
Nuage uses SDN to aid enterprise connectivity needs
"Across the WAN and out to the branch, the context is increasingly complicated, with the need to deliver legacy and cloud applications to users - and sometimes customers - that are increasingly mobile, spanning several networks," says Brad Casemore, research director, data centre networks at IDC. These networks can include MPLS, Metro Ethernet, broadband and 3G and 4G wireless.
 The data centre is a great microcosm of the network - Houman Modarres
The data centre is a great microcosm of the network - Houman Modarres
At present, remote offices use custom equipment that require a visit from an engineer. In contrast, VNS uses SDN technology to deliver enterprise services to a generic box, or software that runs on the enterprise's server. The goal is to speed up the time it takes an enterprise to set up or change their business services at a remote site, while also simplifying the service provider's operations.
What has been done
Nuage designed its SDN-enabled connectivity products from the start for use in the data centre and beyond. "The data centre is a great microcosm of the network," says Modarres. "But we designed it in such a way that the end points could be flexible, within and across data centres but also anywhere."
Nuage uses open protocols like OpenFlow to enable the control plane to talk to any device, while its software agents that run on a server can work with any hypervisor. The control plane-based policies are downloaded to the end points via its SDN controller.
Using VNS, services can be installed without a visit from a specialist engineer. A user powers up the generic hardware or server and connects it to the network whereby policies are downloaded. The user enters a sent code that enables their privileges as defined by the enterprise's policies.
"Just as in the data centre, there is a real need for greater agility through automation, programmability, and orchestration," says IDC's Casemore. "One could even contend that for many enterprises, the pain is more acutely felt on the WAN, especially as they grapple with how to adapt to cloud and mobility."
Extending the connectivity end points beyond the data centre has required Nuage to bolster security and authentication procedures. Modarres points out that data centers and service provider central offices are secured environments; a remote office that could be a worker's home is not.

"You need to do authentication differently and IPsec connections are needed for security, but what if you unplug it? What if it is stolen?" he says. "If someone goes to the bank and steals a router, are they a bank branch now?"
To address this, once a remote office device is unplugged for a set time - typically several minutes - its configuration is reset. Equally, when a router is deliberated unplugged, for example during an office move, if notification is given, the user receives a new authentication code on the move's completion and the policies are restored.
Nuage's virtualised services platform comprise three elements: the virtualised services directory (VSD), virtualised services controller (VSC) - the SDN controller - and the virtual routing and switching module (VR&S).
"The only thing we are changing is the bottom layer, the network end point, which used to be in the data centre as the VR&S, and is now broken out of the data centre, as in the network services gateway, to be anywhere," says Modarres. "The network services gateway has physical and virtual form factors based on standard open compute."
Nuage is finding that businesses are benefitting from an SDN approach in surprising ways.
The company cites banks as an example that are forced by regulation to ensure that there are no security holes at their remote locations. One bank with 400 branches periodically sends individuals to each to check the configuration to ensure no human errors in its set-up could lead to a security flaw. With 400 branches, this procedure takes months and is costly.
With SDN and its policy-level view of all locations - what each site and what each group can do - there are predefined policy templates. There may be 10, 20 or 30 templates but they are finite, says Modarres: "At the push of a button, an organisation can check the templates, daily if needed".
This is not why a bank will adopt SDN, says Modarres, but the compliance department will be extremely encouraging for the technology to be used, especially when it saves the department millions of dollars in ensuring regulatory compliance.
Nuage Networks says it has 15 customer wins and 60 ongoing trials globally for its products. Customers that have been identified include healthcare provider UPMC, financial services provider BBVA, cloud provider Numergy, hosting provider OVH, infrastructure providers IDC Frontier and Evonet, and telecom providers TELUS and NTT Communications.
Ciena offers enterprises vNF pick and choose
Ciena, working with partners, has developed a platform for service providers to offer enterprises network functions they can select and configure with the click of a button.
Dubbed Agility Matrix, the product enables enterprises to choose their IT and connectivity services using software running on servers. It also promises to benefit service providers' revenues, enabling more adventurous service offerings due to the flexibility and new business models the virtual network functions (vNFs) enable. Currently, managed services require specialist equipment and on-site engineering visits for their set-up and management, while the contracts tend to be lengthy and inflexible.
"It offers an ecosystem of vNF vendors with a licensing structure that can give operators flexibility and vendors a revenue stream," says Eric Hanselman, chief analyst at 451 Research. "There are others who have addressed the different pieces of the puzzle, but Ciena has wrapped the products with the business tools to make it attractive to all of the players involved."
Ciena has created an internal division, dubbed Ciena Agility, to promote the venture. The unit has 100 staff while its technology, Agility Matrix, is being trialled by service providers although Ciena has declined to say how many.
"Why a separate devision? To move fast in a market that is moving rapidly," says Kevin Sheehan, vice president and general manager of Ciena Agility.
The unit inherits Agility products previously announced by Ciena. These include the multi-layer WAN controller that Ciena is co-developing with Ericsson, and certain applications that run on the software-defined networking (SDN) controller.
"The unique aspect of Ciena’s offering is the comprehensive approach to virtualised functions, says Hanselman. "It tackles everything from service orchestration out to monetisation."
 Source: Ciena
Source: Ciena
What has been done
Agility Matrix comprises three elements: the vNF Market, Director and the host. The vNF Market is cloud-based and enables a service provider to offer a library of vNFs that its enterprise customers can choose from. An enterprise IT manager can select the vNFs required using a secure portal.
The Director, the second element, does the rest. The Director, built using Openstack software, delivers the vNFs to the host, an x86 instruction set-based server located at the enterprise's premises or in the service provider's central office or data centre.
The Director generates a software licence, the enterprise customer confirms the vNFs are working, which prompts the Director to generate post-payment charging data records. The VNF Market then invoices the service provider and pays the vNF vendors selected.
"Agility Matrix enables a pay-as-you-earn model for the service provider, much different from today's managed services providers' experiences," says Sheenan, who points out that a service provider currently buys custom hardware in bulk based on their enterprise-demand forecast, shipping products one by one. Now, with Agility Matrix, the service provider pays for a licence only after its enterprise customer has purchased one.
Ciena has launched Agility Matrix with five vNF partners. The partners and their vNF products are shown in the table.
 Source: Gazettabyte
Source: Gazettabyte
AT&T Domain 2.0 programme
Ciena is one of the vendors selected by AT&T for its Supplier Domain 2.0 programme. Does AT&T's programme influence this development?
“We are always working with our customers on addressing their current and future problems," says Sheehan. "When we bring something like Agility Matrix to the market, it is created by working with our partners and customers to develop a solution that is designed to meet everyone’s needs."
