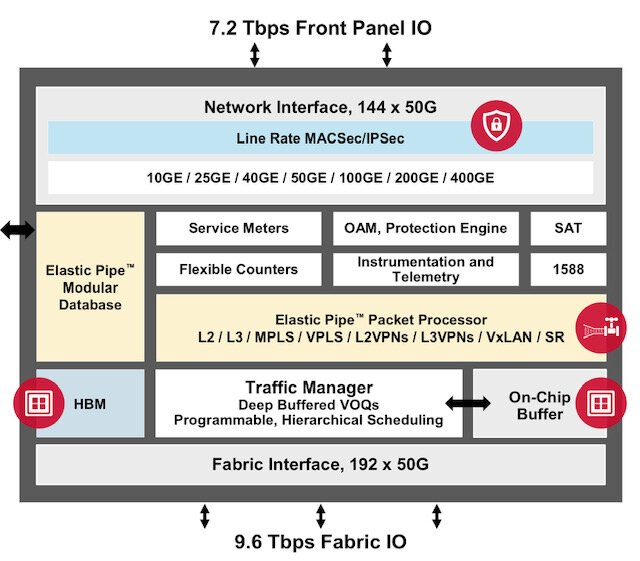
Broadcom’s 14.4-terabit Jericho2c+ router chip
The inexorable growth of IP traffic is being driven by ever more powerful devices being connected to the network and greater numbers of machines talking to each other.
In turn, Covid-19 has contributed its own traffic spike: AT&T reported that in September its core network traffic was 20 per cent up compared to March’s figures.
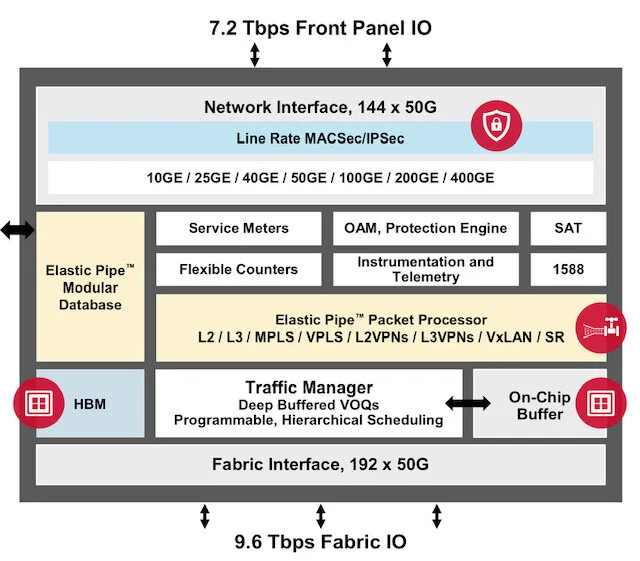
Jericho2c+ architecture. Source: Broadcom
The growth means that each new generation of router platform must at least double the traffic throughput while keeping the power consumption fixed.
This is a considerable challenge but one that the router chip designers continue to meet.
Jericho2c+
Broadcom announced recently its 14.4-terabit Jericho2c+ chip that increases router capacity threefold compared to the Jericho2c.
The Jericho2c+ is Broadcom’s third Jericho2 chip in just two years, samples of which are now with customers. Broadcom says the device should be qualified by year-end.
“The surprise is the generational cadence Broadcom is maintaining for the Jericho line,” says Bob Wheeler, vice president of The Linley Group and principal analyst for networking. “They remain committed to leading in chassis-based switch and router designs.”
Jericho2, a 9.6-terabit chip aimed at data centre router applications, was announced in 2018. The 4.8-terabit Jericho2c followed a year later, a derivative targeting the service-provider market.
Now, the Jericho2c+ triples throughput using a 7nm CMOS process instead of a 16nm used for the Jericho2c and has enabled Broadcom to boost the on-chip cores’ clock frequency.
“From an architecture standpoint, Jericho2c+ is an evolution of Jericho2, not Jericho2c,” explains Wheeler. “But yes, for Jericho2c customers, J2c+ does triple throughput.”
Router trends
Oozie Parizer, senior marketing director, Broadcom, says the company has played an important role in the telecom operators moving from router platforms using custom ASICs to platforms using merchant silicon.
“Recently we see more of this transitioning, not just to merchant silicon but also to white boxes,” says Parizer. This transition applies to core and edge routers.
“It has been possible because of the availability of merchant silicon to all, enabling a different price structure,” says Parizer. “All the OEMs are designing platforms; at the same time, some are maintaining their own [router] ASIC designs.” Router vendors developing ASICs include Cisco Systems, Juniper Networks and Nokia.
Telecom operators are keen for the established router vendors to use merchant silicon, says Parizer: “The carriers are buying into this story because they see what happened in data centers 10 years ago [with switching silicon].”
Wheeler sees a role for both custom ASICs and merchant silicon.
“The leading router OEMs remain committed to ASICs for their core routers; these are “halo” products meant to lead in features rather than being cost efficient,” he says. “Meanwhile, many of these same OEMs use Jericho for higher volume routers and transport platforms.”
Jericho architecture
The 14.4 terabit-per-second (Tbps) Jericho2c+ splits its interface capacity with 7.2Tbps facing the front panel and 7.2Tbps to Broadcom’s accompanying fabric chip, dubbed the Ramon. The Ramon is a cell-based switch chip that features 192, 50-gigabit serialiser/ deserialisers (serdes).
The fabric interface of the Jericho2c+ is indeed 9.6Tbps, the extra 2.4Tbps used for redundancy. “This is a carrier-grade system; they care about robustness,” says Parizer.
Should a line card fail, traffic is routed to a spare card to ensure continued traffic flow. The spare card may cover three working cards, but systems also use higher ratios: a spare card for every five, seven or even nine cards.
The Jericho2c+ has added on-chip security. “We have integrated MACSec and IPSec at line rate for all the network interfaces of the Jericho2c+,” says Gadi Singer, principal product manager at Broadcom.
Hyperscalers and service providers want to secure communications beyond their premises and integrating security hardware on each port reduces system cost and overall power consumption, says Singer.
Implementing a 14.4Tbps router with security and redundancy using two Jericho2C+ devices halves the power of a similar capacity platform using the Jericho2c. Such a design requires 21 chips: three Jericho2 ICs and the rest security ICs.
The Jericho2c+ doubles the number of meters while supporting more queues than previous Jericho devices. Meters and queues are used to enforce quality-of-service schemes to prioritise traffic flows and services.
“We wanted to ensure that even for the most demanding cases, we have sufficient meters and queues,” says Parizer.
The chip also features two stacked high-bandwidth memory (HBM) for packet buffering; 8 gigabytes of high-speed store in total.
Programmable pipeline
The Jericho devices feature a programmable pipeline.
A set of known features can always be implemented more efficiently with dedicated hardware; extra logic is needed to make the pipeline programmable. But a programmable pipeline can support different use cases. “You future-proof it for something that might come up after you design or even deploy the chip,” says Parizer.
The Jericho2c+ includes parsers and special function units for both the pipeline’s input and output paths.
There are also shared resources used by both pipeline paths: a modular database (MDB), a programmable element matrix (PEM), and the knowledge-based processor (KBP) external to the device.
The MDB uses one of several packet-processing database options that define the device’s profile, and which resides in a centralised memory pool.
The PEM is a programmable hardware block, effectively a small embedded FPGA. “It can solve futuristic scenarios not mapped into the device,” says Singer.
Meanwhile, the pipeline uses the KBP chip to extend its forwarding, counter and access-list capabilities. Broadcom gained the KBP after acquiring NetLogic in 2011.
Line cards and systems
Broadcom cites two line card configurations.
One, for service providers, is a 12.8-terabit N+1 redundancy fabric card that uses two Jericho devices and supports 32x400 Gigabit Ethernet (GbE) interfaces.
“It uses this knowledge-based processor to extend the forwarding scale, counters and the access list for edge and core router scenarios,” says Singer.
The second card, for the service provider edge, data centre interconnect and metro, uses two Jericho 2c+ devices connected back-to-back, acting as a single packet processing and traffic manager element.
The 14.4-terabit line card fits in a 1-rack-unit box and supports 36x400GbE ports.
Distributed disaggregated chassis
The Jericho2 is used for the distributed disaggregated chassis, a white box design that started when AT&T submitted its specifications to the Open Compute Project (OCP) over a year ago.
Last December, Drivenets announced a partnership with Broadcom and the original design manufacturers (ODMs) Ufispace, EdgeCore Networks and Delta to support the design. Since then, other third-party network operating system (NOS) players have backed the design.
Broadcom says that without AT&T, the white-box router would not have happened. “This is our entry into the core router market,” says Parizer.
And significantly, AT&T announced that part of its network backbone traffic is using such disaggregated core routing hardware running Drivenets’ software.
Jericho3 and Ramon2
Broadcom has started work on its next-generation Jericho and Ramon chips. The 5nm CMOS devices will use 100-gigabit serdes to double the throughput. The next Jericho device will also support 800-gigabit interfaces and 800-gigabit optics.
“We are investing a lot in design-for-power because that is one of the key things that enable our design wins,” says Parizer. “And we will update our pipeline and capabilities to address new requirements and integrate more into the device.”
Moore’s law
Parizer says Moore’s law has yet to slow down. “It hasn’t happened yet, look at the cadence of [foundry] TSMC moving from [CMOS] process to process: 7nm, 5nm, 3nm,” he says. “I can see two processes ahead; I’m relaxed for now.”
There are also chip industry developments such as die stacking where innovation is taking place.
“It is moving more and more of the line card and packaging its functionality into a device,” says Parizer. “This helps address some of the challenges.”

