accessed by a server 30m away.
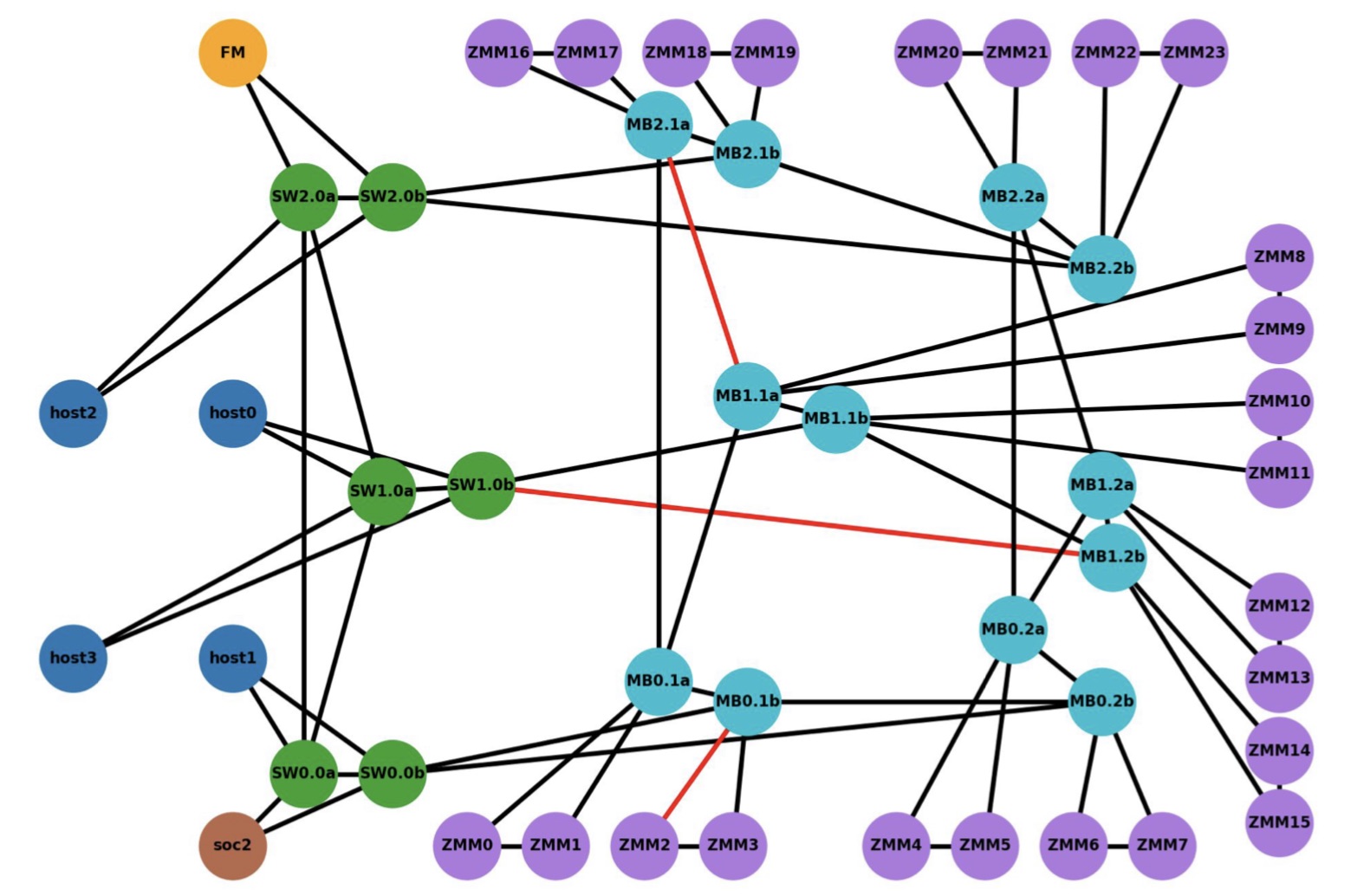
IntelliProp implemented the Host Fabric Adapter which included integrated switching, a 12-port Gen-Z switch, and the memory modules featuring integrated switching. All of the SC21 demonstration, outside of the Intel host, was done using FPGAs.
For a data centre, the media boxes would connect to a top-of-rack switch and fan out to multiple servers. “The media box could be co-located in a rack with CPU servers, or adjacent racks or a pod,” says Hanke.