"Ciena has application programming interfaces that can support integration at several levels, but it is not clear that Agility is part of the deployment within Domain 2.0," says Hanselman. "The interesting things in Domain 2.0 are the automation and virtualisation pieces; Ciena can handle the automation part with its existing products."
Meanwhile, AT&T has announced its 'Network on Demand' that enables businesses to add and change network services in 'near real-time' using a self-service online portal.
Huawei joins imec to research silicon photonics
Huawei has joined imec, the Belgium nano-electronics research centre, to develop optical interconnect using silicon photonics technology. The strategic agreement follows Huawei's 2013 acquisition of former imec silicon photonics spin-off, Caliopa.
 Source: Gazettabyte
Source: Gazettabyte
“Having acquired cutting-edge expertise in the field of silicon photonics thanks to our acquisition of Caliopa last year, this partnership with imec is the logical next move towards next-generation optical communication,” says Hudson Liu, CEO at Huawei Belgium.
Imec's research focus is to develop technologies that are three to five years away from production. "Imec works with leading IC manufacturers and fabless companies in the field of CMOS fabrication," says Philippe Absil, department director for 3D and optical technologies at imec. "One of the programmes with our co-partners is about optical interconnect and silicon photonics, and Huawei is one of the participating companies."
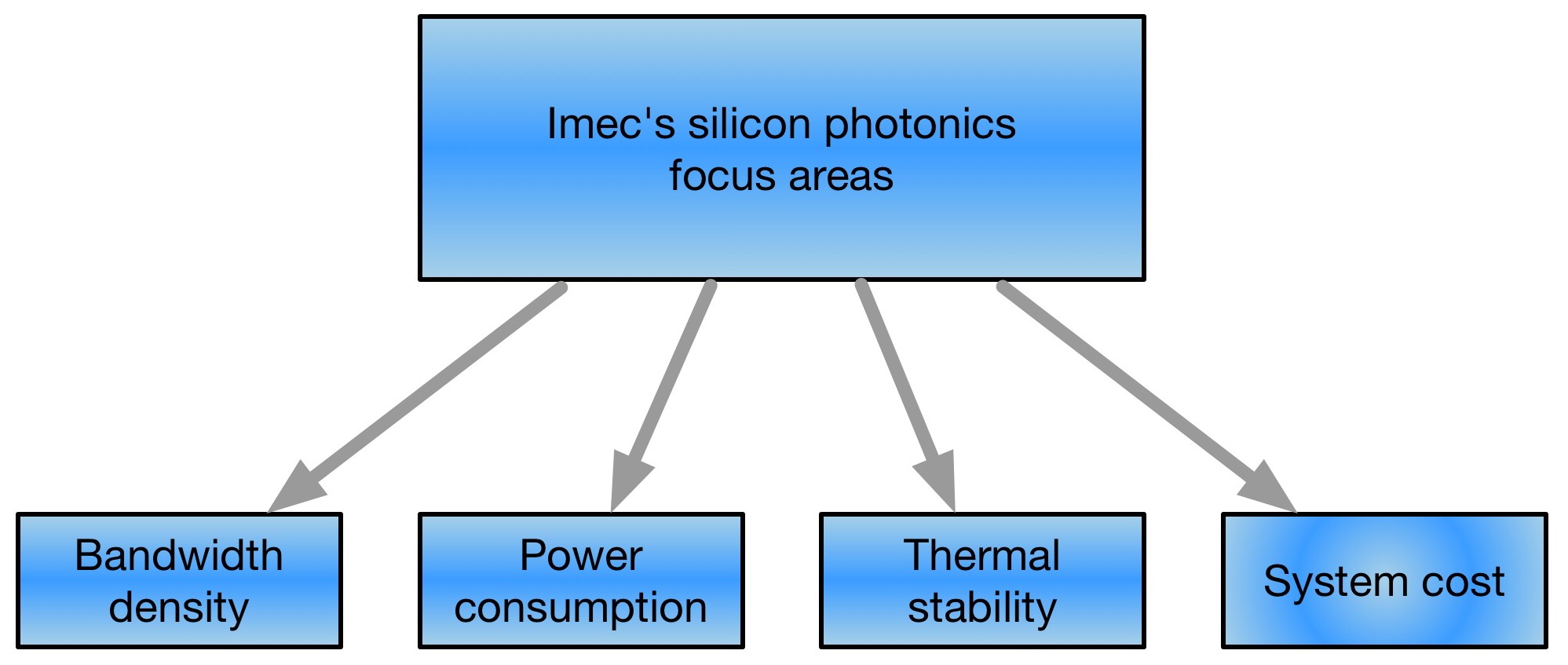
Imec's research concentrates on board-to-board and chip-to-chip interconnect. The optical interconnect work includes increasing interface bandwidth density, reducing power consumption, and achieving thermal stability and system-cost reduction.
The research centre has demonstrated high-bandwidth interfaces as part of work with Chiral Photonics that makes multi-core fibre. Imec has developed a 2D ring of grating couplers that allow coupling between the silicon photonics chip and Chiral's 61-core fibre. "A grating coupler is a sub-wavelength structure that diffracts the light from a waveguide in a vertical direction towards the fibre above the chip," says Absil. This contrasts to traditional edge coupling to a device, achieved by dicing or cleaving a facet on the waveguide, he says.
Another research focus is how to reduce device power consumption and achieve thermal stability. One silicon photonics component that dictates the overall power consumption is the modulator, says Absil. "The Mach-Zehnder modulator is known to consume significant amounts of power for chip-to-chip distances," he says. "The alternative is to use resonating-based modulators but these have to be thermally controlled, and that has an associated power consumption."
Imec is looking at ways to reduce the thermal control needed and is investigating the addition of materials to silicon to create resonator modulators that do away with the need for heating.
The system-cost reduction work looks at packaging. "Eventually, we want to get the optical transceiver inside a host IC," says Absil. "That package has to enable an optical pass-through, whether it is fibre or an optically-transparent package." Such a requirement differs from established CMOS packaging technology. "The programme is also looking to explore new types of packaging for enabling this optical pass-through," he says.
Absil says certain programme elements are two years away from being completed. "In the programme, we have topics that are closer to being adopted and some that are further away, maybe even to 2020."
Multi-project wafer service
Imec is part of the a consortium of EC research institutes that provide low-cost access to companies that don't have the means to manufacture their own silicon photonics designs. Known as Essential, the EC's Seventh Framework (FP7) programme is an extension of the ePIXfab silicon photonics multi-project wafer initiative. "Imec is offering one flavour of the technology, Leti is also offering a flavour, and then there is IHP and VTT," says Absil. Once the Essential FP7 project is completed, the service will be continued by the Europractice IC service.