Open Eye gets webscale attention
Microsoft has trialled optical modules that use signalling technology developed by the Open Eye Consortium.
The webscale player says optical modules using the Open Eye’s analogue 4-level pulse-amplitude modulation (PAM-4) technology consume less power than modules with a PAM-4 digital signal processor (DSP).

Brad Booth
“Open Eye has shown us at least an ability that we can do better on power,” says Brad Booth, director, next cloud system architecture, Azure hardware systems and infrastructure at Microsoft, during an Open Eye webinar.
Optical module power consumption is a key element of the total power budget of data centres that can have as many as 100,000 servers and 50,000 switches.
“You want to avoid running past your limit because then you have to build another data centre,” says Booth.
But challenges remain before Open Eye becomes a mainstream technology, says Dale Murray, principal analyst at market research firm, LightCounting.
Open Eye MSA
When the IEEE standards body developed specifications using 50-gigabit PAM-4 optical signals, the assumption was that a DSP would be needed for signal recovery given the optics’ limited bandwidth.
But as optics improved, companies wondered if analogue circuitry could be used after all.
Such PAM-4 analogue chips would be similar to non-return-to-zero (NRZ) signalling chips used in modules, as would the chip assembly and testing, says Timothy Vang, vice president of marketing and applications, signal integrity products group, Semtech. The analogue chips also promised to be cheaper than DSPs.
This led to the formation of the Open Eye multi-source agreement (MSA) in January 2019. Led by MACOM and Semtech, the MSA now has 37 member companies.
“We felt that if we could enable that capability, you could use the same low-cost optics and, with an Open Eye specification - an eye-mask specification - you get a manufacturable low-cost ecosystem,” says Vang. “That was our goal and we were not alone.”
But a key issue is whether Open Eye solutions will work with existing DSP-based PAM-4 modules that have their own testing procedure.
“Can they eliminate all concerns for interoperability between analogue and DSP based modules without dual testing?” says Murray. “And will end users go with a non-standard solution rather than an IEEE-standard solution?”
“We do face the dilemma LightCounting points out,” says Vang. “It is possible there are poor or older DSP-based modules that wouldn’t pass the Open Eye test, and that could lead data centres to say: ‘Well, that is not good enough’.”

Dale Murray
“It is a concern,” says Microsoft’s Booth. The first Open Eye samples Microsoft received didn't talk to all the DSP-based modules, he says, but the next revision appeared to address the issue.
“Digital interfaces are certainly easier, but we're burning a lot of power with the DSPs, in the modules and the switch ASIC,” says Booth. “The switch ASIC needs it for direct attach copper (DAC) cables.”
However, the MSA believes that the cost, power and latency advantages of the Open Eye ICs will prove decisive.
Data centre considerations
Microsoft’s Booth outlined the challenges data centre operators face as bandwidth requirements grow exponentially.
The drivers for greater bandwidth include more home-workers using cloud services during the Covid-19 pandemic and the adoption of artificial intelligence and machine learning.
“With machine learning, the more machines you have talking to each other, the more intensive jobs you can handle,” says Booth. “But for distances greater than a few meters you fall into the realm of the 100m range, and that drives you to an optical solution.”
But optics are costly while going from 100-gigabit to 400-gigabit optical modules has not reduced power consumption. Booth says 400-gigabit SR8 modules consume about 10W while the 400-gigabit DR4 and FR4, it is 12W. Yet for 100-gigabit modules the power consumed is a quarter of these figures.
Low latency is another requirement if data centres are to adopt disaggregated servers where memory is pooled and shared between platforms. “Adding latency to these links, which are fairly short, is an impediment to do this disaggregation scenario,” says Booth.
Microsoft trialled an eight-lane on-board optics COBO module using Open-Eye and achieved a 30 per cent power saving compared to QSFP-DD or OSFP DSP-based pluggable modules.
Open Eye technology could also be used for co-packaged optics, promising a further 10 per cent power saving, says Booth.
Given future 51.2-terabit and 102.4-terabit switch silicon, with their significant connectivity, this will help reduce the overall thermal load and hence cooling which is part of a data centre’s overall power consumption.
“Anything that keeps that heat lower as I increase the bandwidth is an advantage,” says Booth.
Cost, power and latency
The Open Eye MSA claims it will cost a company $80 million to develop a next-generation 5nm CMOS PAM-4 DSP. Such a hefty development cost will need to be recouped, adding to a module's price.
Semtech says its Open Eye analogue ICs use a BiCMOS process which is a far cheaper approach.

Timothy Vang
The PAM-4 DSPs may consume more power, says Vang, but that will improve with newer CMOS processes. First-generation DSPs were implement using 16nm CMOS while the latest devices are at 7nm CMOS.
So the power advantage of Open Eye devices will shrink, says Vang, although Semtech claims its second-generation Open Eye devices will reduce power by 20 per cent.
Open Eye also has a latency advantage. Citing analysis from Nvidia (Mellanox), a PAM-4 DSP-based optical module adds 100ns of latency per link.
In a multi-hop network linking servers, the optical modules account for 40 per cent of the total latency, the rest being the switch, the network interface card and the optical flight time. Using Open Eye-based modules, the optical module portion shrinks to eight per cent only.
Specification status
The Open Eye MSA has specified 53-gigabit PAM-4 signalling for long-reach and short-reach optical links.
In particular, to its 200-gigabit FR4 specification, the MSA is adding 50-gigabit LR1, while an ER1 lite and 200-gigabit LR4 will be completed in early 2021. Meanwhile, the multi-mode 50-gigabit SR1, 200-gigabit SR4 and 400-gigabit SR8 specifications are done.
The third phase of the Open Eye work, producing a 100-gigabit PAM-4 specification, is starting now. Achieving the specification is important for Open Eye since modules are moving to 100-gigabit PAM-4, says Murray.

A 200-gigabit QSFP56-FR4 module block diagram. Source: CIG.
Products
Semtech is already selling 200-gigabit Open Eye short-reach chips, part of its Tri-Edge family. The two 4x50-gigabit devices are dubbed the GN2558 and GN2559.
The GN2558 is the transmitter chip. It retimes four 50-gigabit signals from the host and feeds them to the integrated VCSEL drivers that generate the optical PAM-4 signals sent over four fibres. The four photo-detector outputs are the receiver are then fed to the GN2559 that includes trans-impedance amplifiers (TIAs) and clock data recovery.
Equalisation is used within both devices. “The eye is opened on the transmitter as well as on the receiver; they equalise the signal in each direction,” says Vang.
The Semtech devices are being used for a 200-gigabit SR4 module and for a 400-gigabit SR8 active optical cable where two pairs of each chip are used.
Semtech will launch Tri-Edge long-reach Open Eye chips. The chips will drive externally-modulated lasers (EMLs), directly- modulated lasers (DMLs) and silicon photonics-based designs for single-mode fibre applications.
“We have early versions of these chips sampled and demonstrated,” says Vang. “In the Open Eye MSA, we have shown the chips interoperating with, for example, MACOM’s chipset.”
Semtech’s Tri-Edge solutions are in designs with over two dozen module customers, says Vang.
Meanwhile, pluggable module maker CIG detailed a 200-gigabit QSFP56-FR4 while Optomind discussed a 400-gigabit QSFP56-DD active optical cable design as part of the Open Eye webinar.

Silicon photonics webinar

Daryl Inniss and I assess how the technology and marketplace has changed since we published our silicon photonics book at the end of 2016. Click here to view the webinar. Ours is the first of a series of webinars that COBO, the Consortium of On-Board Optics, is hosting.

Xilinx’s Versal Premium ready for the 800-gigabit era
When Xilinx was created in 1984, the founders banked on programmable logic becoming ever more attractive due to Moore’s law.
Making logic programmable requires extra transistors so Xilinx needed them to become cheaper and more plentiful, something Moore’s law has delivered, like clockwork, over decades.
Since then, Xilinx’s field-programmable gate array (FPGA) devices have advanced considerably.
Indeed, Xilinx’s latest programmable logic family, the Versal Premium, is no longer referred to as an FPGA but as an adaptive compute accelerator platform (ACAP).
The Versal Premium series of chips, to be implemented using TSMC’s 7nm CMOS process, was unveiled for the OFC 2020 show. The Premium series will have seven chips with the largest, the VP1802, having 50 billion transistors.
First devices will ship in the second half of 2021.
ACAP series
Xilinx unveiled its adaptive compute acceleration platform in 2018.

