
The era of cloud-scale routeing
 Nokia's FP4 p-chip. The multi-chip module shows five packages: the p-chip die surrounded by four memory stacks. Each stack has five memory die. The p-chip and memory stacks are interconnected using an interposer.
Nokia's FP4 p-chip. The multi-chip module shows five packages: the p-chip die surrounded by four memory stacks. Each stack has five memory die. The p-chip and memory stacks are interconnected using an interposer. - Nokia has unveiled the FP4, a 2.4 terabit-per-second network processor that has 6x the throughput of its existing FP3.
- The FP4 is a four-IC chipset implemented using 16nm CMOS FinFET technology. Two of the four devices in the chipset are multi-chip modules.
- The FP4 uses 56 gigabit-per-second serial-deserialiser (serdes) technology from Broadcom, implemented using PAM-4 modulation. It also supports terabit flows.
- Nokia announced IP edge and core router platforms that will use the FP4, the largest configuration being a 0.58 petabit switching capacity router.
Much can happen in an internet minute. In that time, 4.1 million YouTube videos are viewed, compared to 2.8 million views a minute only last year. Meanwhile, new internet uses continue to emerge. Take voice-activated devices, for example. Amazon ships 50 of its Echo devices every minute, almost one a second.
Given all that happens each minute, predicting where the internet will be in a decade’s time is challenging. But that is the task Alcatel-Lucent’s (now Nokia’s) chip designers set themselves in 2011 after the launch of its FP3 network processor chipset that powers its IP-router platforms.
Six years on and its successor - the FP4 - has just been announced. The FP4 is the industry’s first multi-terabit network processor that will be the mainstay of Nokia’s IP router platforms for years to come.
Cloud-scale routing
At the FP4’s launch, Nokia’s CEO, Rajeev Suri, discussed the ‘next chapter’ of the internet that includes smart cities, new higher-definition video formats and the growing number of connected devices.
IP traffic is growing at a compound annual growth rate (CAGR) of 25 percent through to 2022, according to Nokia Bell Labs, while peak data rates are growing at a 39 percent CAGR. Nokia Bell Labs also forecasts that the number of connected devices will grow from 12 billion this year to 100 billion by 2025.
Basil Alwan, Nokia’s president of IP and optical networks, said the internet has entered the era of cloud-scale routeing. When delivering a cloud service, rarely is the request fulfilled by one data centre. Rather, several data centres are involved in fulfilling the tasks. “One transaction to the cloud is multiplied,” said Alwan.
IP traffic is also becoming more dynamic, while the Internet of Things presents a massive security challenge.
Alwan also mentioned how internet content providers have much greater visibility into their traffic whereas the telcos’ view of what flows in their networks is limited. Hence their interest in analytics to understand and manage their networks better.
These are the trends that influenced the design of the FP4.
We put a big emphasis on making sure we had a high degree of telemetry coming out at the chip level
FP4 goals
Telemetry, the sending of measurement data for monitoring purposes, and network security were two key design goals for the FP4.
 Steve Vogelsang“We put a big emphasis on making sure we had a high degree of telemetry coming out at the chip level,” said Steve Vogelsang, CTO for Nokia's IP and optical business.
Steve Vogelsang“We put a big emphasis on making sure we had a high degree of telemetry coming out at the chip level,” said Steve Vogelsang, CTO for Nokia's IP and optical business.
Tasks include counters, collecting statistics and packet copying. “This is to make sure we have the instrumentation coming off these systems that we can use to drive the [network] analytics platform,” said Vogelsang.
Being able to see the applications flowing in the network benefits security. Distributed Denial-of-Service (DDoS) attacks are handled by diverting traffic to a ‘scrubbing centre’ where sophisticated equipment separates legitimate IP packets from attack traffic that needs scrubbing.
The FP4 supports the deeper inspection of packets. “Once we identify a threat, we can scrub that traffic directly in the network,” said Vogelsang. Nokia claims that that the FP4 can deal with over 90 percent of the traffic that would normally go to a scrubbing centre.
Chipset architecture
Nokia’s current FP3 network processor chipset comprises three devices: the p-chip network processor, the q-chip traffic manager and the t-chip fabric interface device.
The p-chip network processor inspects packets and performs table look-ups using fast-access memory to determine where packets should be forwarded. The q-chip is the traffic manager that oversees the packet flows and decides how packets should be dealt with, especially when congestion occurs. The third FP3 chip is the t-chip that interfaces to the router fabric.