Has imec seen any growth now that the funding for OpSIS, the multi-project wafer provider, has come to an end? "We see decent contributions but I wouldn't say it is exponential growth," says Absil, who notes that the A*STAR Institute of Microelectronics in Singapore that OpSIS used continues to offer a multi-project wafer service.
Status of silicon photonics
Despite announcements from Acacia and Intel, and Finisar revealing at ECOC '14 that it is now active in silicon photonics, 2014 has been a quiet year for the technology.
"Right now it is a bit quiet because companies are investing in development," says Absil. "There is not so much incentive to publish this work." Another factor he cites for the limited news is that there are vertically-integrated vendors that are putting the technology in their servers rather than selling silicon-photonics products directly.
"This is only first generation," says Absil. "As it picks up, there will be more incentive to work on a second generation of silicon photonics which will depart from what we know from the early work published by Intel and Luxtera."
The opportunities this next-generation technology will offer are 'quite exciting', says Absil.
Mobile fronthaul: A Q&A with LightCounting's John Lively
LightCounting Market Research' s report finds that mobile fronthaul networks will use over 14 million optical transceivers in 2014, resulting in a market valued at US $530 million. This is roughly the size to the FTTX market. However, unlike FTTX, sales of fronthaul transceivers will nearly double in the next five years, to exceed $900 million. A Q&A with LightCounting's principal analyst, John Lively.

Q. What is mobile fronthaul?
There is a simple explanation for mobile front-haul but that belies how complicated it is.
The equipment manufacturers got together about 10 years ago and came up with the idea to separate the functionality within a base station. The idea is that if you separate the functionality into two parts, you can move some of it to the tower and thereby reduce the equipment, power and space needed in the hut below. That is the distributed base station.
So instead of a large chassis base station, the current equipment is in two: a baseband unit or BBU which is a smaller rack-mounted unit, and the remote radio unit (RRU) or sometimes the remote radio head, mounted at the top of the tower, next to the antennas. The link between the two units is defined as fronthaul.
Q. What role does optics have in mobile fronthaul?
In the old monolithic base station, the connection between the two parts was an inch or two of copper. Once you have half the equipment up on the tower, obviously a few inches of copper is not going to suffice.
They found that copper is a poor choice even if the BBU is at the bottom of the tower. Because the signal between the two is a radio frequency analogue one, the signal is not compressed and so has a fairly high bandwidth.
One statistic I saw is that if you use copper cable instead of fibre, the difference between the two just in terms of weight is 13x. And there are things to consider like the wind load and ice load on these towers. So you want small diameter, lightweight cables. So even if there were no considerations of distance, there are basic physical factors that favour fibre for this link. That is the genesis of fronthaul.
But then people realised: We have a fibre connection, we can move the BBU; now we can go tens of kilometers if we want to. Operators can then consider aggregating BBUs in central locations that serve multiple radio macrocells. This is called centralised RAN.
Centralised RAN reduces cost simply by saving real-estate, space and power. With the right equipment, you can also allocate processing capacity dynamically among multiple cells and realise greater efficiencies.
So there are layers of benefits to fronthaul. It starts with simple things like weight and the inability to shed ice, getting down to annual operating costs and the investment needed in future wireless capacity. Fronthaul is a concept with much to offer.
Q. What is driving mobile fronthaul adoption?
What has brought fronthaul to the fore has been the global deployment of LTE. Fronthaul is not LTE-specific; distributed base station equipment has been available for HSPA and other 3G equipment. But in the last 3-4 years, we have had a massive upgrade in global infrastructure with many operators installing LTE. It is that that has driven the growth in fronthaul, taking it from a niche to become a mainstream part of the network.
Q. What are the approaches for mobile fronthaul?
The fronthaul that we have heard about from component vendors is simple point-to-point grey optics links. But let me start by defining CPRI. As part of the development of distributed base stations, a bunch of equipment vendors defined a way the signals would be transmitted between the BBU and the RRU, and it is called the Common Public Radio Interface or CPRI. As part of the specification, they define minimum requirements from the optical links, and they go so far as to say that these can be met with existing optics including several Fibre Channel devices.
As part of LightCounting's vendor surveys, we know that the predominant mode of implementation of fronthaul today is grey optics. That paints one picture: fronthaul is simple point-to-point grey optics. Some of the largest deployments recently have been of that mode, with China Mobile being the flagship example.
However, grey optics is not the only scheme, and some mobile operators have opted to do it differently.
A competing scheme is simple wavelength-division multiplexing (WDM) - a coarse WDM multi-channel coloured optical system. It is obviously simpler than long-haul: not 80 channels of closely spaced lambdas but systems more like first-generation WDM long-haul of 10 or 15 years ago, using 16 channels.
At first glance, it appears that the WDM approach is a next-generation scheme. But that is not the case; it has been deployed. South Korea's SK Telecom has used a WDM fronthaul solution when building their LTE network.
Q. Is it clear what operators prefer?
Both schemes have pros and cons. If there is a scarcity of fibre, you are leasing fibre from a third party for example, every additional fibre you use costs money. Or you have to deploy new fibre which is super expensive. Then a WDM solution looks attractive.
Another benefit, which is interesting, is that if you are a third-party provider of fronthaul, such as a tower company or a cable operator that wants to provide fronthaul just as it provides mobile backhaul, you need a demarcation point so that when there is a problem, you can say where your responsibility begins and ends.
There is no demarcation point with point-to-point links, it is just fibre running directly from operator equipment from Point A to Point B. With WDM systems, you have a natural demarcation point: the add/ drop nodes where the signals get onto the WDM wavelengths.
For example, a tower may serve three operators. Each operator would then used short-reach grey optics from their RRU to connect to the add/ drop node that may be at the bottom or on the tower. Otherwise, when there is a fault, who is responsible? That is another advantage of the WDM scheme.
It is not unlike the situation with fibre-to-the-x: some places have fibre-to-the-home, some fibre-to-the-curb, some fibre-to-the basement. There are different scenarios having to do with density, operator environment or regulation that create different optimal solutions for each scenario. There is no one-size-fits-all.
Q. What optical modules are used for mobile fronthaul and how will this change over the next five years?
The RRHs typically require 3 or 6 Gigabit-per-second (Gbps). These are CPRI standard rates that are multiples of a basic base rate. In some cases when they are loaded up with multiple channels - daisy chaining the RRUs - you may require 10Gbps.