Kirk Saban
“It is a complete rearchitecting of our device technology,” says Kirk Saban, vice president product and platform marketing at Xilinx. “It is heterogenous by nature and has multiple types of processing engines.”
“Versal Premium is evolutionary compared with previous FPGAs that have hardened blocks for certain functions,” says Bob Wheeler, principal analyst at The Linley Group. “It is another step along a continuum, not really new.”
Six ACAP families are planned for Versal: three tailored for artificial intelligence (AI) - the AI RF, AI Core and AI Edge - and the others being the Prime, Premium and HBM (high bandwidth memory).
Only Versal AI series will have AI engines: very-long-instructing-word (VLIW) processor cores that can also be used for computational-intensive tasks such as digital signal processing.
Premium is the third Versal family to be unveiled, joining the AI Core and Prime series.
Versal Prime is Xilinx’s broadest series in the portfolio, featuring a range of device sizes and capabilities. The Prime series is suited to such applications as storage acceleration in the data centre; wired networking such as 5G back-, mid- and front-haul, and passive optical networking; and industrial applications such as machine vision.
Networking needs
Versal Premium has been developed with core networking and data centre acceleration applications in mind.
“The top-end SKU handles high-end networking applications such as optical transport and data centre interconnect as well as the most demanding signal-processing applications such as radar systems,” says Wheeler.
Xilinx defines core networking as the infrastructure beyond the radio access network. “All the wireline infrastructure is what we consider to be the core of the network,” says Saban. “Access, metro, and core networks, all together.”
When Xilinx’s designers sat down to consider the networking needs for the coming six years, they anticipated a huge capacity hike in the core network. Device numbers are set to grow tenfold with each device generating ten times more traffic.
“The bandwidth going through the wired network globally needs to grow at 50 per cent on a compound annual basis to keep pace with the number of devices being connected and the data coming through them,” says Saban.
Versal Premium will deliver three times the bandwidth and nearly twice the logic capacity of the 16nm Virtex UltraScale+ VU13P FPGA, the largest device used currently for networking and data centre applications.
“Shifts are happening that the Virtex FPGAs are not going to be able to handle,” says Saban. “The move to 400 gigabit and then 800 gigabit on the mid-term horizon, the Virtex products can’t handle that kind of throughput.”
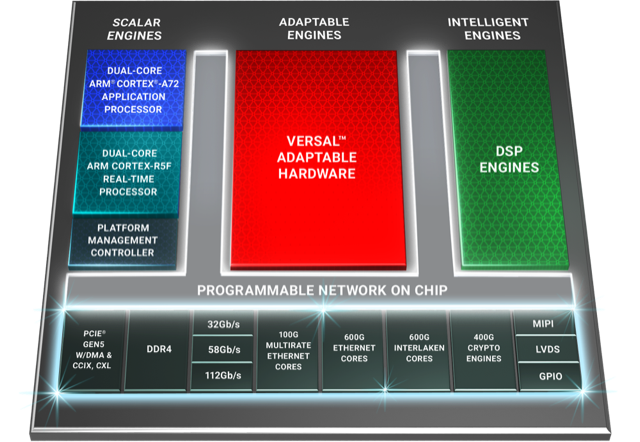
Versal Premium architecture. Source: Xilinx
Premium architecture
The Premium devices feature ARM-based scalar processors such as the dual-core Cortex-A72 application processor and the dual-core Cortex-R5F real-time processor.
The application processor is used for general-purpose processing and control. The real-time processor is used for applications that require deterministic processing. Such a processor is key for safety-certified applications.
Also included is a platform management controller that oversees the device. A user can configure many of the ACAP settings using a standard tool flow but the controller’s operation is effectively transparent to the user, says Saban.
The Premium features several types of on-chip memory that Saban likens to levels of cache memory used by high-performance processors. ”We have look-up-table RAM, Block RAM and Ultra RAM and we can offload to [external] DDR4 [RAM],” he says. “The memory hierarchy can be configured to match the algorithm you are building.”
The various on-chip functional blocks are linked via a programmable network-on-a-chip. Having the network-on-a-chip frees up programmable logic resources that would otherwise be required to connect the design’s functional blocks.
“Equipment manufacturers need to deliver on this core network growth but they also need to do it securely,” says Saban. “With everything shifting to the cloud, there are huge concerns about data privacy; in many instances, security is just as important as performance for the operators.”
To this aim, the Premium’s on-chip peripherals include 400-gigabit crypto-engines that support the AES-GCM-256 and -128, MACsec, and IPSec encryption standards.
“The crypto blocks are unique and save a lot of look-up tables and power compared with implementing these in programmable logic,” says Linley’s Wheeler.
Other on-chip features include up to 5 terabits of Ethernet throughput supporting rates from 10 to 400 Gigabit Ethernet. The devices have multiple 600-gigabit Ethernet MAC cores and support such protocols as FlexE, Flex-O, Ethernet CPRI (eCPRI), Fibre Channel over Ethernet (FCoE), and OTN.
The Premium family delivers up to 1.8 terabits of Interlaken, from 10-gigabit to 600-gigabit interfaces. Interlaken enables chip-to-chip and chip-to-backplane communications.
There are also 112-gigabit 4-level pulse-amplitude modulation (PAM-4) serialisers/ deserialisers (serdes). The VP1802 will have 28, 32-gigabit serdes and either 140, 58-gigabit or 70, 112-gigabit serdes. The electrical transceivers can drive 10m of copper cable, says Saban.
PCI Express Generation 5.0, enabling direct memory access and cache-coherent interconnect, is also supported on-chip. “We can connect to server CPUs and be an extension of their memory map,” says Saban.
Xilinx claims 22 UltraScale+ FPGAs would be needed to implement all the logic and peripherals of the Versal Premium VP1802.
System design
Wireline vendors want to double the performance with each generation of equipment while keeping platform size and power consumption constant.
Xilinx has a diagram (shown) of a generic telecom line-card design using the Versal Premium. “Vendors have different variants but at a high-level, they all look like this,” says Saban.
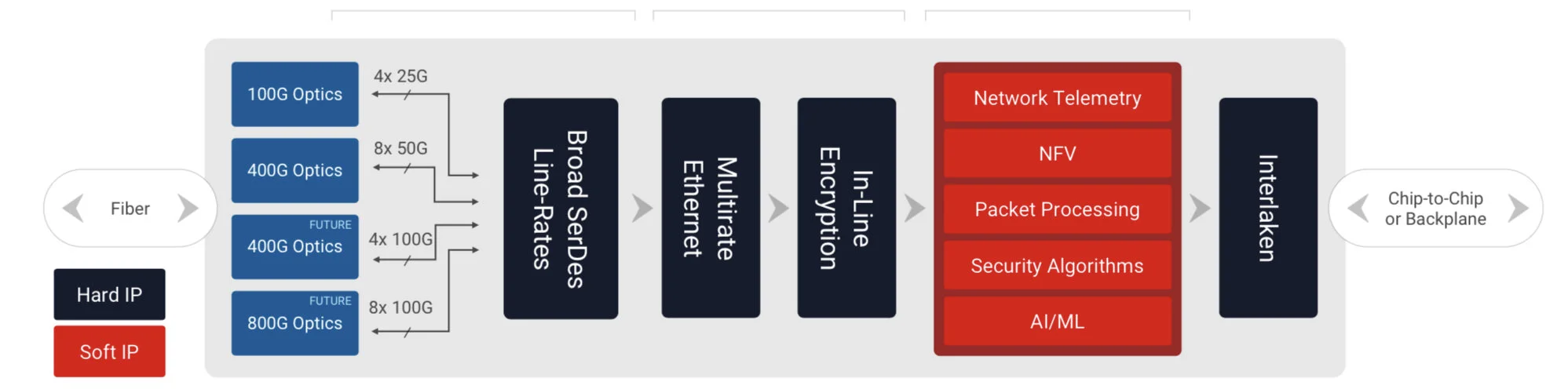
Generic telecom line card using the Versal Premium. Source: Xilinx
Line-card data arrives via optical modules. At present 100-gigabit is mainstream with 400-gigabit coming soon, and eventually 800-gigabit interfaces. The data is fed to the Premium’s hardened logic blocks: the Ethernet and encryption blocks.
The adaptive logic (in red) is what companies use to implement their unique designs such as executing virtualised network functions (NFV) or for packet processing.
“We are seeing the need to infuse artificial intelligence and machine learning into these applications in some capacity,” says Saban. Premium devices have no AI VLIW cores but have sufficient resources for some level of artificial intelligence/ machine learning capability.
Interlaken then sends the data to a host chip or across the backplane to another line card.
Software tools
Xilinx stresses the company is no longer a chip provider but a platform provider. This is reflected in the software tools it provides to accompany its silicon.
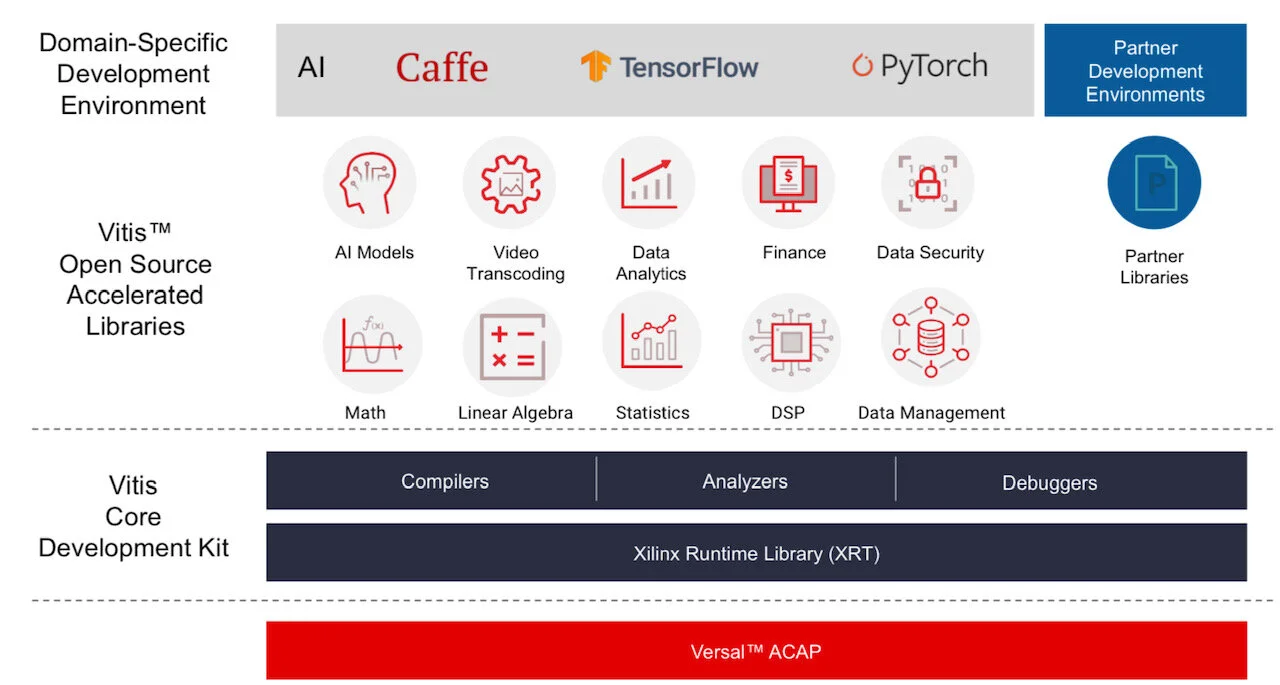
Vitis software tool. Source: Xilinx
Versal ACAPs come with advanced toolkit libraries so engineers can program the chip with no knowledge of the underlying hardware.
Xilinx is continuing to provide its Vivado toolset that supports register-transfer level (RTL), a design abstraction used by hardware engineers for their circuit designs. “The traditional RTL toolchain is not going away and will continue to evolve,” says Saban.
But coders developing data centre applications with no knowledge of RTL or programmable logic can now use Xilinx’s Vitis toolset that was launched in 2019.
“It is critical to enable software developers and data scientists doing machine learning a way to interface to our [ACAP] products,” says Saban.
Vitis supports programming languages such as C, C++ and Python as well as higher-level machine-learning frameworks such as TensorFlow and Caffe.
Xilinx also has a library of functions for tasks such as data analytics and genomics. Such applications can be switched in and out since they are executed using adaptive hardware.
The Premium software tools will be available in the fourth quarter of the year.
Lifespan
A programmable logic family’s lifespan is five or six years; the Virtex UltraScale family was launched in 2015.
“We added a few kickers [to the Virtex family] such as high bandwidth memory and 58-gigabit serdes,” says Saban. “And we will likely do the same with Versal, add some integrated block in a derivative product.”
Xilinx’s chip designers will likely now be already working on an ACAP architecture for 2026 supporting 1.6-terabit speeds and to be implemented using a 5nm CMOS process.
“If we are to deliver twice the bandwidth at half the power, it is not enough to lean on CMOS process technology,” says Saban. “We will need to look at new chip architectures to solve the problems.”
This is challenging. “It gets harder, it gets more expensive and there are less and fewer companies that can afford it,” says Saban.

