
Marvell exploits 5nm CMOS to add Octeon 10 DPU smarts

The Octeon family has come a long way since the networking infrastructure chip was introduced by Cavium Networks in 2005.
Used for data centre switches and routers, the original chip family featured 1 to 16, 64-bit MIPS cores and hardware acceleration units for packet processing and encryption. The devices were implemented using foundry TSMC’s 130nm CMOS process.
Marvell, which acquired Cavium in 2018, has taped out the first two devices of its latest, seventh-generation Octeon 10 family.
The devices, coined data processing units (DPU), will feature up to 36 state-of-the-art ARM cores, support a 400-gigabit line rate, 1 terabit of switching capacity, and dedicated hardware for machine-learning and vector packet processing (VPP).
Marvell is using TSMC’s latest 5nm CMOS process to cram all these functions on the DPU system-on-chip.
The 5nm-implemented Octeon 10 coupled with the latest ARM cores and improved interconnect fabric will triple data processing performance while halving power consumption compared to the existing Octeon TX2 DPU.
DPUs join CPUs and GPUs
The DPU is not a new class of device but the term has become commonplace for a processor adept at computing and moving and processing packets.
Indeed, the DPU is being promoted as a core device in the data centre alongside central processing units (CPUs) and graphic processing units (GPUs).
As Marvell explains, a general-purpose CPU can perform any processing task but it doesn’t have the computational resources to meet all requirements. For certain computationally-intensive tasks like graphics and artificial intelligence, for example, the GPU is far more efficient.
The same applies to packet processing. The CPU can perform data-plane processing tasks but it is inefficient when it comes to intensive packet processing, giving rise to the DPU.
“The CPU is just not effective from a total cost of ownership, power and performance point of view,” says Nigel Alvares, vice president of solutions marketing at Marvell.
Data-centric tasks
The DPU is used for smart network interface controller (SmartNIC) cards found in computer servers. The DPU is also suited for standalone tasks at the network edge and for 5G.
Marvell says the Octeon DPU can be used for data centres, 5G wireless transport, SD-WAN, and fanless boxes for the network edge.
Data centre computation is moving from application-centric to more data-centric tasks, says Marvell. Server applications used to host all the data they needed when executing algorithms. Now applications gather data from various compute clusters and locations.
“The application doesn’t have all the data but there is a lot of data that needs to be pumped into the application from many points,” says Jeffrey Ho, senior product manager at Marvell. “So a lot of network overlay, a lot of East-West traffic.”
This explains the data-centric nature of tasks or, as Ho describes it, the data centre appearing as a mesh of networks: “It’s a core network, it is a router network, it is an enterprise network – all in one block.”
Octeon 10 archtecture
The Octeon 10 family uses ARM’s latest core architecture, the Neoverse N2 processor, Arm’s first Armv9 Infrastructure CPU, for general-purpose computational tasks. Each ARM core has access to hierarchical cache memory and external DDR5 SDRAM memory.
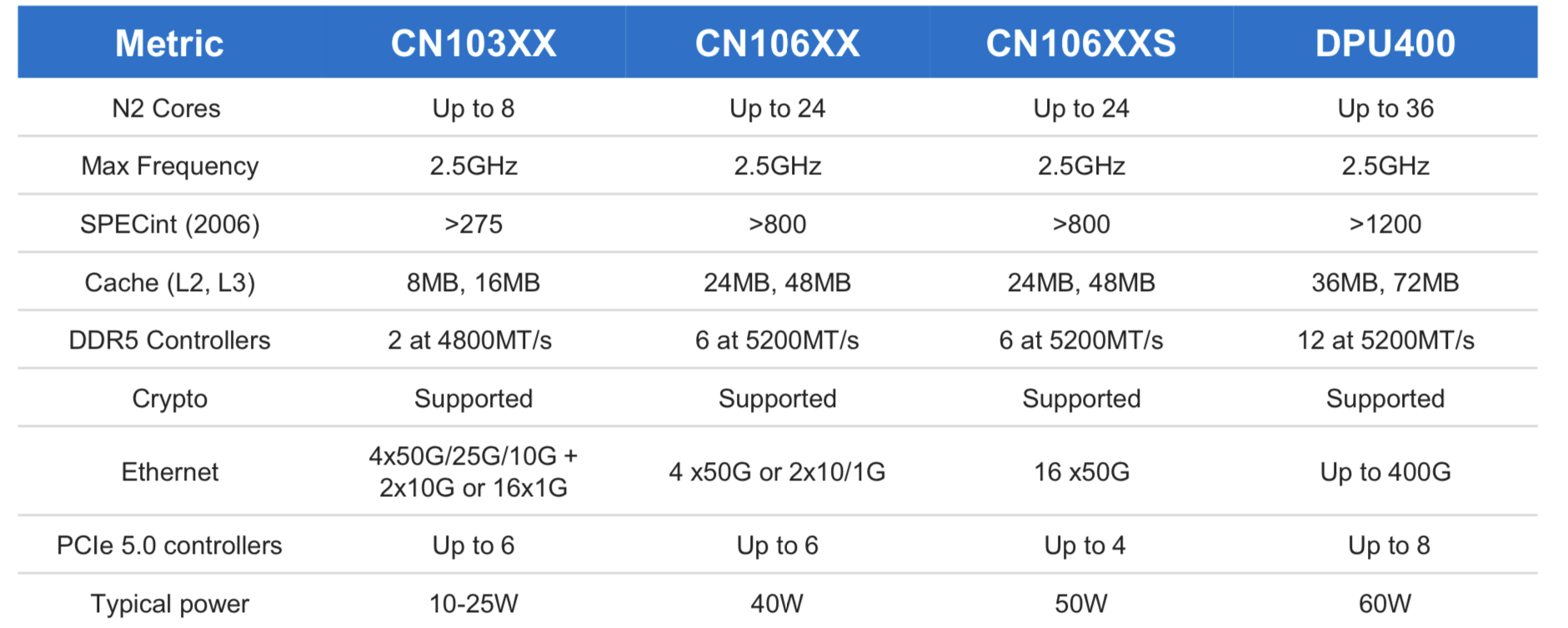
The initial Octeon 10 family members range from the CN103XX which has up to eight ARM N2 cores, each with Level 1 and private Level 2 cache and shared level 2 and 3 caches (8MB and 16MB, respectively).
The most powerful DPU of the Octeon 10 family is the DPU400 which will have up to 36 ARM cores and 36MB level 2 and 72MB level 3 caches.
“Then you have the acceleration hardware that is very friendly to this generic compute,” says Ho.