From our survey data, in 2013 the mix was 3 and 6Gbps devices primarily, and this year we saw a shift away from 3 and more towards 6 and 10 Gbps. We believe that was skewed to some degree by China Mobile, which in many areas is putting up high capacity LTE systems with multiple channels, unlike many other operators that are doing a LTE multi-phase deployment, lighting one channel to start with and adding capacity as needed.
There is also some demand for 12.5Gbps but nothing beyond that, and 12.5Gbps demand is rather small and unlikely to grow quickly. That is because the individual RRHs are not going up in capacity. Rather, the way that capacity keeps up with bandwidth is that the number of RRHs multiplies. The way fronthaul keeps up with bandwidth demand is mainly by the proliferation of links rather than increasing the speed of individual links.
Q. A market nearly doubling in five years, that is a healthy optical component segment?
The growth is good. But like everything in optical components, it is questionable whether vendors will find a way to make it profitable. The technology specifications are not particularly challenging, so you can expect competition to be pretty severe for this market.
We are already seeing several Chinese makers with low manufacturing costs establishing themselves among the top suppliers in this market.
Q. Besides market size, what were other findings of the report?
I do expect WDM systems to become more widespread over the next five years. It makes sense that not everyone will want to do the brute force method of a link for every RRU out there. This is probably the biggest area of uncertainty, too: to what extent will WDM catch up or displace first generation grey optics?
The other thing to think about is what happens next? LTE deployments are well underway, a bit more than half way done worldwide. And it will be at least 5 years before the next big cycle: people are only just starting to talk about 5G. What is fonthaul going to look like in a 5G system?
It is hard to answer that in any clarity because 5G systems are not yet defined. What I find fascinating is that they are talking about multi-service access networks instead of fixed and mobile broadband being separate.
With WDM-PON and other advanced access networks, there is a growing belief that fronthaul could be carried over existing networks rather than having purpose-built fronthaul and backhaul networks. Fronthaul may thus go away and just be a service that tags onto some other networking equipment in the 5-10 year timeframe.
Q. Did any of the findings surprise you?
One is the fact that WDM is being deployed today.
Another is the size of the market: the component revenues are as big as FTTx. If you think about it, it makes sense: they are both serving consumers and are similar types of applications in terms of what they are doing: one is fixed broadband and one is mobile broadband.
Q. What are the developments to watch in the next few years regarding mobile fronthaul?
The next five years, the key thing to watch is the adoption of WDM in lieu of point-to-point grey optics. Beyond that, for the next generation, what fronthaul will be needed in 5G networks?
OpenCL and the reconfigurable data centre
Part 3: General purpose data centres
Xilinx's adoption of the Open Computing Language (OpenCL) as part of its SDAccel development tool is important, not just for FPGAs but also for the computational capabilities of the data centre.
The FPGA vendor is promoting its chips as server co-processors to tackle complex processing tasks such as image searches, encryption, and custom computation.
Search-engine specialists such as Baidu and Microsoft have seen a greater amount of traffic for image and video searches in the last two years, says Loring Wirbel, senior analyst at market research firm, The Linley Group: "All of a sudden they are seeing that these accelerator cards as being necessary for general-purpose data centres."
Xilinx and Altera have been way ahead of the niche FPGA vendors, indeed ahead of a lot of the network processor and graphics processor (GPU) vendors, in recognising the importance of OpenCL
OpenCL was developed by Apple and is being promoted by the Khronos Group, an industry consortium set up to promote the integration of general purpose microprocessors, graphics processors, and digital signal processing blocks. And it is the FPGA vendors that are playing a pivotal role in OpenCL's adoption.
"Xilinx and Altera have been way ahead of the niche FPGA vendors, indeed ahead of a lot of the network processor and graphics processor (GPU) vendors, in recognising the importance of OpenCL," says Wirbel.
Altera announced the first compiler kit for OpenCL in 2013. "The significant thing Altera did was develop 'channels' for accelerator 'kernels'. Using the channels, kernels - the tasks to be accelerated in hardware - communicate with each other without needing the host processor. "It offers an efficient way for multiple co-processors to talk to each other," says Wirbel. The OpenCL community have since standardised elements of Altera's channels, now referred to as pipes.
"What Xilinx has brought with SDAccel is probably more significant in that it changes the design methodology for bringing together CPUs and GPUs with FPGAs," says Wirbel. Xilinx's approach may be specific to its FPGAs but Wirbel expects other firms to adopt a similar design approach. "Xilinx has created a new way to look at design that will ease the use of parallelism in general, and OpenCL," says Wirbel. (see SDAccel design approach, below.)
"Altera and Xilinx should be saluted in that they have encouraged people to start looking at OpenCL as a move beyond C for programming everything," says Wirbel. This broadening includes programming multi-core x86 and ARM processors, where a good parallel language is desirable. "You get better performance moving from C to C++, but OpenCL is a big jump," he says.
The future says that every data centre is going to become an algorithmically-rich one that can suddenly be reallocated to do other tasks
Wirbel does not have hard figures as to how many of a data centre's servers will have accelerator cards but he believes that every data centre is going to have specialised acceleration for tasks such as imaging and encryption as a regular feature within the next year or two. His educated guess is that it will be one accelerator card per eight host CPUs and possibly one in four.
Longer terms, such acceleration will change the computational nature of the data centre. "The future says that every data centre is going to become an algorithmically-rich one that can suddenly be reallocated to do other tasks," he says. It could mean that institutions such as national research labs that tackle huge-scale simulation work may no longer require specialist supercomputer resources.
"That is a little bit exaggerated because what will really happen is you will have to have whole clusters of data centres around the country allocated to ad-hoc virtual multiprocessing on very difficult problems," says Wirbel. "But the very notion that there needs to be assigned computers in data centres to one set of problems will be a thing of the past."
How does that relate to Xilinx's SDAccel and OpenCL?
"Some of this will happen because of tools like OpenCL as the language and tools like SDAccel for improving FPGAs," says Wirbel.