The FP4 retains the three chips and adds a fourth: the e-chip - a media access controller (MAC) that parcels data from the router’s client-side pluggable optical modules for the p-chip. However, while the FP4 retains the same nomenclature for the chips as the FP3, the CMOS process, chip architecture and packaging used to implement the FP4 are significantly more advanced.
The FP4 can deal with over 90 percent of the traffic that would normally go to a scrubbing centre
Nokia is not providing much detail regarding FP4 chipset's architecture, unlike the launch of the FP3. “We wanted to focus on the re-architecture we have gone through,” said Vogelsang. But looking at the FP3 design, insight can be gained as to how the FP4 has likely changed.
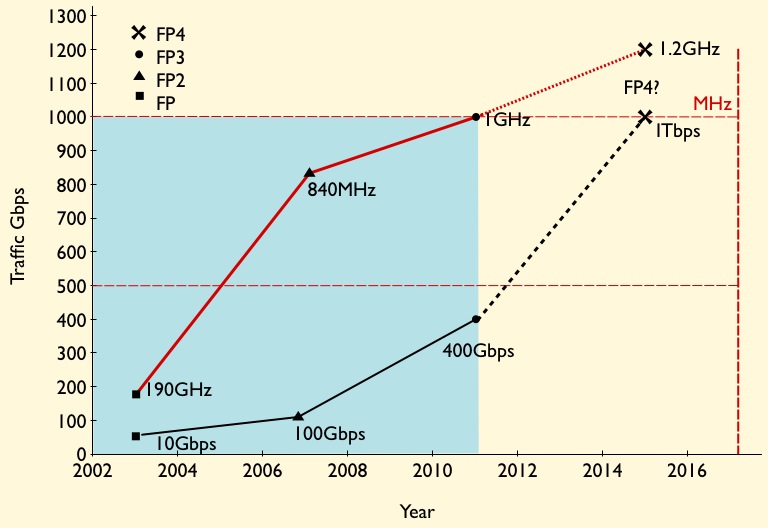
The FP3’s p-chip uses 288 programmable cores. Each programmable core can process two instructions each clock cycle and is clocked at 1GHz.
The 288 cores are arranged as a 32-row-by-9-column array. Each row of cores can be viewed as a packet-processing pipeline. A row pipeline can also be segmented to perform independent tasks. The array’s columns are associated with table look-ups. The resulting FP3 p-chip is a 400-gigabit network processor.
Vogelsang said there is limited scope to increase the clock speed of the FP4 p-chip beyond 1GHz. Accordingly, the bulk of the FP4’s sixfold throughput improvement is the result of a combination of programmable core enhancements, possible a larger core array and, most importantly, system improvements. In particular, the memory architecture is now packaged within the p-chip for fast look-ups, while the chipset’s input-output lanes have been boosted from 10 gigabits-per-second (Gbps) to 50Gbps.
Nokia has sought to reuse as much of the existing microcode to program the cores for the FP4 p-chip but has added new instructions to take advantage of changes in the pipeline.
Software compatibility already exists at the router operating system level. The same SROS router operating system runs on Nokia’s network processors, merchant hardware from the like of Broadcom and on x86 instruction-set microprocessors in servers using virtualisation technology.
Such compatibility is achieved using a hardware abstraction layer that sits between the operating system and the underlying hardware. “The majority of the software we write has no idea what the underlying hardware is,” said Vogelsang.
Nokia has a small team of software engineers focussed on the FP4’s microcode changes but, due to the hardware abstraction layer, such changes are transparent to the main software developers.
The FP3’s traffic manager, the q-chip, comprises four reduced instruction set computer (RISC) cores clocked at 900MHz. This too has been scaled up for the FP4 but Nokia has not given details.
The t-chip interfaces to the switch fabric that sits on a separate card. In previous generations of router products, a mid-plane is used, said Nokia. This has been scrapped with the new router products being announced. Instead, the switch cards are held horizontally in the chassis and the line cards are vertical. “A bunch of metal guides are used to guide the two cards and they directly connect to each other,” said Vogelsang. “The t-chips are what interface to these connectors inside the system.”
The MAC e-chip interfaces to the line card’s pluggable modules and support up to a terabit flow. Indeed, the MAC will support integer multiples of 100 Gigabit Ethernet from 100 gigabit to 1 terabit. Nokia has a pre-standard implementation of FlexMAC that allows it to combine lanes across multiple transceivers into a single interface.
