
Drut tackles disaggregation at a data centre scale
- Drut’s DynamicXcelerator supports up to 4,096 accelerators using optical switching and co-packaged optics. Four such clusters enable the scaling to reach 16,384 accelerators.
- The system costs less and is cheaper to run, has lower latency, and better uses the processors and memory.
- The system is an open design supporting CPUs and GPUs from different vendors.
- DynamicXcelerator will ship in the second half of 2024.

Drut Technologies has detailed a system that links up to 4,096 accelerator chips. And further scaling, to 16,384 GPUs, is possible by combining four such systems in ‘availability zones’.
The US start-up previously detailed how its design can disaggregate servers, matching the processors, accelerators, and memory to the computing task at hand. Unveiled last year, the product comprises management software, an optical switch, and an interface card that implements the PCI Express (PCIe) protocol over optics.
The product disaggregates the servers but leaves intact the tiered Ethernet switches used for networking servers across a data centre.
Now the system start-up is expanding its portfolio with a product that replaces the Ethernet switches with optical ones. “You can compose [compute] nodes and drive them using our software,” says Bill Koss, CEO of Drut.
Only Google has demonstrated the know-how to make such a large-scale flexible computing architecture using optical switching.
Company background
Drut was founded in 2018 and has raised several funding rounds since 2021.
Jitender Miglani, founder and president of Drut, previously worked at MEMS-based optical switch maker, Calient Technologies.
Drut’s goal was to build on its optical switching expertise and add the components needed to make a flexible, disaggregated computing architecture. “The aim was building the ecosystem around optical switches,” says Miglani.
The company spent its first two years porting the PCIe protocol onto an FPGA for a prototype interface card. Drut showcased its prototype product alongside a third-party optical switch as part of a SuperMicro server rack at the Supercomputing show in late 2022.
Drut has spent 2023 developing its next-generation architecture to support clusters of up to 4,096 endpoints. These can be accelerators like graphics processing units (GPUs), FPGAs, data processing units (DPUs), or storage using the NVM Express (nonvolatile memory express).
The architecture, dubbed DynamicXcelerator, supports PCIe over optics to link processors (CPUs and GPUs) and RDMA (Remote Direct Memory Access) over optics for data communications between the GPUs and between the CPUs.
The result is the DynamicXcelerator system, a large-scale reconfigurable computing for intensive AI model training and high-performance computing workloads.
DynamicXcelerator
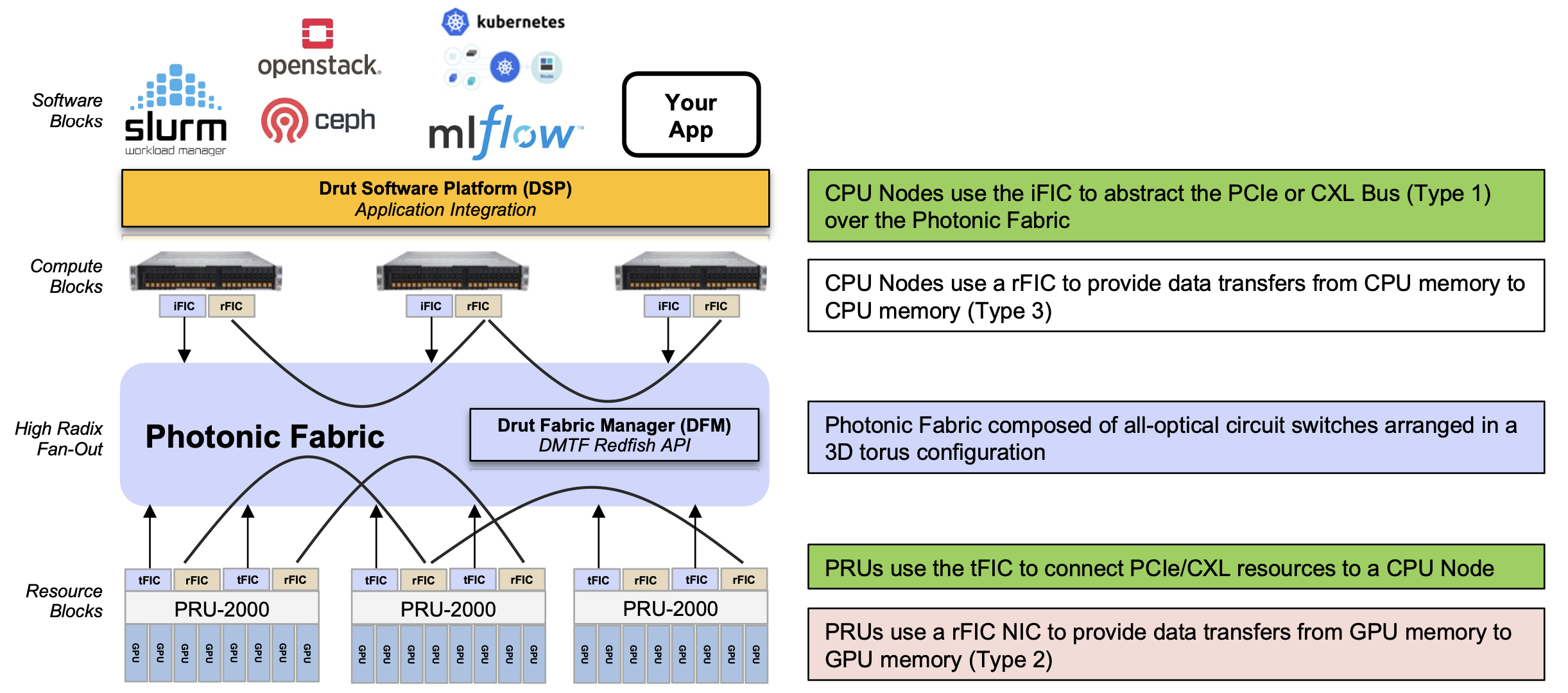