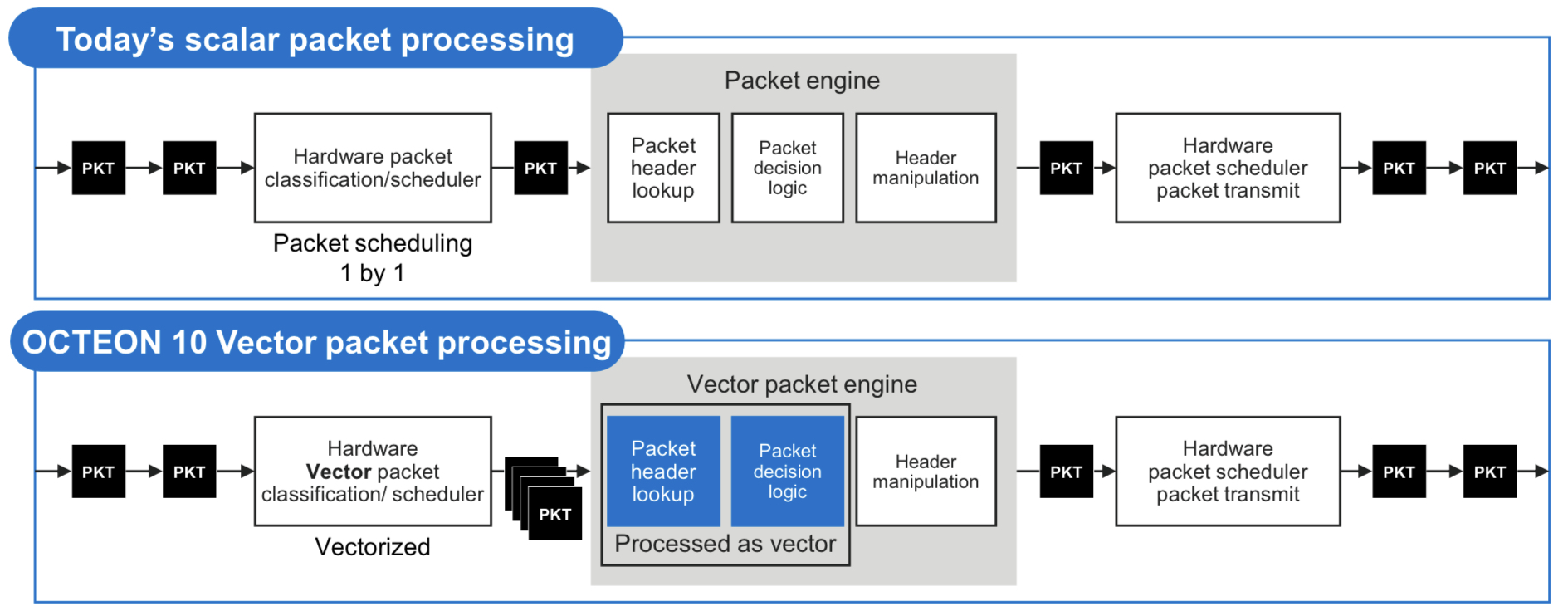
One custom IP block is for vector packet processing (VPP). VPP has become popular since becoming available as open-source software that batch-processes packets with similar attributes. Marvell says that until now, the hardware processed the packets one at a time such that the potential of VPP has not been fully realised.
The Octean 10 is the first device family to feature hardware for VPP acceleration. Accordingly, only one look-up table operation and one logical decision may be required before header manipulation is performed for each of the grouped packets. The specialised hardware accelerates VPP by between 3-5x.
The DPU also integrates on-chip hardware for machine-learning inferencing tasks.
Machine learning can be applied to traffic patterns on a compute cluster such that every day or so, newly learned models can be downloaded onto the DPU for smart malware detection. This is learnt behaviour; no rules need be written in code, says Marvell. Machine learning can determine if a packet is malware to an accuracy of 80 per cent, says Ho.
The hardware can even identify suspect packets by learning application types even when the packets themselves are encrypted using the IPSec protocol.
The DPU’s machine learning inference hardware can also be used for other tasks such as beamforming optimisation in cellular networks.
As for the 400-gigabit rating of the Octeon DPU, this is the maximum input and output that a CPU can cope with if every packet needs processing. And when each packet passes through the IPsec encyption engines, the maximum line rate is 400 gigabits.
In turn, if a packet need not pass through the CPU or no cryptography is required, one terabit of Layer 2/ Layer 3 switching can be done on-chip.
“All these are separate accelerator capability of the platform,” says Ho. The data path bandwidth of the DPU is 400Gbps+, IPSec throughput is 400Gbps+, and the switch capability is 1 terabit.”
Using software, the DPU accelerators are configured according to the data processing needs which may use all or some of the on-chip accelerators, he says.

4G and 5G cellular systems
For radio access networks, the radio head units talk to a distributed unit (DU) and a centralised unit (CU). (See diagram.)

The DU chassis houses six or eight line cards typically. The DU has a main controller that connects all the signals and backhauls them to the CU. This requires a two-chip solution with a switch chip next to each Octeon.
Using a 5nm process, the switch-integrated Octeon DPU reduces the DU’s overall power consumption and bill of materials. This Octeon DPU can be used for the DU, the fronthaul gateway and even the CU.
The DPU also exploits the 1-terabit switching capacity for the DU chassis example. Here, six Octeon Fusion-O chips, which perform Layer 1 processing, are connected to six radio units. Each of the six Fusion-O chips connects to the DPU via a 50-gigabit serialiser/ deserialiser (serdes).
Typical DU designs may use two Octeon DPUs, the second being a standby host DPU. This accounts for six line cards and two Octeon DPUs per DU chassis.
Market status
Marvell says that for 100-gigabit-throughput DPUs, up to 60 per cent of volumes shipped are used in the cloud and 40 per cent at the network edge.
Since throughput rates in the cloud are growing faster than the network edge, as reflected with the advent of 200- and 400-gigabit SmartNIC cards, the overall ratio of devices used for the cloud will rise.
The first two Octeon 10 devices taped out two months ago were the CN106XX and CN106XXS. These devices will sample in the second half of 2021.
The two will be followed by the CN103XX which is expected around spring 2022 and following that will be the DPU400.

Silicon Photonics: Fueling the Next Information Revolution
New book to be published in December 2016

Silicon Photonics: Fueling the Next Information Revolution is the title of the book Daryl Inniss and I have just completed.
We started writing the book at the end of 2014. We felt the timing was right for a silicon photonics synthesis book that assesses the significant changes taking place in the datacom, telecom, and semiconductor industries, and explains the market opportunities that will result and the role silicon photonics will play.
Silicon photonics is coming to market at a time of momentous change. Internet content providers are driving new requirements as they scale their data centres. The chip industry is grappling with the end of Moore’s law. And the telecom community faces its own challenges as the bandwidth-carrying capacity of fibre starts to be approached.