CW-WDM MSA charts a parallel path for optics
Artificial intelligence (AI) and machine learning have become an integral part of the businesses of the webscale players.
The mega data centre players apply machine learning to the treasure trove of data collected from users to improve services and target advertising.

Chris Cole
They can also use their data centres to offer cloud-based AI services.
Training neural networks with data sets is so intensive that it is driving new processor and networking requirements.
It is also impacting optics. Optical interfaces will need to become faster to cope with the amount of data, and that means interfaces with more parallel channels.
Anticipating these trends, a group of companies has formed the Continuous-Wave Wavelength Division Multiplexing (CW-WDM) multi-source agreement (MSA).
The CW-WDM MSA will specify lasers sources and the wavelength grids they use. The lasers will operate in the O-band (1260nm-1360nm) used for datacom optics.
The MSA is defining eight, 16 and 32 channels and will build on work done by the ITU-T and the IEEE.
This is good news for the laser manufacturers, says Chris Cole, Chair of CW-WDM MSA (pictured), given they have already shipped millions of lasers for datacom.
“In general, lasers are typically the hardest thing,” he says.
Wavelength count
The majority of datacom pluggable modules deployed today use either one or four optical channels. “When I started in optics 20 years ago it was all about single wavelengths,” says Cole.
Four channels were first used successfully for 40-gigabit interfaces. “That is when we introduced coarse wavelength-division multiplexing (CWDM),” says Cole.
Four wavelengths are the standard approach for 100, 200 and 400-gigabit optical modules. Spreading data across four channels simplifies the design of the electrical and optical interfaces.
“But we are ready to move on because the ability to increase parallel channels - be it parallel fibres or wavelengths - is much greater than the ability to push speed,” says Cole. “If all we do is rely on a four-wavelength paradigm and we keep pushing speed, we will run into a brick wall.”
Integration
Adopting more parallel channels will have two consequences on the optics, says Cole.
One is that photonic integration will become the only practical way to build multi-channel designs. Eight-channel designs are possible using discrete components but it won’t be cost-competitive for designs of 16 or more channels.
“It has to be photonic integration because as you get to eight and later, 16 and 32 wavelengths, it is not supportable in a small size with conventional approaches,” says Cole.
The MSA favours silicon photonics integration but indium phosphide or polymer integration platforms could be used.
The MSA will also cause wavelengths to be packed far more closely than the 20nm used for CWDM. Techniques now exist that enable tighter wavelength spacings without needing dedicated cooling.
One approach is separating the laser from the silicon chip - a switch chip or processor - that generates a lot of heat. Here, light from the source is fed to the optics over a fibre such that temperature control is more straightforward because the laser and chip are separated.
Cole also highlights the athermal silicon photonics of Juniper Networks that controls wavelength drift on the grid without requiring a thermo-electric cooler. Juniper gained the technology with its Aurrion acquisition in 2016.
Specification work
“Using the O-band has a lot of advantages,” says Cole. “That is where all the datacom optics are.”
The optical loss in the O-band may be double that of the C-band but this is not an issue for datacom’s short spans.
The MSA is to define a technology roadmap rather than a specific product, says Cole. First-generation products will use eight wavelengths followed by 16- and then 32-wavelength designs. Sixty-four and even 128 channel counts will be specified once the technology is established.
“Initially we did [specify 64 and 128 channels] but we took it out,” says Cole. “We’ll know a lot more if we are successful over three generations; we’ll figure out what we need to do when we get to that point.”
The MSA is proposing two bands, one 18nm wide (1291nm-1309nm) and the other 36nm wide (1282nm-1318nm). Eight, 16 and 32 wavelengths are assigned across both bands.
“It’s smack in the middle of the CWDM4 grid which is the largest shipping laser grid ever, and it is smack on top of the LWDM4 grid [used by -LR4 modules] which is the next highest grid to ship in volume,” says Cole.
The MSA will also specify continuous-wave laser parameters such as the output power, spectral width, variation in power between the wavelengths, and allowable wavelength shift.
Members
Cole started work on the CW-WDM MSA in collaboration with Ayar Labs while he was still at II-IV. Now at Luminous Computing, Cole, along with MSA editor Matt Sysak of Ayar Labs, and associate editor Dave Lewis of Lumentum, are preparing the first MSA draft and have solicited comments from members as to what to include in the specifications.
The MSA has 11 promoter members: Arista, Ayar Labs, CST Global, imec, Intel, Lumentum, Luminous Computing, MACOM, Quintessent, Sumitomo Electric, and II-VI.
The MSA has created a new observer member status to get input from companies that otherwise would be put off joining an MSA due to the associated legal requirements.
“So we have an observer category that if someone is serious and they want to see a subset of the material the MSA is working on and provide feedback, we welcome that,” says Cole.
The observer members are AMF, Axalume, Broadcom, Coherent Solutions, Furukawa Electric, GlobalFoundries, Keysight Technologies, NeoPhotonics, NVIDIA, Samtec, Scintil Photonics, and Tektronix.
“This MSA is meant to be inclusive, and it is meant to foster innovation and foster as broad an industry contribution as possible,” concludes Cole.
Further information
The CW-WDM MSA has several documents and technical papers on its website. The first document is the CW-WDM MSA grid proposal while the rest are technical papers addressing developments and applications driving the need for high-channel-count optical interfaces.