The core of the DynamicXcelerator architecture is a photonic fabric based on optical switches. This explains why Drut uses PCIe and RDMA protocols over optics.
Optical switches brings size and flexibility and by relaying optical signals, their ports are data-rate independent.
Another benefit of optical switching is power savings. Drut says an optical switch consumes 150W whereas an equivalent-sized packet switch consumes 1,700W. On average, an Infiniband or Ethernet packet switch draws 750W when used with passive cables. Using active cables, the switch’s maximum power rises to 1,700W. “[In contrast], a 32-64-128-144 port all-optical switch draws 65-150W,” says Koss.
Drut also uses two hardware platforms. One is the PCIe Resource Unit, dubbed the PRU-2000, which hosts eight accelerator chips such as GPUs. Unlike Nvidia’s DGX platform, which uses Nvidia GPUs such as the Hopper, or Google, which uses its TPU5 tensor processor unit (TPU), Drut’s PRU-2000 is an open architecture and can use GPUs from Nvidia, AMD, Intel, and others. The second class of platform is the compute node or server, which hosts the CPUs.
DynamicXcelerator’s third principal component are the FIC 2500 interface cards.
The iFIC 2500 card is similar to Drut’s current product’s iFIC 1000, which features an FPGA and four QSFP28s. However, the iFIC 2500 supports the PCIe 5.0 generation bus and the Compute Express Link (CXL) protocols. The two other FIC cards are the tFIC 2500 and rFIC 2500.
“The iFIC and tFIC are the same card, but different software images,” says Koss. “The iFIC fits into a compute node or server while the tFIC fits into our Photonic Resource Unit (PRU) unit, which holds GPUs, FPGAs, DPUs, NVMe, and the like.”
The rFIC provides RDMA over photonics for GPU-to-GPU memory sharing. The rFIC card for CPU-to-CPU memory transfers is due later in 2024.
Miglani explains that PCIe is used to connect the GPUs and CPUs, but for GPU-to-GPU communication, RDMA is used since even PCIe over photonics has limitations.
Certain applications will use hundreds and even thousands of accelerators, so a PCIe lane count is one limitation, distance is another; a 5ns delay is added for each metre of fibre. “There is a window where the PCIe specification starts to fall off,” says Miglani.
The final component is DynamicXcelerator’s software. There are two software systems: the Drut fabric manager (DFM), which controls the system’s hardware configuration and traffic flows, and the Drut software platform (DSP) that interfaces applications onto the architecture.
Co-packaged optics
Drut knew it would need to upgrade the iFIC 1000 card. DynamicXcelerator uses PCIe 5.0, each lane being 32 gigabit-per-second (Gbps). Since 16 lanes are used, that equates to 512 gigabits of bandwidth.
“That’s a lot of bandwidth, way more that you can crank out with four 100-gigabit pluggables,” says Koss, who revealed co-packaged optics will replace pluggable modules for the iFIC 2500 and tFIC 2500 cards.
