
How CPO enables disaggregated computing

A significant shift in cloud computing architecture is emerging as start-up Drut Technologies introduces its scalable computing platform. The platform is attracting attention from major banks, telecom providers, and hyperscalers.
At the heart of this innovation is a disaggregated computing system that can scale to 16,384 accelerator chips, enabled by pioneering use of co-packaged optics (CPO) technology.
“We have all the design work done on the product, and we are taking orders,” says Bill Koss, CEO of Drut (pictured).
System architecture
The start-up’s latest building block as part of its disaggregated computing portfolio is the Photonic Resource Unit 2500 (PRU 2500) chassis that hosts up to eight double-width accelerator chips. The chassis also features Drut’s interface cards that use co-package optics to link servers to the chassis, link between the chassis directly or, for larger systems, through optical or electrical switches.
The PRU 2500 chassis supports various vendors’ accelerator chips: graphics processing units (GPUs), chips that combine general processing (CPU) and machine learning engines, and field programmable gate arrays (FPGAs).
Drut has been using third-party designs for its first-generation disaggregated server products. More recently the start-up decided to develop its own PRU 2500 chassis as it wanted to have greater design flexibility and be able to support planned enhancements.
Koss says Drut designed its disaggregated computing architecture to be flexible. By adding photonic switching, the topologies linking the chassis, and the accelerator chips they hold, can be combined dynamically to accommodate changing computing workloads.
Up to 64 racks – each rack hosting eight PRU 2500 chassis or 64 accelerator chips – can be configured as a 4096-accelerator chip disaggregated compute cluster. Four such clusters can be networked together to achieve the full 16,384 chip cluster. Drut refers to its compute cluster concept as the DynamicXcelerator virtual POD architecture.

The architecture can also be interfaced to an enterprise’s existing IT resources such as Infiniband or Ethernet switches. “This set-up has scaling limitations; it has certain performance characteristics that are different, but we can integrate existing networks to some degree into our infrastructure,” says Koss.
PRU-2500
The PRU 2500 chassis is designed to support the PCI Express 5.0 protocol. The chassis supports up to 12 PCIe 5.0 slots, including eight double-width slots to host PCIe 5.0-based accelerators. The chassis comes with two or four tFIC 2500 interface cards, discussed in the next section.
The remaining four of the 12 PCIe slots can be used for single-width PCIe 5.0 cards or Drut’s rFIC-2500 remote direct memory access (RDMA) network cards for optical-based accelerator-to-accelerator data transfers.
Also included in the PRU 2500 chassis are two large Broadcom PEX89144 PCIe 5.0 switch chips. Each PEX chip can switch 144 PCIe 5.0 lanes for a total bandwidth of 9.2 terabits-per-second (Tbps).

Co-packaged optics and photonic switching
The start-up is a trailblazer in adopting co-packaged optics. Due to the input-output requirements of its interface cards, Drut chose to use co-packaged optics since traditional pluggable modules are too bulky and cannot meet the bandwidth density requirements of the cards.
There are two types of interface cards. The iFIC 2500 is added to the host while the tFIC 2500 is part of the PRU 2500 chassis, as mentioned. Both cards are a half-length PCIe Gen 5.0 card and each has two variants: one with two 800-gigabit optical engines to support 1.6Tbps of I/O and one with four engines for 3.2Tbps I/O. It should be noted that these cards are used to carry PCIe 5.0 lanes, each lane operating at 32 gigabits-per-second (Gbps) using non-return-to-zero (NRZ) signalling.
The cards interface to the host server and connect to their counterparts in other PRU 2500 chassis. This way, the server can interface with as accelerator resources across multiple PRU 2500s.
Drut uses co-packaged optics engines due to their compact size and superior bandwidth density compared to traditional pluggable optical modules. “Co-package optics give us a high amount of density endpoints in a tiny physical form factor,” says Koss.
The co-packaged optics engines include integrated lasers rather than using external laser sources. Drut has already sourced the engines from one supplier and is also waiting on sources from two others.