ADVA enables the sharing of spectrum at the optical layer
-
Spectrum-as-a-service enables third parties to run networks over existing optical infrastructure.
-
ADVA has also simplified linking systems to the metro-access network using self-tuning SFP+ optical modules.
ADVA has developed a scheme whereby communications service providers can sell unused fibre capacity to customers to design and run their own optical networks.
“Optical spectrum-as-a-service gives communications service providers tools to sell spectrum to someone else who now doesn’t need to build a parallel infrastructure,” says Jörg-Peter Elbers, ADVA’s senior vice president, advanced technology, standards and IPR.

Jörg-Peter Elbers
ADVA has also developed a G.metro-compliant dense wavelength-division multiplexing (DWDM) scheme to simplify linking business parks, radio cell towers and small cells to a metro-access network.
The G.metro scheme uses a self-tuning pluggable SFP+ module that sets up connections to the network’s end-points.
ADVA says the connectivity scheme is timely given how mobile sites need 10-gigabit and in future 25-gigabit connections while business services are now at 10 gigabits.
“Premium business services at one gigabit made using DWDM hard to justify,” says Elbers. “At 10-gigabit links, the argument for DWDM is easier to make since the overall capacity is much higher.”
Optical spectrum-as-a-service
Communications service providers often start deployments with as few as two wavelengths. Yet they must pay upfront the cost of common infrastructure such as the optical amplifiers and reconfigurable optical add-drop multiplexers (ROADMs).
“When they deploy, they can’t amortise this cost over many [optical] channels,” says Elbers.
Spectrum-as-a-service offers new revenue for operators while sparing the end-customer from having to build their own optical infrastructure.
Spectrum-sharing builds on the existing practice of running an alien wavelength from a third-party over an optical line system. Instead of channels, operators now sell spectrum to a customer who can then design their optical network for their high-capacity traffic.
Implementation
Hardware and software elements are needed to implement spectrum sharing.
The hardware includes the line system’s amplifiers and flexible-grid ROADMs that are used to slice the spectrum into blocks.
“If you want to segment the spectrum arbitrarily, which is where most of the value is, you need to have flexgrid technology,” says Elbers.
ADVA also includes spectrum gateway and demarcation functions that isolate the tenants’ traffic and ensures that wavelengths introduced by each tenant is confined to their assigned spectrum.
The customer also needs to monitor the optical layer to plan and control their allocated spectrum services. The ADVA software includes a software-defined networking (SDN) controller and the ability to access performance information.
“This is where an SDN controller comes in handy,” says Elbers. “It is a gating point where you can decide who is allowed to do what and who controls which resources, so you don’t get conflicts and unwanted side-effects.” The controller enables the operator to expose the infrastructure for the tenants (see diagram).

Source: ADVA
Elbers says these capabilities will be introduced gradually. Initially, a customer can tell the operator what to implement but the end-goal is to enable the tenant to design, implement and control their optical network.
Spectrum-as-a-service has become possible due to the maturity of the technologies. Coherent interfaces simplify network planning given their predictable performance while flexible-grid ROADMs enable spectrum slicing and changing the channel widths in a slice to accommodate new symbol rates over time.

Stephan Rettenberger
“This is a new decoupling of the optical line system from the terminals,” says Stephan Rettenberger, senior vice president, marketing and investor relations at ADVA. “Given fibre is a precious material, this is the way the industry needs to move and we’ve made progress in the line system to empower this.”
Metro-access applications
ADVA has also announced a metro-access connectivity scheme where fibre is scarce. For such applications, using a dedicated fibre to carry a single 1, 10 or 25-gigabit wavelength is wasteful.
Example networking applications include front-haul and back-haul for mobile, and business services.
The G.metro-complaint solution simplifies the equipment required. “All that is needed is to transport signals over fibre and do it with the lowest latency,” says Elbers.
For wireless, the SFP+ is simply plugged in at the remote-radio head. All the issues of optical tuning are hidden from the user and taken care of by the module communicating with the head-end.
The same applies to 10-gigabit premium services to connect business parks. Enterprises are connected on a pay-as-you-grow basis by deploying passive optical filtering. “You don’t need any active equipment in the field and everything is controlled at the end-point,” says Elbers.
The end-point equipment used for mobile is different from that used by enterprises. In turn, each application has its preferences, he says: “This is where pluggable modules come into play, irrespective of what the host equipment is, you just plug in the appropriate SFP+ module.”
Self-configuring links
The SFP+ modules’ span 10 to 20km links although 40-80km could be used if needed.

Source: ADVA
The wavelength counts used are commonly fewer than in metro networks. Elbers cites as an example 12 wavelengths to carry common public radio interface (CPRI) traffic from a mobile tri-sector radio mast where each sector uses four frequency bands. “But, in principle, it is not limited to any wavelength count,” he says.
Filters are used at the head-end and the end-points. Plugging in an SFP+, the local filter determines which wavelength is used. The SFP+ tunes itself to the required wavelength while the filter ensures separation from the other signals on the fibre.
ADVA uses an in-band communication channel to relay the status information of the remote signal. The optical layer in-band scheme is independent of the protocols run on the fibre, ensuring its workings whatever the end-equipment used.
ADVA is working with several transceiver partners to develop the SFP+ and is using its intellectual property (IP). The company’s IP includes the wavelength control and the information sharing between the end-points.
The G.metro solution is now generally available.
Windstream to add ICE6 as it stirs its optical network
Windstream has sent an 800-gigabit optical signal between the US cities of Phoenix and San Diego. The operator used Infinera’s Groove modular chassis fitted with its latest ICE6 infinite capacity engine for the trial.
Infinera reported in March sending an 800-gigabit signal 950km with another operator but this is the first time a customer, Windstream, is openly discussing a trial and the technology.
The bulk of Windstream’s traffic is sent using 100-gigabit wavelengths. Moving to 800-gigabit will reduce its optical transport costs.
Windstream will also be able to cram more digital traffic down its fibre. It sends 12 terabits and that could grow to 40 terabits.
Motivation
Windstream provides residential broadband, business and wholesale services in the US.
“We operate a national footprint for wholesale and enterprise services,” says Art Nichols, vice president of architecture and technology at Windstream. “The optical focus is for wholesale and enterprise.”

Art Nichols
The communications service provider has 160,000 miles of fibre, 3,700 points-of-presence (PoPs) and operates in 840 cities. “We are continually looking to expand that,” says Nichols. “Picking up new PoPs, on-ramps and landing spots to jump onto the long-haul network.”
If Windstream’s traffic is predominantly at 100-gigabit, it also has 200-gigabit wavelengths and introduced recently 400-gigabit signals. In April Windstream and Infinera trialled Gigabit Ethernet (GbE) client-side services using LR8 modules.
Windstream is interested in adopting 800-gigabit wavelengths to reduce transport costs. “To try to draw as much efficiency as you can, using as few lasers as you can, to push down the cost-per-bit,” says Nichols.
The operator is experiencing traffic growth at a 20-30 per cent compound annual growth rate that is eroding its revenue-per-bit.
Weekly traffic has also jumped a further 20 per cent during the COVID-19 pandemic. Video traffic is the main driver, with peak traffic hours starting earlier in the day and continuing into the evenings.
Sending more data on a wavelength reduces cost-per-bit and improves revenue-per-bit figures.
In addition to sending a 800-gigabit signal over 730km, the operator sent a 700-gigabit signal 1,460km. The two spans are representative of Windstream’s network.
“Eight hundred gigabits is an easier multiple - better to fit two 400GbE clients - but 700 gigabits has tons of applications,” says Nichols. “We are predominantly filling 100-gigabit orders today so being able to multiplex them is advantageous.”
Another reason to embrace the new technology is to fulfill wholesale orders in days not months. “The ability to turn around multi-terabit orders from webscale customers,” says Nichols. “That is increasingly expected of us.”
One reason order fulfilment is faster is that the programming interfaces of the equipment are exposed, allowing Windstream to connect its management software. “We instantiate services in a short turnaround,” says Nichols.
ICE6 technology
Infinera’s ICE6 uses a 1.6-terabit photonics integrated circuit (PIC) and its 7nm CMOS FlexCoherent 6 digital signal processor (DSP). The 1.6 terabits is achieved using two wavelengths, each able to carry up to 800 gigabits of traffic.
The ICE6 uses several techniques to achieve its optical performance. One is Nyquist sub-carriers where data is encoded onto several sub-carriers rather than modulating all the data onto a single carrier.
The benefit of sub-carriers is that high data rates are achieved despite the symbol rate of each sub-carrier being much lower. The lower symbol rate means the optical transmission is more tolerant to non-linear channel impairments. Sub-carriers also have sharper edges so can be squeezed together enabling more data in a given slice of spectrum.
Infinera also applies probabilistic constellation shaping to each sub-carrier, enabling just the right amount of data to be placed on each one.
The FlexCoherent 6 DSP also uses soft-decision forward-error correction (SD-FEC) gain sharing. The chip can redistribute processing to the optical channel that needs it the most.
Some of the strength of the stronger signal can be cashed in to strengthen the weaker one, extending its reach or potentially allowing more bits to be sent by enabling a higher modulation scheme to be used.
Windstream cannot quantify the cost-per-bit advantage using the ICE6. “We don’t have finalised pricing,” says Nichols. But he says the latest coherent technology has significantly better spectral efficiency.
Spectral efficiency can be increased in two ways, says Rob Shore, Infinera’s senior vice president of marketing.
One is to increase the modulation scheme and the other is to close the link and maintain the high modulation over longer spans. If the link can’t be closed, lowering the modulation scheme is required which reduces the bits carried and the spectral efficiency.
Windstream will be able to increase capacity per fibre by as much as 70 per cent compared to the earlier generation 400-gigabit coherent technology and by as much as 35 per cent compared to 600-gigabit coherent.
A total of 42.4 terabits can be sent over a fibre using 800-gigabit wavelengths, says Shore, but the symbol rate needs to be reduced to 84 gigabaud shortening the overall reach.
Trial learnings
The rate-reach performance of the ICE6 was central to the trial but what Windstream sought to answer was how the ICE6 would perform across its network.
“We paid really close attention to margins and noise isolation as indicators as to how it would work across the network,” says Nichols. “The exciting thing is that it is extremely applicable.”
Windstream is also upbeat about the technology’s optical performance.
“We have a fair amount of information as to what the latest optical engines are capable of,” says Nichols. “This trial gave us a good view of how the ICE6 performs and it turns out it has advantages in terms of rate-reach performance.”
Ciena, Huawei and Infinera all have 800-gigabit coherent technology. Nokia recently unveiled its PSE-V family of coherent devices that does not implement 800-gigabit wavelengths.
Michael Genovese, a financial analyst at MKM Partners, puts the ICE6 on a par with Ciena’s WaveLogic 5 that is already shipping to over 12 customers.
“We expect 800 gigabit to be a large and long cycle," says Genovese in a recent research note. “We think most of the important internet content providers, telcos and subsea consortia will adopt a duel-vendor strategy, benefitting Ciena and Infinera over time.”
Windstream will adopt Infinera’s ICE6 technology in the first half of 2021. First customers to adopt the ICE6 will be the internet content providers later this year.