The card for the iFIC and tFIC will use two co-packaged optical engines, each 8×100 gigabits. The total bandwidth of 1.6 terabits – 16×100-gigabit channels – is a fourfold increase over the iFIC 1000.
System workings
The system’s networking can be viewed as a combination of circuit switching and packet switching.
The photonic fabric, implemented as a 3D torus (see diagram), supports circuit switching. Using a 3D torus, three hops at most are needed to link any two of the system’s endpoints.
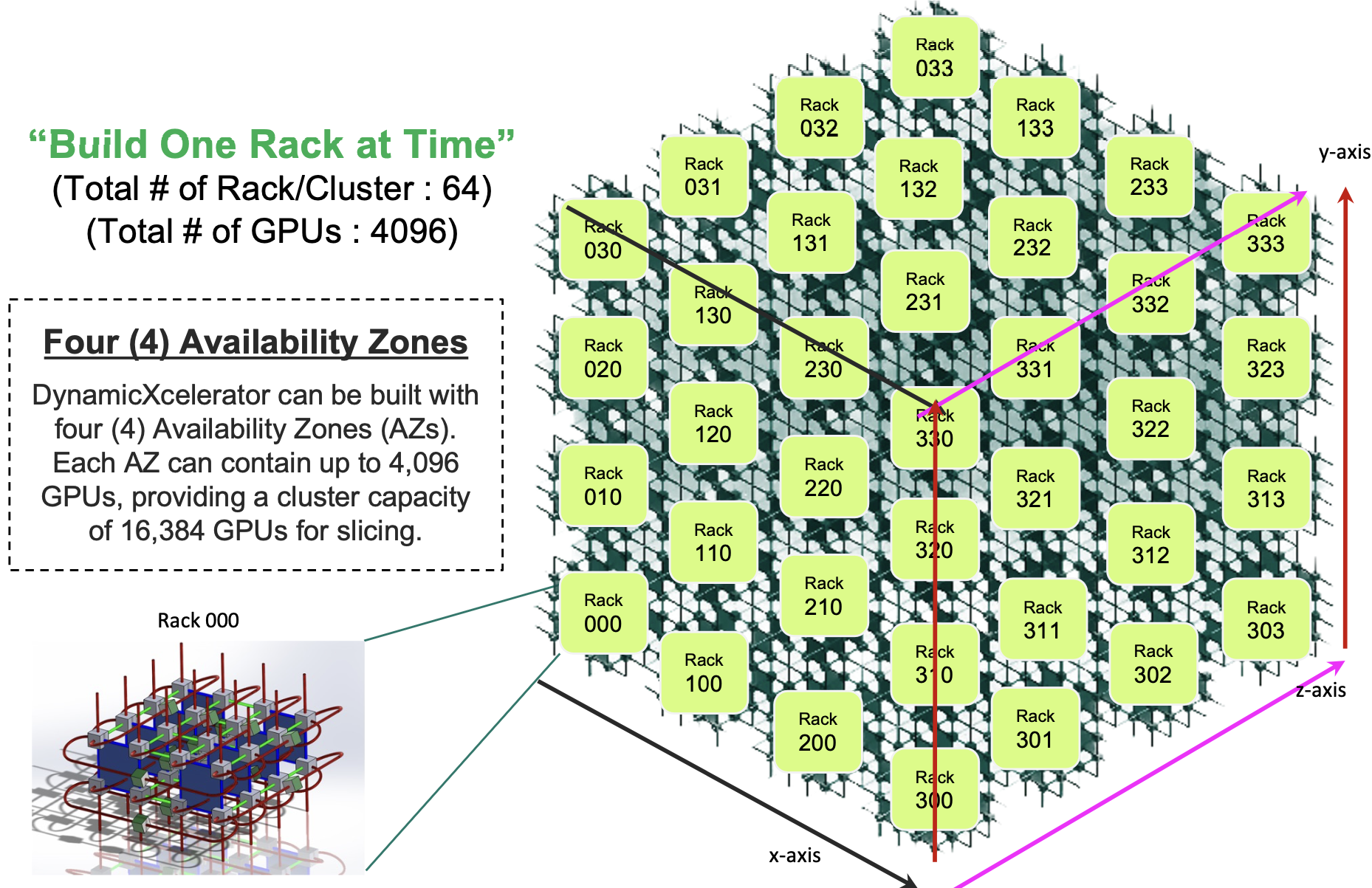
One characteristic of machine learning training, such as large language models, is that traffic patterns are predictable. This suits an architecture that can set the resources and the connectivity for a task’s duration.