Silicon photonics will be a key technology for a post–Moore’s law era, and it will be the chip industry, not the photonics industry, that will drive optics
Each of these changes – the data center, the end of Moore’s law, and a looming capacity crunch – is significant in its own right. But collectively they signify a need for new thinking regarding chips, optics, and systems. Such requirements will also give rise to new business opportunities and industry change. Silicon photonics is arriving at an opportune time.
Despite this, the optical industry still questions the significance of silicon photonics while, for the chip industry, optics remains a science peripheral to their daily concerns. This too will change.
The book discusses how silicon photonics is set to influence both industries. For the optical industry, the technology will allow designs to be tackled in new ways. For the chip industry, silicon photonics may be a peripheral if interesting technology, but it will impact chip design.
The focus of the book is the telecom and datacom industries; these are and will remain the primary markets for silicon photonics for the next decade at least. But we also note other developments where silicon photonics can play an important role.
Silicon photonics will be a key technology for a post–Moore’s law era, and it will be the chip industry, not the photonics industry, that will drive optics.
The book is being published by Elsevier’s Morgan Kaufman and will be available from mid-December. To see the contents of the book, click here.
Mobile backhaul chips rise to the LTE challenge
The Long Term Evolution (LTE) cellular standard has a demanding set of mobile backhaul requirements. Gazettabyte looks at two different chip designs for LTE mobile backhaul, from PMC-Sierra and from Broadcom.
 "Each [LTE Advanced cell] sector will be over 1 Gig and there will be a need to migrate the backhaul to 10 Gig"
"Each [LTE Advanced cell] sector will be over 1 Gig and there will be a need to migrate the backhaul to 10 Gig"
Liviu Pinchas, PMC-Sierra
LTE is placing new demands on the mobile backhaul network. The standard, with its use of macro and small cells, increases the number of network end points, while the more efficient bandwidth usage of LTE is driving strong mobile traffic growth. Smartphone mobile data traffic is forecast to grow by a factor of 19 globally from 2012 to 2017, a compound annual growth rate of 81 percent, according to Cisco's visual networking index global mobile data traffic forecast.
Mobile networks backhaul links are typically 1 Gigabit. The advent of LTE does not require an automatic upgrade since each LTE cell sector is about 400Mbps, such that with several sectors, the 1 Gigabit Ethernet (GbE) link is sufficient. But as the standard evolves to LTE Advanced, the data rate will be 3x higher. "Each sector will be over 1 Gig and there will be a need to migrate the backhaul to 10 Gig," says Liviu Pinchas, director of technical marketing at PMC.
One example of LTE's more demanding networking requirements is the need for Layer 3 addressing and routing rather than just Layer 2 Ethernet. LTE base stations, known as eNodeBs, must be linked to their neighbours for call handover between radio cells. To do this efficiently requires IP (IPv6), according to PMC.
The chip makers must also take into account system design considerations.
Equipment manufacturers make several systems for the various backhaul media that are used: microwave, digital subscriber line (DSL) and fibre. The vendors would like common silicon and software that can be used for the various platforms.
Broadcom highlights how reducing the board space used is another important design goal, given that backhaul chips are now being deployed in small cells. An integrated design reduces the total integrated circuits (ICs) needed on a card. A power-efficient chip is also important due to thermal constraints and the limited power available at certain sites.
"Integration itself improves system-level power efficiency," says Nick Kucharewski, senior director for Broadcom’s infrastructure and networking group. "We have taken several external components and integrated them in one device."
WinPath4
PMC's WinPath4 supports existing 2G and 3G backhaul requirements, as well as LTE small and macro cells. A cell-side routers that previously served one macrocell will now have to serve one macrocell and up to 10 small cells, says PMC. This means everything is scaled up: a larger routing table, more users and more services.
To support LTE and LTE Advanced, WinPath4 has added additional programmable packet processors - WinGines - and hardware accelerators to meet new protocol requirements and the greater data throughput.
The previous generation 10Gbps WinPath3 has up to 12 WinGines, WinGines are multi-threaded processors, with each thread involving packet processing. Tasks performed include receiving, classifying, modifying, shaping and transmitting a packet.
The 40Gbps WinPath4 uses 48 WinGines and micro-programmable hardware accelerators for such tasks as packet parsing, packet header extraction and traffic matching, tasks too processing-intensive for the WinGines.
WinPath4 also support tables with up to two million IP destination addresses, up to 48,000 queues with four levels of hierarchical traffic shaping, encryption engines to implement the IP Security (IPsec) protocol and supports the IEEE 1588v2 timing protocol.
Two MIPs processor core are used for the control tasks, such as setting up and removing connections.
WinPath4 also supports the emerging software-defined networking (SDN) standard that aims to enhance network flexibility by making underlying switches and routers appear as virtual resources. For OpenFlow, the open standard use for SDN, the processor acts as a switching element with the MIPS core used to decode the OpenFlow commands.
StrataXGS BCM56450
Broadcom says its latest device, the BCM56450, will support the transition from 1GbE to 10GbE backhaul links, and the greater number of cells needed for LTE.
The BCM56450 will be used in what Broadcom calls the pre-aggregation network. This is a first level of aggregation in the wireline network that connects the radio access network's macro and small cells.
Pre-aggregation connects to the aggregation network, defined by Broadcom as having 10GbE uplinks and 1GbE downlinks. The BCM56450 meets these requirements but is referred as a pre-aggregating device since it also supports slower links such as microwave links or Fast Ethernet.
The BCM56450 is a follow-on to Broadcom's 56440 device announced two years ago. The BCM56450 upgrades the switching capacity to 100 Gigabit and doubles the size of the Layer 2 and Layer 3 forwarding tables.
The BCM56450 is one of a family of devices offering aggregation, from the edge through to 100GbE links deep in the network.
The network edge BCM56240 has 1GbE links and is designed for small cell applications, microwave units and small outdoor units. The 56450 is next in terms of capacity, aggregating the uplinks from the 240 device or linking directly to the backhaul end points.
The uplinks of the 56450 are 10GbE interfaces and these can be interfaced to the third family member, the BCM56540. The 56540, announced half a year ago, supports 10GbE downlinks and up to 40GbE uplinks.
The largest device, the BCM56640, used in large aggregation platforms takes 10GbE and 40GbE inputs and has the option for 100GbE uplinks for subsequent optical transport or routing. The 56640 is classed as a broadband aggregation device rather than just for mobile.
Features of the BCM56450 include support for MPLS (MultiProtocol Label Switching) and Ethernet OAM (operations, administration and maintenance), QoS and hardware protection switching. OAM performs such tasks as checking the link for faults, as well as performing link delay and packet loss measurements. This enables service providers to monitor the network's links quality. The device also supports the 1588 timing protocol used to synchronise the cell sites.