The SDAccel design approach
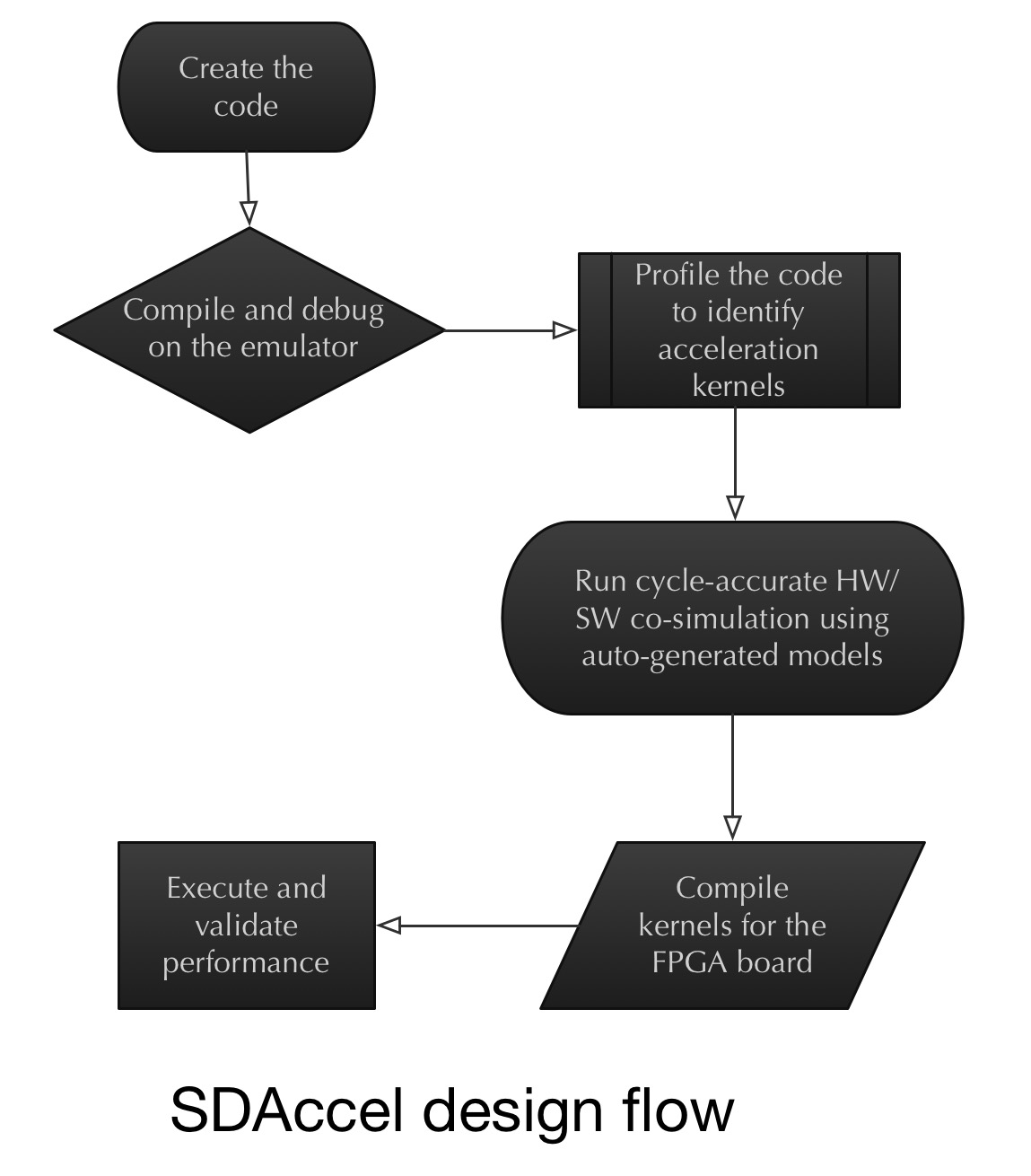
Xilinx has adopted the concept of co-simulation at an early stage of an FPGA-based co-processor design, alongside a server's x86 processor.
Wirbel says that despite all the talk about co-simulation over the last decade, little has been done in practice. With co-simulation, an x86 processor or a graphics processor is simulated with a designer's IP logic that makes up an ASIC or an FPGA design.
Making FPGAs with very tightly-packed processors and with a very low power dissipation is critical; it is a big deal
"What Xilinx did is they said: the biggest problem is designers having to redo an FPGA, even placing and routing elements and going back to using back-end EDA [electronic design automation] tools," says Wirbel. "Maybe the best way of doing this is recognising we have to do some early co-simulation on a target x86 CPU board."
This is where OpenCL plays a role.
"The power of OpenCL is that it lets you define an acceleration task as a kernel," says Wirbel. It is these acceleration kernels that are sent to the hardware emulator with the x86 on board. The kernels can then be viewed in the co-simulation environment working alongside the x86 such that any problems encountered can be tackled, and the two optimised. "Then, and only then, do you send it to a compiler for a particular FPGA architecture."
The challenge for Xilinx is keeping a lid on the FPGA accelerator card's power consumption given the huge number of servers in a data centre.
"The large internet players have got to be able to add these new features for almost zero extra power," says Wirbel. "Making FPGAs with very tightly-packed processors and with a very low power dissipation is critical; it is a big deal."
For Part 1, click here
For Part 2, click here
What role FPGA server co-processors for virtual routing?
IP routing specialists have announced first virtual edge router products that run on servers. These include Alcatel-Lucent with its Virtualized Service Router and Juniper with its vMX. Gazettabyte asked Alcatel-Lucent's Steve Vogelsang about the impact FPGA accelerator cards could have on IP routing.

Steve Vogelsang, IP routing and transport CTO, Alcatel-Lucent
The co-processor cards in servers could become interesting for software-defined networking (SDN) and network function virtualisation (NFV).
The main challenge is that we require that our virtualised network functions (vNFs) and SDN data plane can run on any cloud infrastructure; we can’t assume that any specific accelerator card is installed. That makes it a challenge.
I can imagine, over time, that DPDK, the set of libraries and drivers for packet processing, and other open source libraries will support co-processors, making it easier to exploit by an SDN data plane or vNF.
For now we’re not too worried about pushing the limits of performance because the advantage of NFV is the operational simplicity. However, when we have vNFs running at significant scale, we will likely evaluate co-processor options to improve performance. This is similar to what Microsoft and others are doing with search algorithms and other applications.
Note that there are alternative co-processors that are more focussed on networking acceleration. An example is Netronome which is a purpose-built network co-processor for the x86 architecture. Not sure how it compares to Xilinx for networking functionality, but it may outperform FPGAs and be a better option if networking is the focus.
Some servers are also built to enable workload-specific processing architectures. Some of these are specialised on a single processor architecture while others such as HP's Moonshot allow installation of various processors including FPGAs.
When we have vNFs running at significant scale, we will likely evaluate co-processor options to improve performance
I don’t expect FPGA accelerator cards will have much impact on network processors (NPUs). We or any other vendor could build an NPU using a Xilinx or another FPGA. But we get much more performance by building our own NPU because we control how we use the chip area.
When designing an FPGA, Xilinx and other FPGA vendors have to decide how to allocate chip space to I/O, processing cores, programmable logic, memory, and other functional blocks. The resulting structure can deliver excellent performance for a variety of applications, but we can still deliver considerably more performance by designing our own chips allocating the chip space needed to the required functions.