OIF to double data rate with a 224G electrical interface
-
The OIF will develop a faster electrical signalling standard
-
The 224-gigabit standard will make optical modules sleeker
-
It will also help data centre operators keep up with ever-growing software workloads
It was just a matter of time before the OIF started on the next electrical interface standard beyond 112 gigabits-per-second (Gbps).
There have been announcements of new 800-gigabit optical modules along with growing interest in co-packaged optics, where optical interfaces are added alongside semiconductor chips.

Nathan Tracy
Nathan Tracy, TE Connectivity and OIF president, says member companies will need to be creative to develop a 224-gigabit electrical interface. Getting signals to travel at such speeds over workable distances will be a challenge.
The project, to kick-off in August, will begin with a study phase that will help identify the interface types needed.
CEI-112G
The OIF’s electrical interfaces underpin Ethernet networking and the Fibre Channel storage protocol. They are also used for more specialist interfaces such as the chip-to-chip Interlaken standard.
The OIF is currently finishing the 112-gigabit electrical interface that addresses five use-cases. These range from the shortest reach CEI-112G-MCM for chip-to-chiplet interfaces to the longest reach CEI-112G-LR linking chips across a platform’s backplane or via a passive copper cable. (See diagram.)
“The CEI-112G has been a challenging project,” says Tracy. “It’s technically difficult and just as we start to stabilise things, a member will bring a new data point that causes us to check our underlying assumptions.”
The CEI-112G-XSR interface, used to connect ICs to optical engines for co-packaged optics, was the focus of attention at the last OIF meeting held in May. But all five projects are starting to take shape, says Tracy.
The OIF will not give a finishing date for the CEI-112G specification. “We are more focussed on making sure the document is right than hitting a schedule,” says Tracy. “But we are talking about what is needed to close it out.”
Testing of prototypes using the CEI-112G interfaces will happen this year with first commercial designs expected in 2021. The OIF started the CEI-112G work in 2016.
224 gigabits
The OIF will do things differently for the next standard given how hard it is to run electrical signals over copper at such speeds.
It plans to gather information from its members to help figure out the interface types it will need.
“We need our members who are the cloud operators to tell us what it is they are going to try to do,” says Tracy. “What drives their architecture which then drives a certain reach over a certain medium,”
Other issues that will be addressed include modulation schemes for the signalling, test and measurement requirements, and what software tools will need to be able to simulate 224Gbps links.
“The idea is to create a space where members can debate, look at data and do analysis,” says Tracy. This is different from the CEI-112G project where the interfaces types were known from the start.
Challenges
The OIF’s CEI-56G standard that implements 56-gigabit links uses two types of modulation schemes: non-return-to-zero (NRZ) signalling over a 28GHz bandwidth channel or four-level pulse-amplitude modulation (PAM-4) using a 13-14GHz channel. PAM-4 and 28GHz of bandwidth is needed to implement 112-gigabit electrical signalling.
The OIF rule-of-thumb to work out loss when sending a signal is 0.1dB-per-inch-per-gigahertz (dB/inch/GHz). To achieve 224Gbps, simply doubling the bandwidth will not do.
Instead, a combination of several techniques will be needed to make the signalling work. These include advanced printed circuit board (PCB) materials, new connector designs, the use of flyover cables to reduce loss, and working out the best modulation-bandwidth tradeoff.
“It is not a case of trying to push electrons harder,” says Tracy. “It is not just turning the clock up and seeing what we get, nor can we increase the power- and cost-per-gigabit.”
The OIF will likely take between four and five years to finish the CEI-112G standardisation work. Given that the 224-gigabit work is expected to be even harder, the specification document will not be finished before 2025.
Changing requirements
The engineers that developed the 10-gigabit electrical interface would never have envisaged a 224Gbps electrical interface. But each jump to the next speed is less daunting, says Tracy: “When we got to 25 gigabits we saw that 56 gigabits was going to be possible, and when we were doing that, we had the know-how to get to 100 gigabits.”
The computing requirements in data centres are also changing with new workloads for machine learning and artificial intelligence. “The compute architecture is changing, and if the compute architecture changes then so does the switching network architecture,” says Tracy.
Computing is also on the move, shifting from the mega data centre to the network edge.
“So compute is happening differently and that is impacting speeds and data rates,” says Tracy. “How we do it, the technologies we are going to use, it is going to change as we go along.”
It is not just signalling speed that is changing, but where it is used and over what reaches. This will apply to the 224-gigabit standard and to what comes after that.

Ethernet Alliance on 800G and the next Ethernet rate
It may have taken the industry five years to get 400 Gigabit Ethernet (GbE) modules shipping, but for Mark Nowell, Advisory Board Chair at the Ethernet Alliance, the long gestation period is understandable given the innovation that has been required.