Another chip feature is sub-channelisation over Ethernet that allows the multiplexing of many end points into an Ethernet link. "We can support a higher number of downlinks than we have physical serdes on the device by multiplexing the ports in this way," says Kucharewski.
The on-chip traffic manager can also use additional, external memory if increasing the system's packet buffering size is needed. Additional buffering is typically required when a 10GbE interface's traffic is streamed to lower speed 1GbE or a Fast Ethernet port, or when the traffic manager is shaping multiple queues that are scheduled out of a lower speed port.
The BCM56450 integrates a dual-core ARM Cortex-A9 processor to configure and control the Ethernet switch and run the control plane software. The chip also has 10GbE serdes enabling the direct interfacing to optical transceivers.
Analysis
The differing nature of the two devices - the WinPath4 is a programmable chip whereas Broadcom's is a configurable Ethernet switch - means that the WinPath4 is more flexible. However, the greater throughput of the BCM56450 - at 100Gbps - makes it more suited to Carrier Ethernet switch router platforms. So says Jag Bolaria, a senior analyst at The Linley Group.
The WinPath4 also supports legacy T1/E1 TDM traffic whereas Broadcom's BCM56450 supports Ethernet backhaul only
The Linley Group also argues that the WinPath4 is more attractive for backhaul designers needing SDN OpenFlow support, given the chip's programmability and larger forwarding tables.
The WinPath4 and the BCM56450 are available in sample form. Both devices are expected to be generally available during the first half of 2014.
Further reading:
A more detailed piece on the WinPath4 and its protocol support is in New Electronics. Click here
The Linley Group: Networking Report, "Broadcom focuses on mobile backhaul", July 22nd, 2013. Click here (subscription is required)
Carrier Ethernet switch chip for wireless small cells
- 6-port low power 12 Gigabit Carrier Ethernet switch chip
- Used for intra and inter-board comms, and back-hauling
- Supports MPLS and MPLS-TP

"Multi-carrier OA&M performance monitoring allows you to manage your network for your users through another carrier’s network”
Uday Mudoi, Vitesse Semiconductor
Vitesse Semiconductor has launched an Ethernet switch chip for Long Term Evolution (LTE) small cells.
Small cells are being adopted by mobile operators as a complement to their existing macrocells to boost signal coverage and network capacity. The small cells include microcells and picocells as well as femtocells for the enterprise.
The Serval Lite chip, the VSC7416, from Vitesse will be used to aggregate and switch traffic and will reside at the interface between the access and the pre-aggregation segments of the mobile network.
According to Uday Mudoi, director of product marketing at Vitesse, two units make up a carrier’s small cell: the base station and the back-hauling. The base station itself comprises baseband and general purpose processing. “What we are seeing on a base station – whether it is a macro or a small cell – is the use of multi-core processors, and you may need more than one such device on the baseband card,” says Mudoi. The Serval Lite IC can be used as an interface between the baseband and general purpose processors, and to other hardware on the card.
 The basestation features baseband (BB) and general purpose processing (GPP) cards. Source: Vitesse
The basestation features baseband (BB) and general purpose processing (GPP) cards. Source: Vitesse
The backhaul unit also features the Serval Lite IC. “The backhaul is more interesting from a switch perspective,” says Mudoi. The switch takes traffic from the base stations and places it on the outgoing interface, typically a microwave or fibre link, says Mudoi.
The switch also supports Carrier Ethernet for the traffic back-hauling. Such features include hierarchical quality of service (QoS), performance monitoring and operations, administration and management (OA&M). "Multi-carrier OA&M performance monitoring allows you to manage your network for your users through another carrier’s network,” says Mudoi.
Switch characteristics
The Serval Lite is implemented using a 65nm CMOS process. The IC has six ports: four at 1 Gigabit Ethernet (GbE) and two that run at 1GbE or 2.5GbE. There is also a choice of NPI and PCI Express interfaces to connect to processors.
The chip has a full line rate switching capacity of 12 Gigabit. “It is a standard switching device, from any port to any port, that is standards compliant,” says Mudoi.
The switch supports the IEEE1588v2 timing protocol needed to synchronise between cell sites. The device also supports MPLS (Multiprotocol Label Switching) and MPLS-TP (Multiprotocol Label Switching Transport Profile).
“The 1588 timing issue is more complex when you are dealing with small cells,” says Mudoi. The back-hauling happens over millimeter wave or microwave links which adds extra timing constraints. This requires additional hardware to support the timing standard.
The device has been designed to achieve a low power consumption of typically 1.5W with the maximum being 3W. Vitesse has stripped out a T1/E1 processor used for back-hauling, with the chip supporting Ethernet only. The device also adheres to the IEEE 802.3az (Energy Efficient Ethernet), powering down the ports when inactive.
The switch features a single core 416 MHz MIPS processor used for overall management of the small cell. Samples of the VSC7416 are now available.
MultiPhy targets low-power coherent metro chip for 2013
MultiPhy has given first details of its planned 100 Gigabit coherent chip for metro networks. The Israeli fabless start-up expects to have samples of the device in 2013.

"We can tolerate greater [signal] impairments which means the requirements on the components we can use are more relaxed"
Avi Shabtai, CEO of MultiPhy
"Coherent metro is always something we have pushed," says Avi Shabtai, CEO of MultiPhy. Now, the company says it is starting to see a requirement for coherent technology's deployment in the metro. "Everyone expects to see it [coherent metro] in the next 2-3 years," he says. "Not tomorrow; it will take time to develop a solution to hit the target-specific [metro] market."
MultiPhy is at an advanced stage in the design of its coherent metro chip, dubbed the MP2100C. "It is going to be a very low power device," says Shabtai. MultiPhy is not quoting target figures but in an interview with the company's CTO, Dan Sadot, a figure of 15W was mentioned. The goal is to fit the design within a 24W CFP. This is a third of the power consumed by long-haul coherent solutions.
The design is being tackled from scratch. One way the start-up plans to reduce the power consumption is to use a one-sample-per-symbol data rate combined with the maximum-likelihood sequence estimation (MLSE) algorithm.
MultiPhy has developed patents that involve sub-Nyquist sampling. This allows the analogue-to-digital converters and the digital signal processor to operate at half the sampling rate, saving power. To use sub-Nyquist sampling, a low-pass anti-aliasing filter is applied but this harms the received signal. Using the filter, sampling at half the rate can occur and using the MLSE algorithm, the effects of the low-pass filtering can be countered. And because of the low-pass filtering, reduced bandwidth opto-electronics can be used which reduces cost.