Nokia will have line cards that support 24 or 36 QSFP-DD pluggable modules, with each module able to support 400 Gigabit Ethernet.
The FP4 is also twice as power efficient, consuming 4 gigabit/W.
We wanted to make sure we used a high-volume chip-packaging technology that was being driven by other industries and we found that in the gaming industry
Design choices
One significance difference between the two network processor generations is the CMOS process used. Nokia skipped 28nm and 22nm CMOS nodes to go from 40nm CMOS for the FP3 to 16nm FinFET for the FP4. “We looked at that and we did not see all the technologies we would need coming together to get the step-function in performance that we wanted,” said Vogelsang.
Nokia also designed its own memory for the FP4.
“A challenge we face with each generation of network processor is finding memories and memory suppliers that can offer the performance we need,” said Vogelsang. The memory Nokia designed is described as intelligent: instructions can effectively be implemented during memory access and the memory can be allocated to do different types of look-up and buffering, depending on requirements.
Another key area associated with maximising the performance of the memory is the packaging. Nokia has adopted multi-chip module technology for the p-chip and the q-chip.
“We wanted to make sure we used a high-volume chip-packaging technology that was being driven by other industries and we found that in the gaming industry,” said Vogelsang, pointing out that the graphics processing unit (GPU) has similar requirements to those of a network processor. GPUs are highly memory intensive while manipulating bits on a screen is similar to manipulating headers and packets.
The resulting 2.5D packaged p-chip comprises the packet processor die and stacks of memory. Each memory stack comprises 5 memory die. All sit on an interposer substrate - itself a die that is used for dense interconnect of devices. The resulting FP4 p-chip is thus a 22-die multi-chip module.
“Our memory stacks are connected at the die edges and do not use through-silicon vias,” said Vogelsang. “Hence it is technically a 2.5D package [rather than 3D].”
The q-chip is also implemented as a multi-chip module containing RISC processors and buffering memory, whereas the router fabric t-chip and MAC e-chip are single-die ICs.
The FP4’s more advanced CMOS process also enables significantly faster interfaces. The FP4 uses PAM-4 modulation to implement 56Gbps interfaces. “You really need to run those bit rates much much higher to get the traffic into and out of the chip,” said Vogelsang.
Nokia says it is using embedded serialiser-deserialiser interface technology from Broadcom.
Next-gen routers
Nokia has also detailed the IP edge and core routers that will use the FP4 network processor.
The 7750 Service Router (SR-s) edge router family will support up to 144 terabits in a single shelf. This highest capacity configuration is the 7750 SR-14. It is a 24-rack-unit-plus-the-power-supply high chassis and supports a dozen line cards, each 12Tbps when using 100-gigabit modules, or 24x400GbE when using QSFP-DD modules.
Another new platform is the huge 7950 Extensible Routing System (XRS-XC) IP core router which can be scaled to 576 terabits - over half a petabit - when used in a six-chassis configuration. Combining the six chassis does not make require the use of front-panel client-side interfaces. Instead, dedicated interfaces are used with active optical cables to interlink the chassis.
The first router products will be shipped to customers at the year end with general availability expected from the first quarter of 2018.
Alcatel-Lucent serves up x86-based IP edge routing
Alcatel-Lucent has re-architected its edge IP router functions - its service router operating system (SR OS) and applications - to run on Intel x86 instruction-set servers.
 Shown is the VSR running on one server and distributed across several servers. Source: Alcatel-Lucent.
Shown is the VSR running on one server and distributed across several servers. Source: Alcatel-Lucent.
The company's Virtualized Service Router portfolio aims to reduce the time it takes operators to launch services and is the latest example of the industry trend of moving network functions from specialist equipment onto stackable servers, a development know as network function virtualisation (NFV).
"It is taking IP routing and moving it into the cloud," says Manish Gulyani, vice president product marketing for Alcatel-Lucent's IP routing and transport business.
IP edge routers are located at the edge of the network where services are introduced. By moving IP edge functions and applications on to servers, operators can trial services quickly and in a controlled way. Services can then be scaled according to demand. Operators can also reduce their operating costs by running applications on servers. "They don't have to spare every platform, and they don't need to learn its hardware operational environment," says Gulyani
Alcatel-Lucent has been offering two IP applications running on servers since mid-year. The first is a router reflector control plane application used to deliver internet services and layer-2/ layer-3 virtual private networks (VPNs). Gulyani says the application product has already been sold to two customers and over 20 are trialling it. The second application is a routing simulator used by customers for test and development work.