The industry has had to cram complex technology into a small form factor for 400GbE while meeting the requirements of two very different end-customers: webscale players and communications service providers.
400 Gigabit Ethernet
“The pressure is still on to get 400-gigabit out given that systems are shipping,” says Nowell. “Like with 100-gigabit QSFP28, it is always a rocky road at the beginning, getting all the reaches and getting all the [module] suppliers qualified.”
The 400GbE work is also continuing, with ICs for second-generation optics being tested in the labs that will reduce overall module power consumption.
Nowell notes the scale at which 400 Gigabit Ethernet will be adopted. The number of 400GbE modules expected to ship over the next five years will be 20x the 100GbE module units shipped during its first five years, based on forecast data from LightCounting Market Research.
“100 Gigabit Ethernet started very slowly because it was predominantly service providers [as adopters],” says Nowell. “What is happening with 400 Gigabit Ethernet is that now there is dual-demand from webscale players and service providers.”
This demand has pressured the industry in recent years to achieve a compact form factor, resulted in another noteworthy aspect of 400GbE. “400GbE is unique in that it is the first time we have come out with a new higher-speed Ethernet data rate where all of the reaches - from copper cables to coherent optics - fit in the same form factor,” says Nowell. “Unfortunately, we have two form factors: the QSFP-DD and the OSFP.”
The industry has also had to develop technologies such as 50-gigabit serialiser-deserialiser (serdes), with 100-gigabit serdes now following, and 100-gigabit-per-wavelength optics.
Creating working QSFP-DD and OSFP designs has also been a challenge; how to cool them and achieve the required signal integrity.
“This is the background to where we are today,” says Nowell.
800-gigabit pluggables
Two 800-gigabit multi-source agreements (MSAs) have been announced in the last year.
The 800G Pluggable MSA developing optical specifications for 800-gigabit pluggable modules, and the QSFP-DD800 MSA that extends the QSFP double-density form factor to support 800 gigabits.
The QSFP-DD800 MSA will ensure the connector supports 100-gigabit electrical signals and extend the module’s power envelope from 20W to 24W.
The QSFP-DD800 form factor will also be backwards-compatible with three other QSFPs: the 100-gigabit QSFP28, the 400-gigabit QSFP-DD and the 100-gigabit electrical input 400-gigabit QSFP400.
The first QSFP-DD800 MSA hardware specification was issued in March, to coincide with OFC. The release (version 1.0) has now been passed to the QSFP-DD MSA.
Nowell points out that the technology being used for 800-gigabit MSAs is the same as that being used for 400GbE.
“The amount of investment that we, as an industry, have put into getting these 400-gigabit building blocks, we need to recoup that,” he says. “We need to start building dense 400GbE, making more units and cost-reducing them; 800-gigabit pluggables will do just that.”
Thus, the same form factor - whether an OSFP or QSFP-DD800 - will deliver 2x400GbE or 8x100GbE. Accordingly, no 800GbE work needs to happen.
Next Ethernet rate
“What the 800-gigabit MSAs show is that there is a real interest in what is coming next,” says Nowell, who also co-chairs the QSFP-DD800 MSA.
Building 'denser 400-gigabit' in the form of 800-gigabit modules has an economic benefit for component vendors in that they can recover the investment they have made in the technology.
As for whether the network needs greater speed links, the reason is often one of two things, says Nowell. It either reduces the cost of networking or it benefits networking in terms of hashing efficiencies by using a higher capacity link.
“So does 800 Gigabit Ethernet need to exist to solve the hashing problem?” says Nowell. “I don’t hear a lot of people complaining about this being an issue.” And it would be the webscale players, given the scale of their operations, encountering this first, he says.
Nowell cites the emergence of co-packaged optics, whereby optics are added alongside an ASIC to provide the chip with high-speed optical input-output (I/O).
The requirement for co-packaged optics is coming from the cloud players and he cites the Co-Packaged Optics Consortium created by Microsoft and Facebook that issued a guidance document last year.
“They said this is what we need as an industry, and if you look at that, it is all based on dense 400 Gigabit Ethernet,” says Nowell.
The webscale players’ interest in co-packaged optic stems from the emergence of higher-capacity switch chips at 25.6 terabit and 51.2 terabits.
“The bandwidth demands that customers are seeing and the power efficiencies that customers are looking for, they need a roadmap of silicon development,” says Nowell. “The purpose of optics is to support the switch silicon.”
Adopting dense 400GbE will ensure that equipment using co-packaged optics will be able to talk to equipment using pluggables only.
Given work on 400GbE started around 2014, and that the capacity of Ethernet switch chips is doubling every two years, is there no urgency to define the next Ethernet rate?
Not yet, says Nowell, but it is something the Ethernet Alliance recognises.
It organises an event dubbed the Technology Exploration Forum (TEF) that brings together industry experts and the latest was scheduled for April 15th, focussing on the next Ethernet rate after 400GbE. However, due to the COVID-19 pandemic, the event has been postponed till October 7th.
“I don’t think there is any inconsistency yet but it is the right time to start, and that is why the Ethernet Alliance wants to drive the TEF event and have the discussion,” he says.
There is also the IEEE’s New Ethernet Applications group that acts as an incubator for new ideas. Such ideas can lead to a Call For Interest which, if sufficiently supported, is how new IEEE projects begin.
One such project that has just started is entitled Beyond 400 Gigabit that will look at market needs and define, from an IEEE perspective, what should be done in terms of technologies.
The IEEE 400GbE work took five years because it introduced several new technologies: 50-gigabit serdes, 100-gigabit-per-lambda optics, 4-level pulse amplitude modulation (PAM-4), and the use of 8-lanes for certain 400GbE implementations.
Nowell points out that the 800G Pluggable MSA includes 200-gigabit-per-lambda optics and FEC which are complex elements that require time to work through.
“My opinion is that if you want to do something in the IEEE, you want more headroom,” says Nowell. “It would be a mistake for the IEEE to only pursue 800 Gigabit Ethernet and then come up for air in several years and find that the industry has moved on.”
So the likelihood is that the next Ethernet rate will be at least 2.5x the current one (1TbE) and even as high as 4x (1.6TbE), similar to how 10GbE moved to 40GbE.
But this will be challenging, says Nowell. Issues such as what comes after 100-gigabit serdes and 100-gigabit-per-wavelength, and when will coherent technology be cost-effective enough for use within the data centre remain unresolved.
Meanwhile, the Ethernet Alliance’s TEF aims to shape the debate by bringing together different industry voices, with an emphasis on end-users and thought leaders.
Will the COVID-19 pandemic impede development and standards work?
“In this industry, we are used to working with collaborative tools so it’s not such a shock to pick up these to progress,” says Nowell. “I’ve been pleasantly surprised we have been able to do standards work this way without too much disruption other than it takes longer.”
But what is missing is meeting people face-to-face and the discussions that ensue.
“It does make a difference getting out and talking to customers,” says Nowell. “There is an unquantifiable thing that is missing.”

Nokia targets 400G era with PSE-V coherent DSP launch
Nokia has unveiled its latest coherent digital signal processor (DSP) family, its fifth-generation Photonic Service Engine dubbed the PSE-V.
Two devices make up the family: the high-end super coherent PSE-Vs and the compact PSE-Vc for use in pluggable modules.