This low-power approach is possible because the reach requirements in metro, up to 1,000km, is shorter than long haul/ ultra long haul optical transmission links. The shorter-reach requirements also impact the forward error correction codes, needed which can lessen the processing load, and the components, as mentioned. "We can tolerate greater [signal] impairments which means the requirements on the components we can use are more relaxed," says Shabtai.
The company also revealed that the MP2100C coherent device will integrate the transmitter and receiver on-chip.
MultiPhy says it is working with several system vendor and optical module partners on the IC development. Shabtai expects the first industry products using the chip to appear in 2014 or 2015. The timing will also be dependent on the cost and power consumption reductions of the accompanying optical components.
 A 100Gbps direct-detection optical module showing MultiPhy's multiplexer and receiver ICs. The module shown is a WDM design. Source: MultiPhy
A 100Gbps direct-detection optical module showing MultiPhy's multiplexer and receiver ICs. The module shown is a WDM design. Source: MultiPhy
100Gbps direct detection multiplexer chip
MultiPhy has also announced a multiplexer IC for 100 Gigabit direct detection. The start-up can now offer customers the MP1101Q, a 40nm CMOS multiplexer complement to its MP1100Q receiver IC that includes a digital signal processor to implements the MLSE algorithm. The MP1100Q was unveiled a year ago.
Testing the direct-detection chipset, MultiPhy says it can compensate +/-1000ps/nm of dispersion to achieve a point-to-point reach of 55km. No other available solution can meet such a reach, claims MultiPhy.
MultiPhy's direct-detection solution also enables 10 Gigabit-per-second (Gbps) opto-electronics components to be used for the transmit and receive paths. At ECOC, MultiPhy announced that it has used Sumitomo Electric's 10Gbps 1550nm externally-modulated lasers (EMLs) to demonstrate a 40km reach.
Using such 10Gbps devices simplifies the design since no 25Gbps components are required. It will also enable more optical module makers to enter the 100 Gigabit marketplace, claims MultiPhy. "It is twice the distance and about half of the cost of any other solution on the market - much below $10,000," says Shabtai.
 MultiPhy's HQ in Ness Ziona, Israel
MultiPhy's HQ in Ness Ziona, Israel
The multiplexer device can also be used for traditional 4x28Gbps WDM solutions to achieve a reach in existing networks of up to 800km.
MultiPhy says that it expects the overall 100 Gigabit direct detection market to number 4 optical module makers and 4-5 system vendors by the end of 2012. At present ADVA Optical Networking is offering a 100Gbps direct-detection CFP-based design. ECI Telecom has detailed a 5x7-inch MSA direct-detection 100 Gigabit module, while Finisar and Oclaro have both announced that they are coming to market with 100Gbps direct-detection modules.
Fibre-to-the-FPGA
Part 1: FPGAs
Programmable logic chip vendor Altera is developing FPGAs with optical interfaces. But is there a need for such technology and how difficult will it be to develop?
FPGAs with optical interfaces promise to simplify high-speed interfacing between and within telecom and datacom systems. Such fibre-based FPGAs, once available, could also trigger novel system architectures. But not all FPGA vendors believe optical-enabled FPGAs’ time has come, arguing that cost and reliability hurdles must be overcome for system vendors to embrace the technology

“One of the advantages of using optics is that you haven’t got to throw your backplanes away as [interface] speeds increase.”
Craig Davis, Altera
Altera announced in March that it is developing FPGAs with optical interfaces. The FPGA vendor has yet to detail its technology demonstrator but says it will do so later this year. Altera describes the advent of optically-enabled FPGAs as a turning point, driven by the speed-reach tradeoff of electrical interfaces coupled with the rising cost of elaborate printed circuit board (PCB) materials needed for the highest speed interfaces.
Interface speeds continue to rise. The Interlaken interface has a channel rate of up to 6.375 Gigabit-per-second (Gbps) while the Gen 3.0 PCI Express standard uses 8.0 Gbps lanes. Meanwhile 16 Gigabit Fibre Channel standard operates at 14.1 Gbps while 100 Gigabit interfaces for Ethernet and line-side optical transport are moving to a four-channel electrical interface that almost doubles the lane rates to 25-28 Gbps. The CFP2 optical module for 100 Gigabit, to be introduced in 2012, will use the four-channel electrical interface.
Copper interfaces such channel speeds but at the expense of reach. Craig Davis, senior product marketing engineer at Altera, cites the 10GBASE-KR 10Gbps backplane standard as an example of the bandwidth-reach the latest FPGAs can achieve: 40 inches including the losses introduced by the two connectors at each end.

“Our interactions with our customers are primarily for products that are not going to see the light of day for several years”
Panch Chandrasekaran, Xilinx
Work is being undertaken to development very short reach electrical interfaces at 28Gbps for line cards and electrical backplanes. “You are talking 4 to 6 inches of trace to a CFP2 module or a chip-to-chip interface,” says Panch Chandrasekaran, Xilinx’s senior product marketing manager, high-speed serial I/O. “Honestly, this is going to be a challenge but we usually figure out a way how to do things.”
The faster the link, the more energy has to be put into the signals and the more losses you have on the board, says Davis: “Signal integrity aspects also get more difficult, the costs go up as does the power consumption.”
According to Altera, signal losses increase 3.5x going from 10 to 30Gbps. To match the losses at 10Gbps when operating at these higher speeds, complex PCB materials such as N4000-13 EP SI and Megtron 6 are needed rather than the traditional FR4 design. However, the cost of designing and manufacturing such PCBs can rise by five-fold.
In contrast, using an optically-enabled FPGA simplifies PCB design. “For traditional chip-to-chip on a line card, optics does have a benefit because you can trade off the number of layers on a PCB,” says Davis. Such an optical-based design also offers future-proofing. “A lot of the applications we’ll be looking to support are across backplanes and between shelves,” says Davis. “One of the advantages of using optics is that you haven’t got to throw your backplanes away as [interface] speeds increase.”
FPGAs with optical interfaces also promise new ways to design systems. Normally when one line card talks to another on different shelves it is via a switch card on each shelf. Using an FPGA with an optical interface, the cards can talk directly. “People are looking at this,” says Davis. “You could take that to the extreme and go to the next cabinet which makes a much easier system design.”
Altera says vendors are interested in optical-enabled FPGAs for storage systems. Here interlinked disk drives require multiple connectors between boards. “There is an argument that it becomes a simpler system design with one FPGA taking directly to another or one chip directly to another,” says Davis “The more advanced R&D groups within certain companies are investigating the best route forward.”
But while FPGA companies agree that optical interfaces will be needed, there is no consensus on timing. “Xilinx has been looking at this technology for a while now,” says Chandrasekaran. “There is a reason why we haven’t announced it: we have a little while to go before key ecosystem and technology questions are answered.”