“The engines are straight pipes – 800 gigabits to 800 gigabits,” says Koss. “We can drop eight lasers anywhere, like endpoints on different resource modules.”

Drut also uses a third-party’s single-mode-fibre photonic switch. The switch can be configured from 32×32 up to 384×384 ports. Drut will talk more about the photonic switching aspect of its design later this year.
The final component that makes the whole system work is Drut’s management software, which oversees the system’s traffic requirements and the photonic switching. The complete system architecture is shown below.

More development
Koss says being an early adopter of co-package optics has proven to be a challenge.
The vendors are still at the stage of ramping up volume manufacturing and resolving quality and yield issues. “It’s hard, right?” he says,
Koss says WDM-based co-packaged optics are 18 to 24 months away. Further out, he still foresees photonic switching of individual wavelengths: “Ultimately, we will want to turn those into WDM links with lots of wavelengths and a massive increase in bandwidth in the fibre plant.”
Meanwhile, Drut is already looking at its next PRU chassis design to support the PCIe 6.0 standard, and that will also include custom features driven by customer needs.
The chassis could also feature heat extraction technologies such as water cooling or immersion cooling, says Koss. Drut could also offer a PRU filled with CPUs or a PRU stuffed with memory to offer a disaggregated memory pool.
“A huge design philosophy for us is the idea that you should be able to have pools of GPUs, pools of CPUs, and pools of other things such as memory,” says Koss. “Then you compose a node, selecting from the best hardware resources for you.”
This is still some way off, says Koss, but not too far out: “Give us a couple of years, and we’ll be there.”

OFC 2024 industry reflections
Gazettabyte is asking industry figures for their thoughts after attending the recent OFC show in San Diego. In particular, what developments and trends they noted, what they learned and what, if anything, surprised them. Here are the first responses from Huawei, Drut Technologies and Aloe Semiconductor.
Maxim Kuschnerov, Director R&D, Optical & Quantum Communication Laboratory at Huawei.
Some ten years ago datacom took the helm of the optical transceiver market from legacy telecom operators to command a much larger volume of short-reach optics and extend its vision into dense wavelength division multiplexing (DWDM).
At OFC, the industry witnessed another passing-of-the-torch moment as Nvidia took over the dominant position in the optics market where AI compute is driving optical communication. The old guard of Google is now following while others are closely watching.
Nvidia’s Blackwell NVL72 architecture was the talk of the conference and its exclusive reliance on passive copper cables for intra-rack GPU-to-GPU interconnects dampened the hopes of Wall Street optics investors at the show.
Since the copper backplane is using 224-gigabit serdes, last year’s hot topics of 100 gigabit-based linear pluggable optics or dense optical interconnects based on 16×100 gigabits suddenly felt dated and disconnected from where the market already is. It is also in no shape to respond to where the compute market is rapidly going next: 400-gigabit-per-lane signalling.
Here, the main question is which type of connectivity for the GPU scale-up in the intra-rack domain would be employed and whether this might be the crossover point to go to optical cables? But as often is the case in the optical business, one should never fully bet against CMOS and copper.
The long-term evolution of AI compute will impact optical access and this was also a theme of some of the OFC panels.
6G is envisioned to be the first wireless network supporting devices primarily, not humans, and it’s fair to assume that a majority of those distributed devices will be AI-enabled. Since it will be uneconomical to send the raw training or inference bandwidth to the network core, the long term evolution of AI compute might see a regionalisation and a distribution towards the network edge, where there would be a strong interdependence of 6G, fronthaul/ backhaul & metro edge networks, and the AI edge compute cloud.
While a majority of coherent PON presentations failed to quantify the market driver for introducing the more expensive technology in future access networks, AI-data powered 6G fronthauling over installed optical distribution networks will drive the bandwidth need for this technology, while residential fibre-to-the-home – “PON for humans” – can still evolve to 200 gigabit using low cost intensity modulation direct detection (IMDD) optics.