Kyle Hollasch
The PSE-Vc chip is already sampling, the PSE-Vs will sample later this year.
The PSE-Vs, operating at a 90 gigabaud (GBd) symbol rate, supports transmission distances from local data centres to ultra-long-haul and sub-sea networks while the 64GBd PSE-Vc implements the OIF’s 400ZR standard, ZR+ and beyond.
Nokia has also expanded its coherent optics strategy having completed the acquisition of Elenion Technologies. It is now vertically integrated and is offering coherent optics and its DSPs to partners that include module makers and contract manufacturers.
The 400G era
The last decade has been primarily based on 100 gigabit, with 100-gigabit client signals appearing around 2010 and coherent optics starting at 100 gigabit. “We like to forget about 40 gigabit,” quips Kyle Hollasch, director of optical networking product marketing at Nokia.
This decade marks the start of the 400-gigabit era. “Just about this year and, in earnest, next year, we will see 400 gigabit adopted as the dominant data centre client-rate, timed along with 400-gigabit coherent,” says Hollasch.
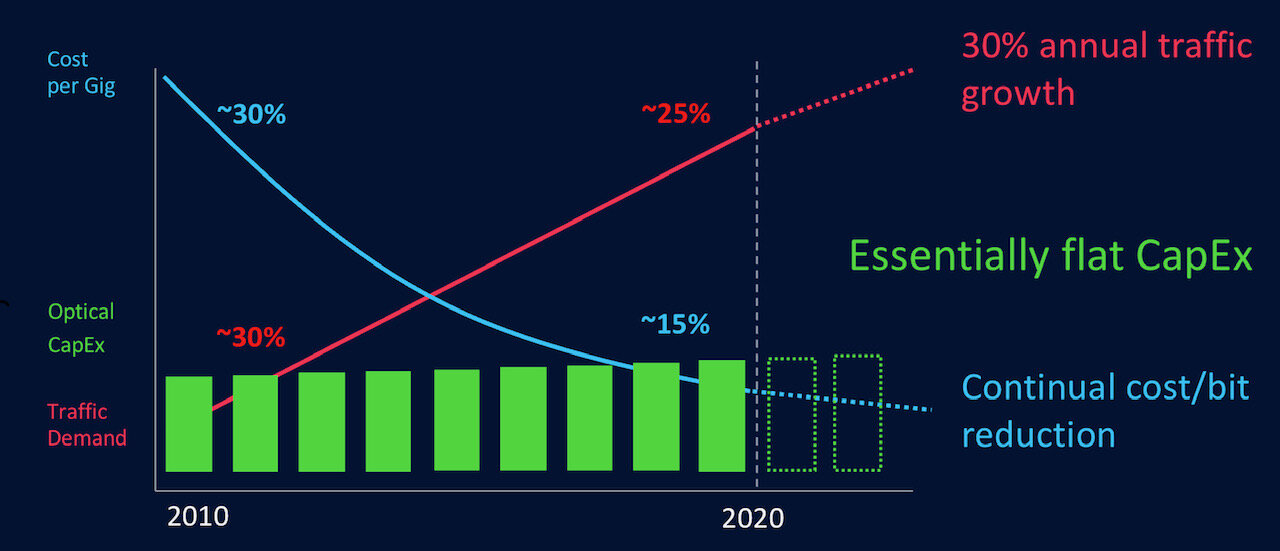
During the last decade, traffic has continued to grow exponentially while cost-per-bit has declined, first at 30 per cent per annum and more recently at 15 per cent. Overall, the optical market spend has been largely flat over the last decade (see diagram).
Meanwhile, the technologies underpinning coherent and optical transport are becoming more challenging.
Optical performance using coherent has improved significantly with advances in baud rate, modulation schemes and forward-error correction (FEC). So much so that optical performance is approaching the theoretical Shannon limit. “We don’t know where it is but we know we are close,” says Hollasch.
Moore’s law is also slowing down. The gains in processing performance and power reduction are harder to achieve with each advance in CMOS process geometry. The latest PSE-V devices are implemented using 7nm CMOS.
“The question we are trying to answer is that, with this new era and certain technology trends slowing down, how are we going to keep scale and cost-containment going,” says Hollasch.
Coherent strategy
Nokia highlights three elements to address scale and reduce cost.
In addition to its existing coherent DSP expertise, Nokia has added an optical engine design capability, and integration and packaging know-how.
The CSTAR optical engine, gained with the Elenion acquisition, includes silicon-photonics-based optics and transmitter and receiver ICs that are parcelled in a BGA chip package
“The existing CSTAR portfolio is already shipping to several customers and there is a lot of development and opportunities going forward,” says Hollasch.
The PSE-Vc and the optical engine are being integrated into various form factors to deliver different price points and optical performances. “And the market is rapidly shifting towards pluggable [coherent] transceivers,” says Hollasch.
Being vertically integrated brings cost-advantages, says Hollasch, as well as an ability to innovate faster by ‘owning’ the entire development and manufacturing process.
The approach has been adopted by other optical transport companies. Infinera has always developed its DSPs and indium-phosphide optics; several years ago Ciena brought indium-phosphide and silicon photonics expertise in-house to complement its DSPs, Huawei also has both DSP and optics expertise, while Cisco Systems gains both with its Acacia acquisition.
Nokia’s partners will be its customers, using its components and taking the resulting products to market. In turn, Nokia will also be a customer of modules and subsystems.
“Elenion was a corporate acquisition,” says Hollasch. “It lives under the optical unit but it was acquired for the benefit of the entire corporation.” After the optical unit, Nokia’s IP division will be the next largest consumer of transceivers, particularly at 400 gigabit, while mobile and access “are at the cusp of coherent adoption”, he says.
Hollasch does not rule out its modules being sold via partners and resellers: “It is still early in the process but it is absolutely part of the roadmap.”
PSE-Vs
Upping the symbol rate of the PSE-Vs to 90GBd delivers a significant performance benefit.
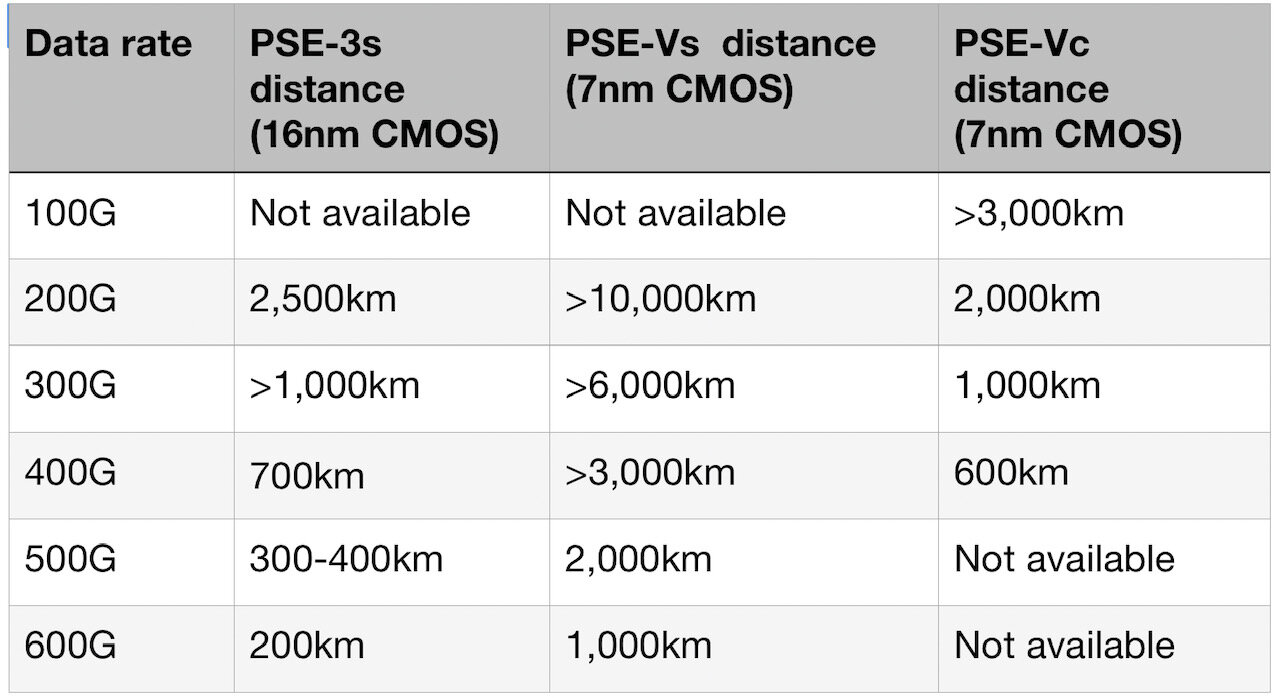
In the current-generation PSE-3, 400-gigabit transmission at 64GBd requires 16-ary quadrature amplitude modulation (16-QAM) whereas operating at 90GBd, quadrature phase-shift keying (QPSK) can be used.
“Instead of a regional distance of 1,000km [for 400-gigabit 16-QAM], you can send QPSK almost anywhere on the planet,” he says (see table).
The PSE-Vs is Nokia’s second-generation DSP to use probabilistic constellation shaping (PCS). The technique allow the transmission data rate to be defined with fine granularity, tailored for a specific link. Nokia was the first vendor to implement PCS with its PSE-3.
The 90GBd baud rate is used for all the data rates, from 200-600 gigabits-per-second (Gbps) using PCS. A reach of 1,000km is possible at 600Gbps whereas 200Gbps is used to address the longest sub-sea spans.
Hollasch highlights what he believes is a key benefit of Nokia’s technology: the joint optimisation of PCS and its proprietary FEC scheme.
Hollasch says its FEC reduces the extra bits that are appended to the data - the overhead payload - from 25 per cent to 16 per cent: “We believe that gives a performance enhancement not available to the rest of the market.”
Nokia says silicon photonics and indium phosphide will be used for PSE-Vs-based coherent designs.
“We believe that we can achieve similar performance with both technologies,” says Hollasch. “The reason for using both is for diversification of supply; the COVID-19 event has shown that we need diversification in all areas of our supply chain.”
Source: Nokia, Gazettabyte
PSE-Vc
The PSE-Vc will be used to implement 400ZR and ZR+ in a QSFP-DD pluggable module.
Nokia refers to the two extremes of coherent, as exemplified by the ‘super coherent’ and ‘compact’ names for its PSE-V chips, as high-end performance and profile, by which it means form factor.
Whereas performance is all about maximum reach and reducing cost/bit/km, profile is concerned with cost, interoperability and being pluggable.
But Hollasch stresses there is an important middle region where the goal of the interfaces - partly the ZR+ and the rest the CFP2-DCO - is to balance these two extremes.
“The middle does not get the attention; all the attention goes to the high-end,” says Hollasch. “But the vast majority of optical networking is happening in the middle.”
Nokia is implementing 400ZR and ZR+ using the QSFP-DD form factor. ZR+ extends the performance of 400ZR by supporting traffic protocols other than Ethernet as well as data rates of 400 gigabits and below. Such rates - 100 to 300 gigabits - extend reach beyond 400ZR’s 120km.
Nokia is not adopting the OSFP form factor for coherent. “We don’t see a huge demand for the OSFP,” says Hollasch.
The CFP2-DCO using the PSE-Vc is what Hollasch refers to as the ‘ZR++’. The greater volume and power envelope of the CFP2 module means its optical performance can exceed greatly that of 400ZR and ZR+. “The CFP2 will be a large part of our optical platforms.”
The CFP2 and the QSFP-DD modules will be available towards year-end.
No 800 gigabit
Unlike its rivals Ciena, Huawei and Infinera, Nokia has chosen not to support 800-gigabit wavelengths with its latest high-end DSP.
The company argues that at data rates greater than 600 gigabit, the reach is limited. “It is not that 800 gigabit isn't important, it is just that it lives in a world of many options,” says Hollasch.
The 800-gigabit rate is not economical to pursue with this generation, he says: “For data centre interconnect, it is much more economical to pursue shorter distances with 400ZR and ZR+.”
He argues that 400-gigabit coherent pluggables will be hard to beat in terms of power consumption and cost, given the demand from the webscale players and the many companies making them. Equally, since 400ZR is a standard, modules are interoperable.
Nokia also highlights the engineering issues involved in implementing rates above 600 gigabit.
At 600 gigabit, the PSE-Vc uses 16-QAM whereas 800 gigabit requires 64-QAM. Processing four times as many constellation points loads the DSP for what is a limited use case. “It puts lots of strain on the DSP; we know, we did 64-QAM in both the PSE-2 and PSE-3,” he says.
Confining an 800-gigabit wavelength to a 100GHz channel limits its reach to 100-200km, says Hollasch. Extended the channel to 125GHz, the reach of an 800-gigabit wavelength is extended. But two 400-gigabit pluggables, each using a 75GHz channel, can also be used to transmit the same capacity over long reaches.
In other words, a 125GHz channel is needed ‘to get anywhere’ while saving very little in terms of spectral efficiency, concludes Hollasch.