More applications are now being made available for trial: a provider edge function that delivers layer-2 and layer-3 VPNs, and an application assurance application that performs layer-4 to layer-7 deep-packet inspection. "It provides application level reporting and control," says Gulyani. Operators need to understand application signatures to make decisions based on which applications are going through the IP pipe, he says, and based on a customer's policy, the required treatment for an app.
Additional Virtualized Service Router (VSR) software products planned for 2015 include a broadband network gateway to deliver triple-play residential services, a carrier Wi-Fi solution and an IP security gateway.
Alcatel-Lucent claims a two rack unit high (2RU) server hosting two 10-core Haswell Intel processors achieves 160 Gigabit-per-second (Gbps) full-duplex throughput. The company has worked with Intel to determine how best to use the chipmaker's toolkit to maximise the processing performance on the cores.
"Using 16, 10 Gigabit ports, we can drive the full capacity with a router application," says Gulyani. "But as more and more [router] features are turned on - quality of service and security, for example - the performance goes below 100 Gigabit. We believe the sweet-spot is in the sub-100 Gig range from a single-server perspective."
In comparison, Alcatel-Lucent's own high-end network processor chipset, the FP3, that is used within its router platforms, achieves 400 Gigabit wireline performance even when all the features are turned on.
"With the VSR portfolio and the rest of our hardware platforms, we can offer the right combination to customers to build a performing network with the right economics," says Gulyani.
 Alcatel-Lucent's server router portfolio split into virtual systems and IP platforms. Also shown (in grey) are two platforms that use merchant processors on which runs the company's SR OS router operating system i.e. the company has experience porting its OS onto hardware besides its own FPx devices before it tackled the x86. Source: Alcatel-Lucent.
Alcatel-Lucent's server router portfolio split into virtual systems and IP platforms. Also shown (in grey) are two platforms that use merchant processors on which runs the company's SR OS router operating system i.e. the company has experience porting its OS onto hardware besides its own FPx devices before it tackled the x86. Source: Alcatel-Lucent.
Gazettabyte asked three market research analysts about the significance of the VSR announcement, the applications being offered, the benefits to operators, and what next for IP.
Glen Hunt, principal analyst, transport & routing infrastructure at Current Analysis
Alcatel-Lucent's full routing functionality available on an x86 platform enables operators to continue with their existing infrastructures - the 7750SR in Alcatel-Lucent's case - and expand that infrastructure to support additional services. This is on less expensive platforms which helps support new services that were previously not addressable due to capital expenditure and/ or physical restraints.
The edge of the service provider network is where all the services live. By supporting all services in the cloud, operators can retain a seamless operational model, which includes everything they currently run. The applications being discussed here are network-type functions - Evolved Packet Core (EPC), broadband network gateway (BNG), wireless LAN gateways (WLGWs), for example - not the applications found in the application layer. These functions are critical to delivering a service.
Virtualisation expands the operator’s ability to launch capabilities without deploying dedicated routing/ device platforms, not in itself a bad thing, but with the ability to spin up resources when and where needed. Using servers in a data centre, operators can leverage an on-demand model which can use distributed data centre resources to deliver the capacity and features.
Other vendors have launched, or are about to launch, virtual router functionality, and the top-level stories appear to be quite similar. But Alcatel-Lucent can claim one of the highest capacities per x86 blade, and can scale out to support Nx160Gbps in a seamless fashion; having the ability to scale the control plane to have multiple instances of the Virtualized Service Router (VSR) appear as one large router.
Furthermore, Alcatel-Lucent is shipping its VSR route reflector and the VSR simulator capabilities and is in trials with VSR provider edge and VSR application assurance – noting it has two contracts and 20-plus trials. This shows there is a market interest and possibly pent-up demand for the VSR capabilities.
It will be hard for an x86 platform to achieve the performance levels needed in the IP core to transit high volumes of packet data. Most of the core routers in the market today are pushing 16 Terabit-per-second of throughput across 100 Gigabit Ethernet ports and/ or via direct DWDM interfaces into an optical transport core. This level of capability needs specialised silicon to meet demands.