The times are over where the talk of cheaper datacom ZR optics dominated the show and commanded attendance at the Market Watch sessions. Don’t misunderstand, the step to 1600ZR is technologically important and market-relevant, but since coherent doesn’t have “AI” written all over it, the ZR evolution was more a footnote of the exhibition. However, in a necessary move away from electro-absorption-modulated lasers (EMLs), 400-gigabit-per-lane optics for intensity modulation direct detection will share similar Mach-Zehnder modulator structures as coherent optics.
Thus, start-ups crowding the thin-film lithium niobate modulator market in the US, Europe and China are going for both: the coherent and the intensity modulation direct detection dollar.
Meanwhile, the established silicon photonics ecosystem will have to wrap its head around what their value-add in this domain will be since silicon photonics would be just the carrier of other materials enabling lasers, modulators and photodetectors.
Bill Goss, CEO of Drut Technologies
The last time I attended OFC, the conference was in Los Angeles at the Staples Center.
One thing I found super interesting at this year’s event was the number of companies working on optically-connected memory solutions. But the biggest noteworthy item to us was a number of presentations on using optical circuit switching (OCS) for AI/ML workloads.
Nvidia and some universities presented projects using OCS in the data centre and Coherent actually showed a new 300×300 switch in their booth. There also seemed to be a feeling that the world has been waiting on co-packaged optics for years.
One thing evident in talking with optical companies that typically focus on service provider networks, is that they all want to get inside the data centre. That is where the big market explosion is going to be in the next decade and companies are thinking about how to gain share in the data centre with optical solutions.
You could almost feel the gloom around service provider capital expenditure and the companies that normally play in this market are looking at all the spending going on inside the data centre and trying to figure out how to access this spend.
Drut Technologies did not exhibit at OFC. Instead, we used the show to listen to presentations and talk to suppliers and customers. Surprises were the amount of pluggable optics available.
Walking through the show floor, it seemed like a sea of pluggables and I had multiple meetings with companies looking to put coherent optics inside the data centre. Visually too, the amount of pluggables was noticeable.
I was also surprised at the absence of certain companies. It seems companies opted for a private meeting room rather than a booth. I do not know what that means, if anything, but if the trend continues, the show floor is going to be half-filled with private meeting spaces. It will be like walking through a maze of white walls.
I was not surprised with all the AI excitement, but the show did not seem to have a lot of energy.
Chris Doerr, CEO of Aloe Semiconductor
The first most noteworthy trend of this OFC was the acceleration of pluggable module data rates. There were demonstrations of 1.6-terabit pluggables by almost every module vendor. This was supposed to be the year of 800 gigabit not 1.6 terabit.
Digging into it more, most of the demonstrated 1.6 terabit modules were not fully operational – the receiver was not there, all the channels not running simultaneously, etc. – but some EML-based modules were complete.
The second most noteworthy trend was supply constraint and the subsequent driving of new technology. For example, it was said that Nvidia bought up all the VCSEL supply capacity. This is driving up VCSEL prices and seems to be allowing a surge of silicon photonics in the lower speed markets that were previously thought to be done and closed, such as active optical cables. There was an increasing polarity in opinion on linear pluggable optics, with opposing opinions by well-known technologists.
It seems that Nvidia is already deploying 100 gigabit per lane linear pluggable optics, and Arista will be deploying it soon. For 200 gigabit per lane, it seems the trend is to favour half-linear pluggable optics, or linear receive optics (LRO), in which the transmit is still retimed.
Large-scale co-packaged optics (not to be confused with small-scale CPO of a coherent ASIC and coherent optics) was exhibited by more vendors this year. It seems very little, if any, is deployed. Large-scale CPO is inevitable, but it on a significantly slower time scale than previously thought.
For 200 gigabit per lane, there were many demonstrations using EMLs and quite a few using silicon photonics. Most of the silicon photonics demonstrations seemed to require driver ICs to overcome the reduced modulation efficiency, sacrificed to achieve the higher bandwidth. Consequently, most companies appear to be throwing in the towel on silicon photonics for 200 gigabaud (GBd) applications, instead moving toward indium phosphide and thin-film LiNbO3 (TFLN). This is surprising.