The mechanical and reliability issues of systems are stringent and the optical option must prove that it can deliver what is needed, says Chandrasekaran. “It is possible to do at the moment but the cost and reliability equation hasn’t been fully solved.”
Xilinx also says that while it is discussing the technology with customers, the requirement for such FPGA-based optical interfaces is some way off. “Our interactions with our customers are primarily for products that are not going to see the light of day for several years,” says Chandrasekaran
“Customers are always excited to hear about integration play,” says Gilles Garcia, director, wired communications business unit at Xilinx. But ultimately end customers care less about the technology as long as the price, power and board real-estate requirements are met. “What we are seeing with this [optical-enabled FPGA] technology is that it is not answering the requirements we are seeing from our large customers that are looking for their next-generation systems,” says Garcia
FPGA vendor Tabula also questions the near-term need for such technology. Alain Bismuth, vice president of marketing at Tabula, says nearly all the ports shipped today are at speeds of 10Gbps and below. Even in 2014, the number of 40Gbps ports forecast will only number 650,000, he says.
For Bismuth, two things must happen before optically-enabled FPGAs become commonplace. “You can build them in high volumes reliably and with good yields without incurring higher costs than a separate, discrete [FPGA and optical module] solution,” says Bismuth. “Second, the emergence in interesting volume of networks at 100 Gig and beyond to justify the integration effort.” Such networks are emerging at a “fairly slow pace”, he says.
Meanwhile Altera’s development work continues apace. “We are working with partners to develop the system and we will be demonstrating the optics-on-a-chip in Q4,” says Bob Blake, corporate and product marketing manager, Altera Europe. Altera says its packaged FPGA and optical interface will support short reach links up to 100m and be based on multimode fibre. “All we have announced is that the optical interface will be on the package and it will connect into the FPGA,” says Davis.
The technology will also use 10Gbps optical interface yet the company has detailed that its Stratix V FPGA family supports electrical transceivers at 28Gbps. “The optical interface can go higher than that [10Gbps] so in future we can target 28Gbps and beyond,” says Davis.
Optical partners
Optical component and transceiver firms such as Avago Technologies, Finisar and Reflex Photonics all have parallel optical devices - optical engines - that support up to 12 channels at 10Gbps. Avago’s MicroPod 12x10Gbit/s optical engine measures 8x8mm, for example.
None of the optical vendors would comment on its involvement with Altera’s optical-enabled FPGA.
Avago Technologies says that as FPGA interface speeds move to 10 Gbps and beyond, its customers are finding they need to move from copper to optical interfaces to maintain bandwidth for board, chassis, and system-level interconnect. “In line with this announcement from Altera, we are investing the time to verify Avago optical modules with FPGA SERDES blocks to ensure that FPGA users can design optical interfaces with confidence,” says Victor Krutul, director of marketing for fibre optic products at Avago.
Finisar too only talks about general trends. “We are seeing many technology leaders moving optics further onto the board and deeper into the system,” says Katharine Schmidtke, director of strategic marketing for Finisar. “This approach offers a number of advantages including improving signal integrity and reducing power consumption on copper traces at higher bandwidths.”
Reflex Photonics says that it has the technology and products to realise optically-enabled IC packages. “We are working with more than one IC company to bring optically-enabled IC packages to market,” says Robert Coenen, vice president, sales and marketing at Reflex.
For Coenen, FPGAs represent the first step in bringing optics to the IC package: “Due to their penetration into niche markets, FPGAs make the most sense to create what will ultimately be a huge market in optically-enabled IC packages.”
Coenen stresses that optics to the IC package is a significant shift in how optical links are used and so it will take time for this application to take hold. However, as the cost per bit decreases, optics will start being used in additional applications including switch ASICs, microprocessors and graphics processors.
“The beauty of an MT-terminated ribbon fiber optical connection at the edge of the package is that this solution allows designers to use the additional high-speed optical connectivity without having to drastically change their design practices,” says Coenen. This is not the case with technologies such as PCB optical waveguides or free-space optical communication.
“I believe the Altera announcement is just the first in what will be many announcements of optical-to-the-IC-package technology in the coming year or two,” says Coenen.
Further reading
- Briefing Part 2: Boosting high performance computing with optics
- Altera White Paper: Overcome Copper Limits with Optical Interfaces
- Xilinx's 400 Gigabit Ethernet FPGA
- The InfiniBand roadmap gets redrawn
Webinar: MultiPhy on the 100G Direct Detect market
- An Ovum market forecast for 100 Gigabit Direct Detect to 2015
- The changes in the network creating demand for 100 Gigabit Direct Detect optical transport
- Emerging operator and vendor backing for the technology
- MultiPhy’s IC technology and its 100 Gigabit Direct Detect solution
- The performance metrics of 100 Gigabit Direct Detect
 "An internet giant is now firmly committed to an 80km pluggable solution. And if it is 80km and pluggable we know it is not coherent"
"An internet giant is now firmly committed to an 80km pluggable solution. And if it is 80km and pluggable we know it is not coherent"
Neal Neslusan, MultiPhy
Presenting the webinar for MultiPhy is Neal Neslusan, vice president of sales and marketing.
To view, please register by clicking here. You will then receive an email with a link to the 100 Gigabit webinar.
Further reading:
Xilinx's 400 Gigabit Ethernet FPGA
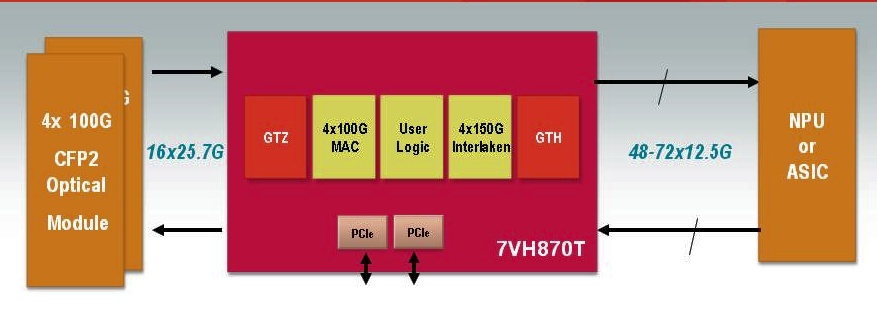 A single FPGA will support 400 Gigabit Ethernet duplex traffic. The FPGA can also support 4x100Gig MACs and 4x150Gbps Interlaken interfaces. Source: Xilinx
A single FPGA will support 400 Gigabit Ethernet duplex traffic. The FPGA can also support 4x100Gig MACs and 4x150Gbps Interlaken interfaces. Source: Xilinx
Why is it important?