Packet switching is not performed using Infiniband. Nor is a traditional spine-leaf Ethernet switch architecture used. The DynamicXcelerator does uses Ethernet but in the form of a small, distributed switching layer supported in each interface card’s FPGA.
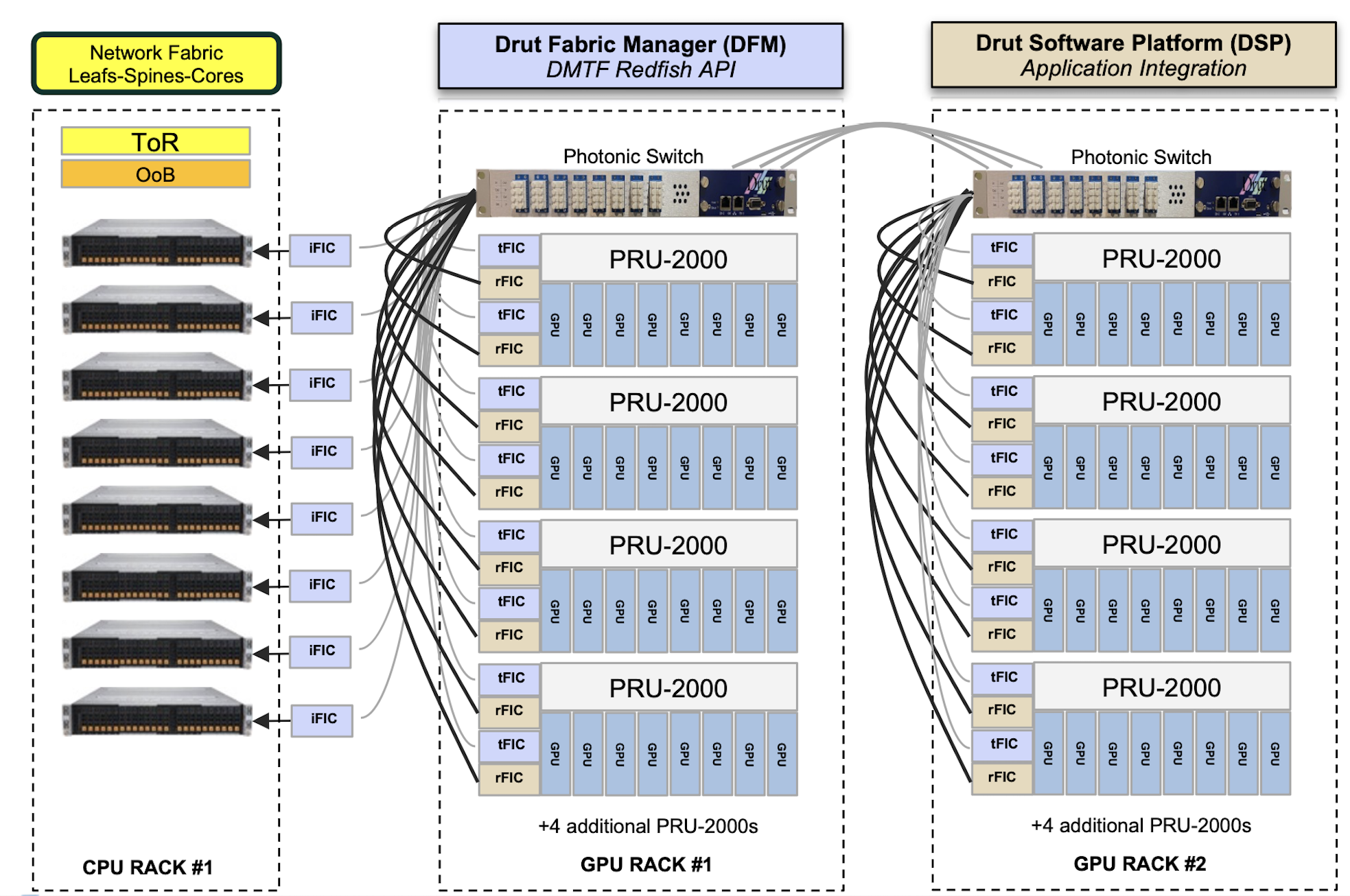
The smallest-sized DynamicXcelerator would use two racks of stacked PRU-2000s (see diagram). Further racks would be added to expand the system.