The distances of a Gen-Z network in a data centre would typically be a row- or pod-scale, says Hanke. IntelliProp has had enquiries about going greater distances but above 30m fibre length starts to dictate latency. It’s a 10ns round trip for each meter of cable, says IntelliProp.
What the demo also showed was how well the Gen-Z and CXL protocols combine. “Gen-Z converts the host physical address to a fabric address in a very low latency manner; this is how they will eventually blend,” says Hanke.
What next?
The CXL Consortium and The Gen-Z Consortium signed a memorandum of understanding in 2020 and now Gen-Z’s assets are being transferred to the CXL Consortium. Going forward, CXL will become the sole industry standard.
Meanwhile, Microsoft, speaking at SC21, expressed its interest in CXL to support disaggregated memory and to grow memory dynamically in real-time. Meta is also backing the standard. But both cloud companies need the standard to be easily manageable (software) and stress the importance that CXL and its evolutions have minimal impact on overall latency.

PMC unveils OTN framer for IP core and edge routers
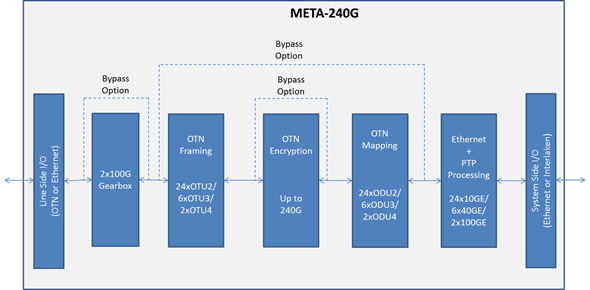
The Meta-240G frames IP router traffic using OTN before passing the traffic to the transport network. Line-rate encryption is included on-chip to secure traffic between data centres and traffic in the cloud.
 Source: PMC-Sierra
Source: PMC-Sierra
Adding OTN to a router delivers several benefits, says PMC. OTN helps identify networking faults more quickly and simplifies the monitoring and enforcement of service-level agreements. OTN also includes forward-error correction which benefits optical link performance.
Ethernet is the default router protocol interface while OTN is the dominant protocol in the transport network, says PMC. By moving OTN onto the router’s line port, the transport network extends its end-point reach to the router, says Stephen Docking, senior product line manager, communications unit at PMC. This leads to faster fault isolation and fault recovery.
“The transport network can now communicate with the router in a standard way, providing an extra level of protection that is faster than just IP layer protection,” says Docking.
OTN also supports the monitoring of error rates across the link.“By making the router part of the link, the service provider can not only monitor performance within the transport network but across the entire end-to-end link including the router,” says Docking. Such monitoring helps verify service-level agreements.
Meta-240G features
The Meta-240G is PMC’s third-generation framer for routers. The previous generation device, the 120 gigabit Meta-120G was PMC’s first to support OTU4 100 gigabit frames and was implemented in 40nm CMOS.
The Meta-240G doubles the total bandwidth: 240 gigabit facing the front panel optics and 240 gigabit interfacing to the network processor on the router’s line card. The device can thus support two 100 gigabit interfaces, six 40 gigabit interfaces and 24, 10 gigabit interfaces. “You can even have two 100 Gig and one 40 Gig, or two 100 Gig and four 10 Gig but most customers will just use 100 Gig [interfaces],” says Docking.
PMC has doubled the framer’s capacity while keeping overall power consumption fixed, in effect halving the power per port compared to its previous generation Meta-120G framer. Yet the chip also supports new features including a low-latency AES-256 encryption engine and an on-chip gearbox. The Meta-240G achieves the power savings by making the chip in 28nm CMOS and by improving the serdes design.
The gearbox function translates between 10 gigabit streams and 25 gigabit ones. Many devices use 10 gigabit serdes but to connect to a CFP2 or CFP4 100 gigabit optical modules, 25 gigabit electrical channels are required.
“Designers have had to use discrete gearbox devices [on the line card] which adds space, power and cost,” says Docking. “With the Meta-240G, the gearbox function is integrated into the device.”
Given IP traffic trends, will a 400 gigabit Meta device be needed in 2017? “It may be a bit longer - two to three years’ time - but we would need to [have such a device] to follow the existing trend,” says Docking.
Further information
PMC advances OTN with 400 Gigabit processor, click here