Xilinx says its switch and router customers are more than doubling the traffic capacity of their platforms every three years. “They are looking for silicon that will support a doubling of capacity within the same form-factor and the same power budget,” says Giles Peckham, EMEA marketing director at Xilinx.
An FPGA has an advantage when compared to an application-specific standard product (ASSP) chip or an ASIC: being programmable and a volume-manufactured device, it is easier for an FPGA design to contend with changes in standards and the escalating cost of implementing chip designs in ever-finer CMOS geometries.
The Virtex-7HT will support 28 Gigabit-per-second (Gbps) transceivers (serial/ deserialiser or serdes). Used in a four-channel configuration, a 100Gbps interface can be implemented. Indeed the largest member of the Virtex-7HT family - the XC7VH870T - will have 16 x 28.05Gbps transceivers, enabling 4x100Gbps or even a 400 Gigabit Ethernet interface.
The 28Gbps transceivers will be used to interface to optical modules such as the emerging CFP2 pluggable form-factor. The CFP2 multi-source agreement is expected to be ratified in the second half of 2011 and start shipping in the second half of 2012, says Xilinx.
 “Network processors and ASICs are typically a [CMOS] process node or two behind us"
“Network processors and ASICs are typically a [CMOS] process node or two behind us"
Giles Peckham, Xilinx
And with the additional 72, 13.1Gbps transceivers on-chip, the XC7VH870T will have sufficient input-output (I/O) to support bi-directional 400 Gigabit Ethernet traffic. The FPGA's lower-speed 13.1Gbps serdes are included to interface to network processors (NPUs) or ASICs that only support the lower-speed transceivers. “Network processors and ASICs are typically a [CMOS] process node or two behind us – partly because of cost - such that they end up at a technology disadvantage, as in transceiver speed,” says Peckham.
The additional 13.1Gbps transceivers - only 40 of the 72 transceivers are needed for the 400 Gigabit Ethernet port – will enable the FPGA to interface to other chips.
Xilinx says it will be at least a year and possibly 18 months before samples of the Virtex-7HT FPGA family become available. But it is making the Virtex-7HT announcement now because it has tested successfully the 28Gbps transceiver design.
 Front panel evolution from 48 SFP+ to 4 CFPs to 8 CFP2s. Source: Xilinx
Front panel evolution from 48 SFP+ to 4 CFPs to 8 CFP2s. Source: Xilinx
What has been done
There are three devices in the Virtex-7HT family which have 4, 8 and 16, 28Gbps transceivers. Xilinx claims this is four times the transceiver count of any competing 28nm FPGA detailed to date. But Peckham admits that additional announcements from competitors are inevitable before the Virtex-7HT devices become available in 2012.
In September Altera announced that it had successfully demonstrated a 25Gbps transceiver test chip. And in November, Intel and Achronix Semiconductor formed a strategic relationship that will allow the FPGA start-up to use Intel's leading-edge 22nm CMOS manufacturing process.
The three Virtex-7HT FPGAs also come with different amounts of programmable logic cells, memory blocks and Xilinx’s XtremeDSP building blocks tailored for digital signal processing.
Xilinx says meeting the CEI-28G electrical interface jitter specification has proved challenging. At 10 Gigabit the signal period is 100 picoseconds (ps) and the jitter allowance is 35ps, while the signal period at 28Gbps is 35ps. “When you realise the jitter spec on the 10 Gigabit interface is the same as the full period in the 28 Gigabit spec – 35 picoseconds – there is quite a lot of work to be done in reducing the jitter when migrating to 28 Gigabit,” says Peckham.
Xilinx uses pre-emphasis techniques on the signals before they are transmitted across the printed circuit board to reduce loss. In addition, the FPGA maker has enhanced the noise isolation between the FPGA's digital and analogue CMOS circuitry. “The short spiky current loads in the digital circuitry can impact the noise in the analogue circuitry and increase the jitter,” says Peckham.
What next?

Xilinx has created a test vehicle 28Gbps transceiver. This allows Xilinx to validate and fine-tune the design. The rest of the FPGA design needs to be completed while another design iteration of the 28Gbps test vehicle is likely. “We have a lot of things to do yet,” he says.
Meanwhile system vendors can start to design their systems based on the FPGA family in advance of samples that are expected in the first half of 2012.
- For a video demonstration of the 28Gbps test vehicle, click here.
BroadLight’s GPON ICs: from packets to apps
BroadLight has announced its Lilac family of customer premise equipment (CPE) chips that support the Gigabit Passive Optical Network (GPON) standard.
The company claims its GPON devices with be the first to be implemented using a 40nm CMOS process. The advanced CMOS process, coupled with architectural enhancements, will double the devices' processing performance while improving by five-fold the packet-processing capability. The devices also come with a hardware abstraction layer that will help system vendors tailor their equipment.

"Traffic models and service models are not stable, and there are a lot of differences from carrier to carrier"
Didi Ivancovsky, BroadLight
Lilac will also act as a testbed for technologies needed for XG-PON, the emerging next generation GPON standard. XG-PON will support a 10 Gigabit-per-second (Gbps) downstream and 2.5Gbps upstream rate, and is set for approval by the International Telecommunication Union (ITU) in September.
Why is this important?
GPON networks are finally being rolled out by carriers after a slow start. Yet the GPON chip market is already mature; Lilac is BroadLight’s third-generation CPE family.
Major chip vendors such as Broadcom and Marvell are also now competing with the established GPON chip suppliers such as BroadLight and PMC-Sierra. “The [big] gorillas are entering [the market],” says Didi Ivancovsky, vice president of marketing at BroadLight.
BroadLight claims it has 60% share of the GPON CPE chip market. For the central office, where the optical line terminal (OLT) GPON integrated circuits (ICs) reside, the market is split between 40% merchant ICs and 60% FPGA-based designs. BroadLight claims it has over 90% of the OLT merchant IC market.
The Lilac family is Broadlight’s response to increasing competition and its attempt to retain market share as deployments grow.
GPON market
US operator Verizon with its FiOS service remains the largest single market in terms of day-to-day GPON deployments. But now significant deployments are taking place in Asia.
“Verizon might still be the largest individual deployer, but China Telecom and China Mobile are catching up fast,” says Jeff Heynen, directing analyst, broadband and video at Infonetics Research. “In fact, the aggregate GPON market in China is now larger than what Verizon has been deploying, given that Verizon’s OLT numbers have really slowed while its optical network terminal (ONT) shipments remain high at some 200,000 per quarter.”

“Verizon might still be the largest individual deployer, but China Telecom and China Mobile are catching up fast”
Jeff Heynen, Infonetics Research
Chinese operators are deploying both GPON and Ethernet PON (EPON) technologies. According to BroadLight, Chinese carriers are moving from deploying multi-dwelling unit (MDU) systems to single family unit (SFU) ONTs.