“The idea is that you can take a very large construct of things and create virtual PODs,” says Koss. “All of a sudden, you have flexible and fluid resources.”
Koss says a system can scale to 16,384 units by combining four clusters, each of 4,096 accelerators. “Each one can be designated as an ‘availability zone’, with users able to call resources in the different zones,” he says.
Customers might use such a configuration to segment users, run different AI models, or for security reasons. “It [a 16,384 unit system] would be huge and most likely something that only a service provider would do or maybe a government agency,” says Koss.
Capital and operation savings
Drut claims the architecture costs 30 per cent less than conventional systems, while operational cost-savings are 40 per cent.
The numbers need explaining, says Koss, given the many factors and choices possible.
The bill of materials of a 16, 32, 64 or 128-GPU design has a 10-30 per cent saving solely from the interconnect.
“The bigger the fabric, the better we scale in price as solutions using tiered leaf-spine-core packet switches involving Ethernet-Infiniband-PCIe are all built around the serdes of the switch chip in the box,” says Koss. “We have a direct-connect fabric with a very high radix, which allows us to build the fabric without stacked tiers like legacy point-to-point networks.”
There are also the power savings, as mentioned. Less power means less heat and hence less cooling.
“We can also change the physical wires in the network,” says Koss, something that can’t be done with leaf-spine-core networks, unless data centre staff change the cabling.
“By grouping resources around a workload, utilisation and performance are much better,” says Koss. “Apps run faster, infrastructure is grouped around workloads, giving users the power to do more with less.”
The system’s evolution is another consideration. A user can upgrade resources because of server disaggregation and the ability to add and remove resources from active machines.
“Imagine that you bought the DynamicXcelerator in 2024. Maybe it was a small sized, four-to-six rack system of GPUs, NVMe, etc,” says Koss. If, in mid-2026, Nvidia releases a new GPU, the user can take several PRU-2000s offline and replace the existing GPUs with the new ones.
“Also if you are an Nvidia shop but want to use the new Mi300 from AMD, no problem,” says Koss. “You can mix GPU vendors with the DynamicXcelerator.” This is different from today’s experience, where what is built is wasteful, expensive, complex, and certainly not climate-conscious, says Koss.
Plans for 2024
Drut has 31 employees, 27 of which are engineers. “We are going on a hiring binge and likely will at least double the company in 2024,” says Koss. “We are hiring in engineering, sales, marketing, and operations.”
Proof-of-concept DynamicXcelerator hardware will be available in the first half of 2024, with general availability then following.

ECOC reflections: final part
Gazettabyte asked several attendees at the recent ECOC show, held in Cannes, to comment on key developments and trends they noted, as well as the issues they will track in the coming year.
Dr. Ioannis Tomkos, Fellow of OSA & Fellow of IET, Athens Information Technology Center (AIT)
With ECOC 2014 celebrating its 40th anniversary, the technical programme committee did its best to mark the occasion. For example, at the anniversary symposium, notable speakers presented the history of optical communications. Actual breakthroughs discussed during the conference sessions were limited, however.
 Ioannis Tomkos
Ioannis Tomkos
It appears that after 2008 to 2012, a period of significant advancements, the industry is now more mainstream, and significant shifts in technologies are limited. It is clear that the original focus four decades ago on novel photonics technologies is long gone. Instead, there is more and more of a focus on high-speed electronics, signal processing algorithms, and networking. These have little to do with photonics even if they greatly improve the overall efficient operation of optical communication systems and networks.
Coherent detection technology is making its way in metro with commercial offerings becoming available, while in academia it is also discussed as a possible solution for future access network applications where long-reach, very-high power budgets and high-bit rates per customer are required. However, this will only happen if someone can come up with cost-effective implementations.
Advanced modulation formats and the associated digital signal processing are now well established for ultra-high capacity spectral-efficient transmission. The focus in now on forward-error-correction codes and their efficient implementations to deliver the required differentiation and competitive advantage of one offering versus another. This explains why so many of the relevant sessions and talks were so well attended.
There were several dedicated sessions covering flexible/ elastic optical networking. It was also mentioned in the plenary session by operator Orange. It looks like a field that started only fives years ago is maturing and people are now convinced about the significant short-term commercial potential of related solutions. Regarding latest research efforts in this field, people have realised that flexible networking using spectral super-channels will offer the most benefit if it becomes possible to access the contents of the super-channels at intermediate network locations/ nodes. To achieve that, besides traditional traffic grooming approaches such as those based on OTN, there were also several ground-breaking presentations proposing all-optical techniques to add/ drop sub-channels out of the super-channel.