I have experience with my previous company which built multiple generations of NPUs using FPGAs, but they could not come close to the capabilities of our FP3 chipset.
For Part 1, click here
For Part 3, click here
FPGAs embrace data centre co-processing role
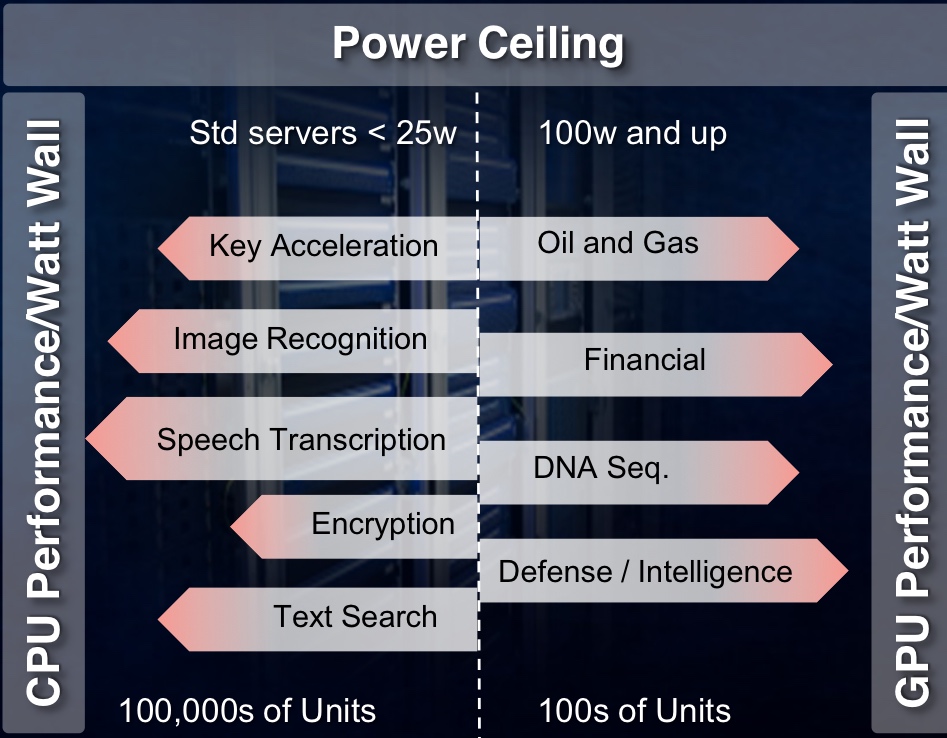 The PCIe accelerator card has a power budget of 25W. Hyper data centres can host hundreds of thousands of servers whereas other industries with more specialist computation requirements use far fewers servers. As such, they can afford a higher power budget per card. Source: Xilinx
The PCIe accelerator card has a power budget of 25W. Hyper data centres can host hundreds of thousands of servers whereas other industries with more specialist computation requirements use far fewers servers. As such, they can afford a higher power budget per card. Source: Xilinx
Xilinx has developed a software-design environment that simplifies the use of an FPGA as a co-processor alongside the server's x86 instruction set microprocessor.
Dubbed SDAccel, the development environment enables a software engineer to write applications using OpenCL, C or the C++ programming language running on servers in the data centre.
Applications can be developed to run on the server's FPGA-based acceleration card without requiring design input from a hardware designer. Until now, a hardware engineer has been needed to convert the code into the RTL hardware description language that is mapped onto the FPGA's logic gates using synthesis tools.
"[Now with SDAccel] you suffer no degradation in [processing] performance/ Watt compared to hand-crafted RTL on an FPGA," says Giles Peckham, regional americas and EMEA marketing director at Xilinx. "And you move the entire design environment into the software domain; you don't need a hardware designer to create it."
Data centre acceleration
The data centre is the first application targeted for SDAccel along with the accompanying FPGA accelerator cards developed by Xilinx's three hardware partners: Alpha Data, Convey and Pico Computing.
The FPGA cards connect to the server's host processor via the PCI Express (PCIe) interface are not just being aimed at leading internet content providers but also institutions and industries that have custom computational needs. These include oil and gas, financial services, medical and defence companies.
PCIe cards have a power budget of 25W, says Xilinx. The card's power can be extended by adding power cables but considering that hyper data centres can have hundreds of thousands of servers, every extra Watt consumed comes at a cost.
Microsoft has reported that a production pilot it set up that had 1,632 servers using PCIe-based FPGA cards, achieved a doubling of throughput, a 29 percent lower latency, and a 30 percent cost reduction compared to servers without accelerator cards
In contrast, institutions and industries use far fewer servers in their data centres. "They can stomach the higher power consumption, from a cost perspective and in terms of dissipating the heat, up to a point," says Peckham. Their accelerator cards may consume up to 100W. "But both have this limitation because of the power ceiling," he says.
China’s largest search-engine specialist, Baidu, uses neural-network processing to solve problems in speech recognition, image search, and natural language processing, according to The Linley Group senior analyst, Loring Wirbel.
Baidu has developed a 400 Gigaflop software-defined accelerator board that uses a Xilinx Kintex-7 FPGA that plugs into any 1U or 2U high server using PCIe. Baidu says that the FPGA board achieves four times higher performance than graphics processing units (GPUs) and nine times higher performance than CPUs, while consuming between 10-20W.
Microsoft has reported that a production pilot it set up that had 1,632 servers using PCIe-based FPGA cards, achieved a doubling of throughput, a 29 percent lower latency, and a 30 percent cost reduction compared to servers without accelerator cards.
"The FPGA can implement highly parallel applications with the exact hardware required," says Peckham. Since the dynamic power consumed by the FPGA depends on clock frequency and the amount of logic used, the overall power consumption is lower than a CPU or GPU. That is because the FPGA's clock frequency may be 100MHz compared to a CPU's or GPU's 1 GHz, and the FPGA implements algorithms in parallel using hardware tailored to the task.
 FPGA processing performance/ W for data centre acceleration tasks compared to GPUs and CPUs. Note the FPGA's performance/W advantage increases with the number of software threads. Source: Xilinx
FPGA processing performance/ W for data centre acceleration tasks compared to GPUs and CPUs. Note the FPGA's performance/W advantage increases with the number of software threads. Source: Xilinx
SDAccel
To develop a design environment that a software developer alone can use, Xilinx has to make SDAccel aware of the FPGA card's hardware, using what is known as a board support package. "There needs to be an understanding of the memory and communications available to the FPGA processor," says Peckham. "The processor then knows all the hardware around it."