Performance will remain a key metric moving forward, even though an x86 is less expensive than most dedicated high performance platforms, it still has a cost basis. The efficiency which an application uses resources will be important. In the VSR case, the more work a single blade can do, the better. Also of importance is the ability for multiple applications to work efficiently, otherwise the cost savings are limited to the reduction in hardware costs. If the management of virtual machines is made more efficient, the result is even greater efficiency in terms of end-to-end performance of a service which relies on multiple virtualised network functions.
Ultimately, more and more services will move to the cloud, but it will take a long time before everything, if ever, is fully virtualised. Creating a network that can adapt to changing service needs is a lengthy exercise. But the trend is moving rapidly to the cloud, a combination of physical and virtual resources.
Michael Howard, co-founder and principal analyst, Infonetics Research
There is overwhelming evidence from the global surveys we’ve done with operators that they plan to move functions off the physical IP edge routers and use software versions instead.
These routers have two main functions: to handle and deliver services, and to move packets. I’ve been prodding router vendors for the last two years to tell us how they plan to package their routing software for the NFV market. Finally, we hear the beginnings, and we’ll see lots more software routing options.
The routing options can be called software routers or vRouters. The services functions will be virtualised network functions (VNFs), like firewalls, intrusion detection systems and intrusion prevention systems, deep-packet inspection, and caching/ content delivery networks that will be delivered without routing code. This is important for operators to see what routing functions they can buy and run in NFV environments on servers, so they can plan how to architect their new software-defined networking and NFV world.
It is important for router vendors to play in this world and not let newcomers or competitors take the business. Of course, there is a big advantage to buy their vRouter software — route reflection for example — from the same router vendor they are already using, since it obviously works with the router code running on physical routers, and the same software management tools can be used.
Juniper has just made its first announcement. We believe all router vendors are doing the same; we’ve been expecting announcements from all the router vendors, and finally they are beginning.
It will be interesting to see how the routing code is packaged into targeted use cases - we are just seeing the initial use cases now from Juniper and Alcatel-Lucent - like the route reflection control plane function, IP/ MPLS VPNs and others.
Despite the packet-processing performance achieved by Alcatel-Lucent using x86 processors, it should be noted that some functions like the control plane route reflection example only need compute power, not packet processing or packet-moving power.
There already is, and there will always be, a need for high performance for certain places in the network or for serving certain customers. And then there are places and customers where traffic can be handled with less performance.
As for what next for IP, the next 10 to 15 years will be spent moving to SDN- and NFV-architected networks, just as service providers have spent over 10 years moving from time-division multiplexing-based networks to packet-based ones, a transition yet to be finished.
Ray Mota, chief strategist and founder, ACG Research
Carriers have infrastructure that is complex and inflexible, which means they have to be risk-averse. They need to start transitioning their architecture so that they just program the service, not re-architect the network each time they have a new service. Having edge applications becoming more nimble and flexible is a start in the right direction. Alcatel-Lucent has decided to create a NFV edge product with a carrier-grade operating system.
It appears, based on what the company has stated, that it achieves faster performance than competitors' announcements.
Alcatel-Lucent is addressing a few areas: this is great for testing and proof of concepts, and an area of the market that doesn't need high capacity for routing, but it also introduces the potential to expand new markets in the webscaler space (that includes the large internet content providers and the leading hosting/ co-location companies).
You will see more and more IP domain products overlap into the IT domain; the organisationals and operations are lagging behind the technology but once service providers figure it out, only then will they have a more agile network.
A Terabit network processor by 2015?
Given that 100 Gigabit merchant silicon network processors will appear this year only, it sounds premature to discuss Terabit devices. But Alcatel-Lucent's latest core router family uses the 400 Gigabit FP3 packet-processing chipset, and one Terabit is the next obvious development.
 Source: Gazettabyte
Source: Gazettabyte
Core routers achieved Terabit scale awhile back. Alcatel-Lucent's recently announced IP core router family includes the high-end 32 Terabit 7950 XRS-40, expected in the first half of 2013. The platform has 40 slots and will support up to 160, 100 Gigabit Ethernet interfaces.
Its FP3 400 Gigabit network processor chipset, announced in 2011, is already used in Alcatel-Lucent's edge routers but the 7950 is its first router platform family to exploit fully the chipset's capability.
The 7950 family comes with a selection of 10, 40 and 100 Gigabit Ethernet interfaces. Alcatel-Lucent has designed the router hardware such that the card-level control functions are separate from the Ethernet interfaces and FP3 chipset that both sit on the line card. The re-design is to preserve the service provider's investment. Carrier modules can be upgraded independently of the media line cards, the bulk of the line card investment.