Progress made so far on long-haul high-capacity space-division-multiplexed systems, as reported in a tutorial, invited talks and some contributed presentations, is amazing, yet the potential for wide-scale deployment of such technology was discussed by many as being at least a decade away. Certainly, this research generates a lot of interesting know-how but the impact in the industry might come with a long delay, after flexible networking and terabit transmission becomes mainstream.
Much attention was also given at ECOC to the application of optical communications in data centre networks, from data-centre interconnection to chip-to-chip links. There were many dedicated sessions and all were well attended.
Besides short-term work on high-bit-rate transceivers, there is also much effort towards novel silicon photonic integration approaches for realising optical interconnects, space-division-multiplexing approaches that for sure will first find their way in data centres, and even efforts related with the application of optical switching in data centres.
At the networking sessions, the buzz was around software-defined networking (SDN) and network functions virtualisation (NFV) now at the top of the “hype-cycle”. Both technologies have great potential to disrupt the industry structure, but scientific breakthroughs are obviously limited.
As for my interests going forward, I intend to look for more developments in the field of mobile traffic front-haul/ back-haul for the emerging 5G networks, as well as optical networking solutions for data centres since I feel that both markets present significant growth opportunities for the optical communications/ networking industry and the ECOC scientific community.
Dr. Jörg-Peter Elbers, vice president advanced technology, CTO Office, ADVA Optical Networking
The top topics at ECOC 2014 for me were elastic networks covering flexible grid, super-channels and selectable higher-order modulation; transport SDN; 100-Gigabit-plus data centre interconnects; mobile back- and front-hauling; and next-generation access networks.
For elastic networks, an optical layer with a flexible wavelength grid has become the de-facto standard. Investigations on the transceiver side are not just focussed on increasing the spectral efficiency, but also at increasing the symbol rate as a prospect for lowering the number of carriers for 400-Gigabit-plus super-channels and cost while maintaining the reach.
 Jörg-Peter Elbers
Jörg-Peter Elbers
As we approach the Shannon limit, spectral efficiency gains are becoming limited. More papers were focussed on multi-core and/or few-mode fibres as a way to increase fibre capacity.
Transport SDN work is focussing on multi-tenancy network operation and multi-layer/ multi-domain network optimisation as the main use cases. Due to a lack of a standard for north-bound interfaces and a commonly agreed information model, many published papers are relying on vendor-specific implementations and proprietary protocol extensions.
Direct detect technologies for 400 Gigabit data centre interconnects are a hot topic in the IEEE and the industry. Consequently, there were a multitude of presentations, discussions and demonstrations on this topic with non-return-to-zero (NRZ), pulse amplitude modulation (PAM) and discrete multi-tone (DMT) being considered as the main modulation options. 100 Gigabit per wavelength is a desirable target for 400 Gig interconnects, to limit the overall number of parallel wavelengths. The obtainable optical performance on long links, specifically between geographically-dispersed data centres, though, may require staying at 50 Gig wavelengths.
In mobile back- and front-hauling, people increasingly recognise the timing challenges associated with LTE-Advanced networks and are looking for WDM-based networks as solutions. In the next-generation access space, components and solutions around NG-PON2 and its evolution gained most interest. Low-cost tunable lasers are a prerequisite and several companies are working on such solutions with some of them presenting results at the conference.
Questions around the use of SDN and NFV in optical networks beyond transport SDN point to the access and aggregation networks as a primary application area. The capability to programme the forwarding behaviour of the networks, and place and chain software network functions where they best fit, is seen as a way of lowering operational costs, increasing network efficiency and providing service agility and elasticity.
What did I learn at the show/ conference? There is a lot of development in optical components, leading to innovation cycles not always compatible with those of routers and switches. In turn, the cost, density and power consumption of short-reach interconnects is continually improving and these performance metrics are all lower than what can be achieved with line interfaces. This raises the question whether separating the photonic layer equipment from the electronic switching and routing equipment is not a better approach than building integrated multi-layer god-boxes.
There were no notable new trends or surprises at ECOC this year. Most of the presented work continued and elaborated on topics already identified.
As for what we will track closely in the coming year, all of the above developments are of interesting. Inter-data centre connectivity, WDM-PON and open programmable optical core networks are three to mention in particular.
For the first ECOC reflections, click here