Xilinx claims SDAccel is the industry's first architecturally optimising compiler for FPGAs. "It is as good as hand-coding [RTL]," says Peckham. The tool also delivers a CPU-/ GPU-like design environment. "It is also the first tool that enables designs to have multiple operations at different times on the same FPGA," he says. "You can reconfigure the accelerator card in runtime without powering down the rest of the chip."
SDAccel and the FPGA cards are available, and the tool is with several customers. "We have proven the tool, debugged it, created a GUI as opposed to a command line interface, and have three FPGA boards being sold by our partners," says Peckham. "More partners and more boards will be available in 2015."
Peckham says the simplified design environment appeals to companies not addressing the data centre. "One company in Israel uses a lot of Virtex-6 FPGAs to accelerate functions that start in C code," he says. "They are using FPGAs but the whole design process is drawn-out; they were very happy to learn that [with SDAccel] they don't have to hand-code RTL to program them."
Xilinx is working to extend OpenCL for computing tasks beyond the data centre. "It is still a CPU-PCIe-to-co-processor architecture but for wider applications," says Peckham.
For Part 2, click here
For Part 3, click here
North American operators in an optical spending rethink
Optical transport spending by the North American operators dropped 13 percent year-on-year in the third quarter of 2014, according to market research firm Dell'Oro Group.
Operators are rethinking the optical vendors they buy equipment from as they consider their future networks. "Software-defined networking (SDN) and Network Functions Virtualisation (NFV) - all the futuristic next network developments, operators are considering what that entails," says Jimmy Yu, vice president of optical transport research at Dell’Oro. "Those decisions have pushed out spending."
NFV will not impact optical transport directly, says Yu, and could even benefit it with the greater signalling to central locations that it will generate. But software-defined networks will require Transport SDN. "You [as an operator] have to decide which vendors are going to commit to it [Transport SDN]," says Yu.
SDN and NFV - all the futuristic next network developments, operators are considering what that entails. Those decisions have pushed out spending
The result is that the North American tier-one operators reduced their spending in the third quarter 2014. Yu highlights AT&T which during 2013 through to mid 2014 undertook robust spending. "What we saw growing [in that period] was WDM metro equipment, and it is that spending that has dropped off in the third quarter," says Yu. For equipment vendors Ciena and Fujitsu that are part of AT&T's Domain 2.0 supplier programme, the Q3 reduced spending is unwelcome news. But Yu expects North American optical transport spending in 2015 to exceed 2014's. This, despite AT&T announcing that its capital expenditure in 2015 will dip to US $18 billion from $21 billion in 2014 now that its Project VIP network investment has peaked.
But Yu says AT&T has other developments that will require spending. "Even though AT&T may reduce spending on Project VIP, it is purchasing DirecTV and the Mexican mobile carrier, lusacell," he says. "That type of stuff needs network integration." AT&T has also committed to passing two million homes with fibre once it acquires DirecTV.
Verizon is another potential reason for 2015 optical transport growth in North America. It has a request-for-proposal for metro DWDM equipment and the only issue is when the operator will start awarding contracts. Meanwhile, each year the large internet content providers grow their optical transport spending.
Dell'Oro expects 2014 global optical transport spending to be flat, with 2015 forecast to experience three percent growth
Asia Pacific remains one of the brighter regions for optical transport in 2014. "Partly this is because China is buying a lot of DWDM long-haul equipment, with China Mobile being one of the biggest buyers of 100 Gig," says Yu. EMEA continues to under-perform and Yu expects optical transport spending to decline in 2014. "But there seems to be a lot of activity and it's just a question of when that activity turns into revenue," he says.
Dell'Oro expects 2014 global optical transport spending to be flat compared to 2013, with 2015 forecast to experience three percent growth. "That growth is dependent on Europe starting to improve," says Yu.
One area driving optical transport growth that Yu highlights is interconnected data centres. "Whether enterprises or large companies interconnecting their data centres, internet content providers distributing their networks as they add more data centres, or telecom operators wanting to jump on the bandwagon and build their own data centres to offer services; that is one of the more interesting developments," he says.
Alcatel-Lucent serves up x86-based IP edge routing
Alcatel-Lucent has re-architected its edge IP router functions - its service router operating system (SR OS) and applications - to run on Intel x86 instruction-set servers.
 Shown is the VSR running on one server and distributed across several servers. Source: Alcatel-Lucent.
Shown is the VSR running on one server and distributed across several servers. Source: Alcatel-Lucent.
The company's Virtualized Service Router portfolio aims to reduce the time it takes operators to launch services and is the latest example of the industry trend of moving network functions from specialist equipment onto stackable servers, a development know as network function virtualisation (NFV).
"It is taking IP routing and moving it into the cloud," says Manish Gulyani, vice president product marketing for Alcatel-Lucent's IP routing and transport business.
IP edge routers are located at the edge of the network where services are introduced. By moving IP edge functions and applications on to servers, operators can trial services quickly and in a controlled way. Services can then be scaled according to demand. Operators can also reduce their operating costs by running applications on servers. "They don't have to spare every platform, and they don't need to learn its hardware operational environment," says Gulyani
Alcatel-Lucent has been offering two IP applications running on servers since mid-year. The first is a router reflector control plane application used to deliver internet services and layer-2/ layer-3 virtual private networks (VPNs). Gulyani says the application product has already been sold to two customers and over 20 are trialling it. The second application is a routing simulator used by customers for test and development work.
More applications are now being made available for trial: a provider edge function that delivers layer-2 and layer-3 VPNs, and an application assurance application that performs layer-4 to layer-7 deep-packet inspection. "It provides application level reporting and control," says Gulyani. Operators need to understand application signatures to make decisions based on which applications are going through the IP pipe, he says, and based on a customer's policy, the required treatment for an app.
Additional Virtualized Service Router (VSR) software products planned for 2015 include a broadband network gateway to deliver triple-play residential services, a carrier Wi-Fi solution and an IP security gateway.
Alcatel-Lucent claims a two rack unit high (2RU) server hosting two 10-core Haswell Intel processors achieves 160 Gigabit-per-second (Gbps) full-duplex throughput. The company has worked with Intel to determine how best to use the chipmaker's toolkit to maximise the processing performance on the cores.
"Using 16, 10 Gigabit ports, we can drive the full capacity with a router application," says Gulyani. "But as more and more [router] features are turned on - quality of service and security, for example - the performance goes below 100 Gigabit. We believe the sweet-spot is in the sub-100 Gig range from a single-server perspective."
In comparison, Alcatel-Lucent's own high-end network processor chipset, the FP3, that is used within its router platforms, achieves 400 Gigabit wireline performance even when all the features are turned on.