The 7950 XRS-20 platform, in trials now, has 20 slots which take the interface modules - dubbed XMAs (media adapters) - that house the various Ethernet interface options and the FP3 chipset. What Alcatel-Lucent calls the card-level control complex is the carrier module (XCM), of which there are up to are 10 in the system. The XCM, which includes control processing, interfaces to the router's system fabric and holds up to two XMAs.
There are two XCM types used with the 7950 family router members. The 800 Gigabit-per-second (Gbps) XCM supports a pair of 400Gbps XMAs or 200Gbps XMAs, while the 400Gbps XCM supports a single 400Gbps XMA or a pair of 200Gbps XMAs.
The slots that host the XCMs can scale to 2 Terabits, suggesting that the platforms are already designed with the next packet processor architecture in mind.
FP3 chipset
The FP3 chipset, like the previous generation 100Gbps FP2, comprises three devices: the P-chip network processor, a Q-chip traffic manager and the T-chip that interfaces to the router fabric.
The P-chip inspects packets and performs the look ups that determine where the packets should be forwarded. The P-chip determines a packet's class and the quality of service it requires and tells the Q-chip traffic manager in which queue the packet is to be placed. The Q-chip handles the packet flows and makes decisions as to how packets should be dealt with, especially when congestion occurs.
The basic metrics of the 100Gbps FP2 P-chip is that it is clocked at 840GHz and has 112 micro-coded programmable cores, arranged as 16 rows by 7 columns. To scale to 400Gbps, the FP3 P-chip is clocked at 1GHz (x1.2) and has 288 cores arranged as a 32x9 matrix (x2.6). The cores in the FP3 have also been re-architected such that two instructions can be executed per clock cycle. However this achieves a 30-35% performance enhancement rather than 2x since there are data dependencies and it is not always possible to execute instructions in parallel. Collectively the FP3 enhancements provide the needed 4x improvement to achieve 400Gbps packet processing performance.
The FP3's traffic manager Q-chip retains the FP2's four RISC cores but the instruction set has been enhanced and the cores are now clocked at 900GHz.
Terabit packet processing
Alcatel-Lucent has kept the same line card configuration of using two P-chips with each Q-chip. The second P-chip is viewed as an inexpensive way to add spare processing in case operators need to support more complex service mixes in future. However, it is rare that in the example of the FP2-based line card, the capability of the second P-chip has been used, says Alcatel-Lucent.
Having the second P-chip certainly boosts the overall packet processing on the line card but at some point Alcatel-Lucent will develop the FP4 and the next obvious speed hike is 1 Terabit.
Moving to a 28nm or an even more advanced CMOS process will enable the clock speed of the P-chip to be increased but probably not by much. A 1.2GHz clock would still require a further more-than-doubling of the cores, assuming Alcatel-Lucent doesn't also boost processing performance elswhere to achieve the overall 2.5x speed-up to a 1 Terabit FP4.
However, there are two obvious hurdles to be overcome to achieve a Terabit network processor: electrical interface speeds and memory.
Alcatel-Lucent settled on 10Gbps SERDES to carry traffic between the chips and for the interfaces on the T-chip, believing the technology the most viable and sufficiently mature when the design was undertaken. A Terabit FP4 will likely adopt 25Gbps interfaces to provide the required 2.5x I/O boost.
Another even more significant challenge is the memory speed improvement needed for the look up tables and for packet buffering. Alcatel-Lucent worked with the leading memory vendors when designing the FP3 and will do the same for its next-generation design.
Alcatel-Lucent, not surprisingly, will not comment on devices it has yet to announce. But the company did say that none of the identified design challenges for the next chipset are insurmountable.
Further reading:
Network processors to support multiple 100 Gigabit flows
A more detailed look at the FP3 in New Electronics, click here
Network processors to support multiple 100 Gigabit flows

“We don’t know of any device, announced at least, that comes close to this”
Amir Eyal, EZchip
The NP-5 is noteworthy in integrating within a single chip a full-duplex 100 Gigabit-per-second (Gbps) packet processor and traffic manager. Such integration is important as line cards move from 100Gbps to 400Gbps densities, says Bob Wheeler, senior analyst at The Linley Group.