This author strongly believes in the trend usually followed by silicon electronics in that innovation will allow silicon photonics to achieve 200GBd. It is unreasonable to expect indium phosphide or TFLN to meet the volumes, density, and pricepoints required for 3.2-terabit modules and beyond.
There is no widely accepted solution for 400-gigabit-per-lane intensity modulation direct detection. Proposals include two wavelengths x 200 gigabit, going for 200GBd early, and dual-polarization intensity modulation direct detection.
There was significant discussion about optoelectronic interposers, with start-ups LightMatter and Celestial AI receiving large funding in this area. However, the end customers do not seem to have a need for this technology, so it is unclear where it is headed.
OFC was highly noteworthy this year, driven by the surging demand for high-performance computing interconnects. Probably the biggest takeaway is the amount of uncertainty and polarised views, including linear pluggable optics, silicon-photonic’s future, and optoelectronic interposers.

Drut tackles disaggregation at a data centre scale
- Drut’s DynamicXcelerator supports up to 4,096 accelerators using optical switching and co-packaged optics. Four such clusters enable the scaling to reach 16,384 accelerators.
- The system costs less and is cheaper to run, has lower latency, and better uses the processors and memory.
- The system is an open design supporting CPUs and GPUs from different vendors.
- DynamicXcelerator will ship in the second half of 2024.

Drut Technologies has detailed a system that links up to 4,096 accelerator chips. And further scaling, to 16,384 GPUs, is possible by combining four such systems in ‘availability zones’.
The US start-up previously detailed how its design can disaggregate servers, matching the processors, accelerators, and memory to the computing task at hand. Unveiled last year, the product comprises management software, an optical switch, and an interface card that implements the PCI Express (PCIe) protocol over optics.
The product disaggregates the servers but leaves intact the tiered Ethernet switches used for networking servers across a data centre.
Now the system start-up is expanding its portfolio with a product that replaces the Ethernet switches with optical ones. “You can compose [compute] nodes and drive them using our software,” says Bill Koss, CEO of Drut.
Only Google has demonstrated the know-how to make such a large-scale flexible computing architecture using optical switching.
Company background
Drut was founded in 2018 and has raised several funding rounds since 2021.
Jitender Miglani, founder and president of Drut, previously worked at MEMS-based optical switch maker, Calient Technologies.
Drut’s goal was to build on its optical switching expertise and add the components needed to make a flexible, disaggregated computing architecture. “The aim was building the ecosystem around optical switches,” says Miglani.
The company spent its first two years porting the PCIe protocol onto an FPGA for a prototype interface card. Drut showcased its prototype product alongside a third-party optical switch as part of a SuperMicro server rack at the Supercomputing show in late 2022.
Drut has spent 2023 developing its next-generation architecture to support clusters of up to 4,096 endpoints. These can be accelerators like graphics processing units (GPUs), FPGAs, data processing units (DPUs), or storage using the NVM Express (nonvolatile memory express).
The architecture, dubbed DynamicXcelerator, supports PCIe over optics to link processors (CPUs and GPUs) and RDMA (Remote Direct Memory Access) over optics for data communications between the GPUs and between the CPUs.
The result is the DynamicXcelerator system, a large-scale reconfigurable computing for intensive AI model training and high-performance computing workloads.