"With the VSR portfolio and the rest of our hardware platforms, we can offer the right combination to customers to build a performing network with the right economics," says Gulyani.
 Alcatel-Lucent's server router portfolio split into virtual systems and IP platforms. Also shown (in grey) are two platforms that use merchant processors on which runs the company's SR OS router operating system i.e. the company has experience porting its OS onto hardware besides its own FPx devices before it tackled the x86. Source: Alcatel-Lucent.
Alcatel-Lucent's server router portfolio split into virtual systems and IP platforms. Also shown (in grey) are two platforms that use merchant processors on which runs the company's SR OS router operating system i.e. the company has experience porting its OS onto hardware besides its own FPx devices before it tackled the x86. Source: Alcatel-Lucent.
Gazettabyte asked three market research analysts about the significance of the VSR announcement, the applications being offered, the benefits to operators, and what next for IP.
Glen Hunt, principal analyst, transport & routing infrastructure at Current Analysis
Alcatel-Lucent's full routing functionality available on an x86 platform enables operators to continue with their existing infrastructures - the 7750SR in Alcatel-Lucent's case - and expand that infrastructure to support additional services. This is on less expensive platforms which helps support new services that were previously not addressable due to capital expenditure and/ or physical restraints.
The edge of the service provider network is where all the services live. By supporting all services in the cloud, operators can retain a seamless operational model, which includes everything they currently run. The applications being discussed here are network-type functions - Evolved Packet Core (EPC), broadband network gateway (BNG), wireless LAN gateways (WLGWs), for example - not the applications found in the application layer. These functions are critical to delivering a service.
Virtualisation expands the operator’s ability to launch capabilities without deploying dedicated routing/ device platforms, not in itself a bad thing, but with the ability to spin up resources when and where needed. Using servers in a data centre, operators can leverage an on-demand model which can use distributed data centre resources to deliver the capacity and features.
Other vendors have launched, or are about to launch, virtual router functionality, and the top-level stories appear to be quite similar. But Alcatel-Lucent can claim one of the highest capacities per x86 blade, and can scale out to support Nx160Gbps in a seamless fashion; having the ability to scale the control plane to have multiple instances of the Virtualized Service Router (VSR) appear as one large router.
Furthermore, Alcatel-Lucent is shipping its VSR route reflector and the VSR simulator capabilities and is in trials with VSR provider edge and VSR application assurance – noting it has two contracts and 20-plus trials. This shows there is a market interest and possibly pent-up demand for the VSR capabilities.
It will be hard for an x86 platform to achieve the performance levels needed in the IP core to transit high volumes of packet data. Most of the core routers in the market today are pushing 16 Terabit-per-second of throughput across 100 Gigabit Ethernet ports and/ or via direct DWDM interfaces into an optical transport core. This level of capability needs specialised silicon to meet demands.
Performance will remain a key metric moving forward, even though an x86 is less expensive than most dedicated high performance platforms, it still has a cost basis. The efficiency which an application uses resources will be important. In the VSR case, the more work a single blade can do, the better. Also of importance is the ability for multiple applications to work efficiently, otherwise the cost savings are limited to the reduction in hardware costs. If the management of virtual machines is made more efficient, the result is even greater efficiency in terms of end-to-end performance of a service which relies on multiple virtualised network functions.
Ultimately, more and more services will move to the cloud, but it will take a long time before everything, if ever, is fully virtualised. Creating a network that can adapt to changing service needs is a lengthy exercise. But the trend is moving rapidly to the cloud, a combination of physical and virtual resources.
Michael Howard, co-founder and principal analyst, Infonetics Research
There is overwhelming evidence from the global surveys we’ve done with operators that they plan to move functions off the physical IP edge routers and use software versions instead.
These routers have two main functions: to handle and deliver services, and to move packets. I’ve been prodding router vendors for the last two years to tell us how they plan to package their routing software for the NFV market. Finally, we hear the beginnings, and we’ll see lots more software routing options.
The routing options can be called software routers or vRouters. The services functions will be virtualised network functions (VNFs), like firewalls, intrusion detection systems and intrusion prevention systems, deep-packet inspection, and caching/ content delivery networks that will be delivered without routing code. This is important for operators to see what routing functions they can buy and run in NFV environments on servers, so they can plan how to architect their new software-defined networking and NFV world.
It is important for router vendors to play in this world and not let newcomers or competitors take the business. Of course, there is a big advantage to buy their vRouter software — route reflection for example — from the same router vendor they are already using, since it obviously works with the router code running on physical routers, and the same software management tools can be used.
Juniper has just made its first announcement. We believe all router vendors are doing the same; we’ve been expecting announcements from all the router vendors, and finally they are beginning.
It will be interesting to see how the routing code is packaged into targeted use cases - we are just seeing the initial use cases now from Juniper and Alcatel-Lucent - like the route reflection control plane function, IP/ MPLS VPNs and others.
Despite the packet-processing performance achieved by Alcatel-Lucent using x86 processors, it should be noted that some functions like the control plane route reflection example only need compute power, not packet processing or packet-moving power.
There already is, and there will always be, a need for high performance for certain places in the network or for serving certain customers. And then there are places and customers where traffic can be handled with less performance.
As for what next for IP, the next 10 to 15 years will be spent moving to SDN- and NFV-architected networks, just as service providers have spent over 10 years moving from time-division multiplexing-based networks to packet-based ones, a transition yet to be finished.
Ray Mota, chief strategist and founder, ACG Research
Carriers have infrastructure that is complex and inflexible, which means they have to be risk-averse. They need to start transitioning their architecture so that they just program the service, not re-architect the network each time they have a new service. Having edge applications becoming more nimble and flexible is a start in the right direction. Alcatel-Lucent has decided to create a NFV edge product with a carrier-grade operating system.
It appears, based on what the company has stated, that it achieves faster performance than competitors' announcements.
Alcatel-Lucent is addressing a few areas: this is great for testing and proof of concepts, and an area of the market that doesn't need high capacity for routing, but it also introduces the potential to expand new markets in the webscaler space (that includes the large internet content providers and the leading hosting/ co-location companies).
You will see more and more IP domain products overlap into the IT domain; the organisationals and operations are lagging behind the technology but once service providers figure it out, only then will they have a more agile network.
STMicro chooses PSM4 for first silicon photonics product
- Lowers the manufacturing cost of optical modules
- Improves link speeds
- Reduces power consumption
 STMicro's in-house silicon photonics EDA. "We will develop the EDA tools to the level needed for the next generation products," says Flavio Benetti.
STMicro's in-house silicon photonics EDA. "We will develop the EDA tools to the level needed for the next generation products," says Flavio Benetti.