Target markets
The NP-5 is aimed at router and transport switches platforms that make up the carrier Ethernet switch router (CESR) market. Platforms include packet optical transport switches and edge routers. Infonetics Research forecasts that the total Carrier Ethernet market will grow to US $37bn in 2015 from $26bn in 2010, while the CESR market will double to $20bn by 2015.
EZchip says its main competition is in-house ASIC design teams of the large system vendors. Alcatel-Lucent for example has just announced its FP3 400Gbps network processor. The FP3 is implemented as a three-device chipset made up of a packet processor, traffic manager and a fabric-access chip.
EZchip also believes the device has a role within the data centre. New protocol developments require packet processing that today can only be achieved using a packet processor, it says.
An example is OpenFlow which EZchip supports using its current NP-4 processor. OpenFlow is an academic initiative that allows networking protocols to be explored on existing switch hardware but it is of growing interest to data centre operators. The initiative creates an industry-standard application programming interface (API) to the underlying switch platforms.
The latest OpenFlow version (V1.1) can only be supported using a network processor, says Amir Eyal, EZChip’s vice president of business development. However the data centre is seen as a secondary market for the NP-5. The downside is that the NP-5 and similar network processors targeted at telecoms cost more than switch ASICs from vendors. Only when the functionality of an NPU is needed will vendors pay more.
NP-5 architecture
The chip's main functional blocks are a programmable packet processor and a traffic manager. Also integrated on-chip is an integrated Ethernet switch fabric adaptor, media access controllers (MACs) that support 1, 10, 40 and 100 Gigabit Ethernet (GbE), and a memory controller designed for use with DDR3 external memory to reduce overall system cost. The current NP-4 supports DDR3 and RLDRAM - considerably more expensive than DDR3.
The packet processing is performed using task-optimised processor engines (TOPs). Four styles of TOP engines are used: Two perform classification - parsing, which extracts packet headers and data fields, and searching using look-up tables; and one TOP each for packet modification and packet forwarding.
Each TOP has a 64-bit architecture and processes a single thread. A scheduler allocates a packet to the next available free TOP. EZchip does not disclose the number of TOPs it uses but says that the NP-5 will have almost twice the number used for the NP-4, with the most numerous being the search TOP due to the numerous look-ups needed.
An on-chip ternary content addressable memory (TCAM), meanwhile, supports more sophisticated look-ups and operates in parallel to the simpler TOPs-based searches.
The traffic manager provides bandwidth and guarantees a certain service level performance to particular packet flows. The traffic manager makes decisions when packet congestion occurs based on a given traffic’s priority and its associated rules.
The NP-5 first stores packets in its internal buffer memory before dropping lower-priority packets once memory is full. It is rare that all the input ports are full simultaneously. By taking advantage of the integrated MACs on-chip, up to 24, 10 Gigabit ports can be used to input data. The NP-5 can thus support peak flows of 240Gbps, or a 2.4-to-1 oversubscription rate, equating to a system line card supporting 24-ports at 10Gbps traffic at the same cost as a 10 port-10Gbps design, says EZchip.
The NP-5 will also have four integrated engines. Each engine will support either 12x10GbE, 3x40GbE, 1x100GbE or one Interlaken interface. Two of the four interface engines support 48, 1GbE ports using the QSGMII interface while the remaining two support 12x1GbE ports using the SFI interface.
The QSGMII interface allows a quadrupling of the links by interleaving four ports per link. However an additional external device is needed to break the four interleaved ports into four separate ones. The SFI interface allows a direct connection to a 1GbE optical module.
Also included on the device is an Ethernet fabric adapter that supports 24, 10Gbps (10GBASE-KR) short-reach backplane interfaces.
Device metrics
The 200Gbps NP-5 will be able to process up to 300 million 64byte packets per second. The chip’s power consumption is estimated at 50W. Implemented using a 28nm CMOS process, the device will require 2,401 pins.
What next?
The NP-5 is scheduled to sample year-end 2012. Assuming it takes 18 months to design systems, it will be mid-2014 when NP-5 line cards supporting multiple 100Gbps interfaces are first deployed. EZchip says four or even eight NP-5s could be integrated on a line card, achieving a total packet throughput of 1.6Tbit/s per board.
Meanwhile EZchip’s NP-4 is currently sampling and will ramp in the next few months. Most of the large edge router and switch vendors are designing the NP-4 into their systems, says EZchip.
Further reading:
For more NP-5 detail see the New Electronics article, click here.