An MDU deployment involves bringing PON to the basement of a building and using copper to distribute the service to individual apartments. However such deployments have proved less popular that expected such that operators are favouring an ONT-per-apartment.
“Through this transition, China Telecom and China Unicom are also making the transition to GPON,” says Ivancovsky. “End–to-end prices of EPON and GPON are practically the same,” GPON has a download speed of 2.5Gbps and an upload speed of 1.25Gbps (Gbps) while for EPON it is 1.25Gbps symmetrical.
China Telecom and China Unicom are deploying GPON is several provinces whereas in major population centres the PON technology is being left unspecified; vendors can propose either the use of EPON or GPON. “This is a big change, really a big change,” says Ivancovsky.
In India, BSNL and a handful of private developers have been the primary GPON deployers, though the Indian market is still in its infancy, says Heynen. Ericsson has also announced a GPON deployment with infrastructure provider Radius Infratel that will involve 600,000 homes and businesses.
“I expect there to be a follow-on tender for BSNL later this year or early next year that will be twice the size of the first tender of 700,000 total GPON lines,” says Heynen. He also expects MTNL to begin deploying GPON early next year.
In other markets, Taiwan’s Chunghwa Telecom has issued its first tender for GPON. Telekom Malaysia is deploying GPON as is Hong Kong Broadband Network (HKBN), while in Australia the National Broadband Network Company will roll-out a 100Mbps fibre-to-the-home network to 90% of Australian premises over eight years working with Alcatel-Lucent.
“Let’s not forget about Europe, which has been basically dormant from a GPON perspective,” adds Heynen. “We now have commitments from France Telecom, Deutsche Telekom, and British Telecom to roll out more FTTH using GPON, which should help increase the overall market, which really was being driven by Telefonica, Portugal Telecom, and Eitsalat.”
Infonetics expects 2010 to be the first year that GPON revenue will exceed EPON revenue: US $1.4 billion worldwide compared to $1.02 billion. By 2014, the market research firm expects GPON revenue to reach $2.5 billion with EPON revenue - 1.25Gbps and 10Gbps EPON - to be US $1.5 billion. “At this point, China, Japan, and South Korea will be the only major EPON markets with many MSOs also using EPON for FTTH and business services,” says Heynen.
What’s been done?
BroadLight offers a range of devices in the Lilac family. It has enhanced the control processing performance of the CPE devices using 40nm CMOS, and has also added more network processor unit (NPU) cores to enhance the ICs’ data plane processing performance.
“It’s been the same story for some time now,” says Heynen. “System-on-chip vendors differentiate themselves on four key aspects: footprint, power consumption, speed and, most importantly, cost”
A key driver for upping the Lilac family’s control processor’s performance is to support the Java programming language and the OSGi Framework, says Ivancovsky. The OSGi Framework used with embedded systems has yet to be deployed on gateways but is becoming mandatory. This will enable the CPE gateway to run downloaded applications much as applications stores now complement mobile handsets.
BroadLight has also doubled to four the on-chip RunnerGrid NPU cores. “Traffic models and service models are not stable, and there are a lot of differences from carrier to carrier” says Ivancovsky. “This [on-chip] flexibility helps us to have a single device that can support many different requirements.”
As an example, Broadlights cites South Korean operator, SK Broadband, which is deploying an ONT supporting two gigabit Ethernet (GbE) ports – one for laptops and the other for the home’s set-top box. Thus a single GPON 2.5Gbps stream is delivered down the fibre and shared between the PON’s 32 or 64 ONTs, with each ONT having two 1GbE links.“The carrier wants to limit the IPTV downstream rate according to the service level agreement,” says Ivancovsky. Having the network processor as part of the CPE, the carrier can avoid deploying more more expensive NPUs at the central office.
The overall result is a Lilac family rated at 2,000 Dhrystone MIPS (DMIPS) and a packet processing capability of 15 million packets per second (Mpps) compared to BroadLight’s current-generation CPE family of 650-900 DMIPs and 3Mpps.
“Broadlight understands that you have to have a range of chips that provide flexibility across a wide range of CPE and infrastructure types,” says Heynen. The CPE demands of a Verizon differ markedly from those of China Telecom, for example, primarily because average-revenue-per-user expectations are so different. Verizon wants to provide the most advanced integrated CPE, with the ability to do TR-069 remote provisioning and both broadcast and on-demand TV, while China Telecom is concerned with achieving sustained downstream bandwidth, with IPTV being a secondary concern, he says.
Heynen also highlights the devices’ software stack with its open application programming interfaces (APIs) that allow third-party developers to develop applications on top of features already provided in BroadLight’s software stack.
“Residential gateway software stacks used to be dominated by Jungo (NDS). But now chipset companies are developing their own, which helps to reduce licensing costs on a per CPE basis,” says Heynen. “If a silicon vendor can provide a hardware abstraction layer like this, it makes it very attractive to system vendors who need an easy way to customise feature sets for a wide range of customers.”
Is the Lilac GPON family fast enough to support XG-PON?
“We are deep in the design of XG-PON end-to-end: one team is working on the OLT and one on the ONT,” says Ivancovsky. “We expect an FPGA prototype very early in 2011.”
The first XG-PON product will be an OLT ASIC rated at 40Gbps: supporting four XG-PON or 16 GPON ports. One XG-PON challenge is developing a 10Gbps SERDES (serialiser/ deserialiser), says Ivancovsky: “The SERDES in Lilac is a 10Gbps one, a preparation for XG-PON devices.”
Meanwhile, the first XG-PON CPE design will be implemented using an FPGA but the control processor used will be the one used for Lilac. As for data plane processing, NPUs will be added to the OLT design while more NPUs cores will be needed within the CPE device. “The number of cores in the Lilac will not be enough; we are talking about 40Gbps,” says Ivancovsky.
Lilac device members
Ivancovsky highlights three particular devices in the Lilac family that will start appearing from the fourth quarter of this year:
- The BL23530 aimed at GPON single family units with VoIP support. To reduce its cost, a low-cost packaging will be used.
- The BL23570 which is aimed at the integrated GPON gateway market.
- The BL23510, a compact 10x10mm IC to be launched after the first two. The chip’s small size will enable it to fit within an SFP form-factor transceiver. The resulting SFP transceiver can be added to connect a DSLAM platform, or upgrade an enterprise platform, to GPON.
“This new system-on-chip is a technology improvement, especially with respect to the residential gateway software layer, which is a requirement among most operators,” concludes Heynen. “But it should be noted this is an addition to, not a replacement for, existing BroadLight chips that solve different infrastructure requirements.”