DynamicXcelerator
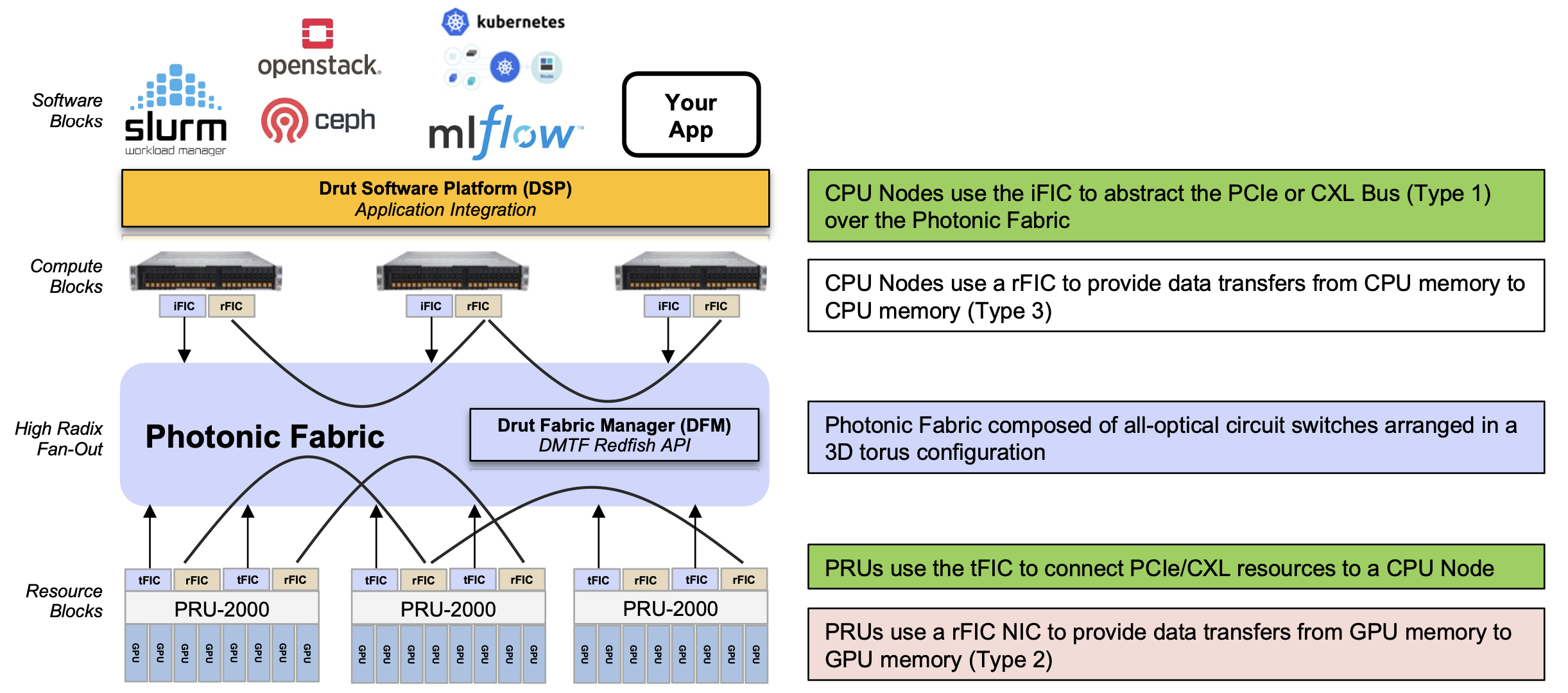
The core of the DynamicXcelerator architecture is a photonic fabric based on optical switches. This explains why Drut uses PCIe and RDMA protocols over optics.
Optical switches brings size and flexibility and by relaying optical signals, their ports are data-rate independent.
Another benefit of optical switching is power savings. Drut says an optical switch consumes 150W whereas an equivalent-sized packet switch consumes 1,700W. On average, an Infiniband or Ethernet packet switch draws 750W when used with passive cables. Using active cables, the switch’s maximum power rises to 1,700W. “[In contrast], a 32-64-128-144 port all-optical switch draws 65-150W,” says Koss.
Drut also uses two hardware platforms. One is the PCIe Resource Unit, dubbed the PRU-2000, which hosts eight accelerator chips such as GPUs. Unlike Nvidia’s DGX platform, which uses Nvidia GPUs such as the Hopper, or Google, which uses its TPU5 tensor processor unit (TPU), Drut’s PRU-2000 is an open architecture and can use GPUs from Nvidia, AMD, Intel, and others. The second class of platform is the compute node or server, which hosts the CPUs.
DynamicXcelerator’s third principal component are the FIC 2500 interface cards.
The iFIC 2500 card is similar to Drut’s current product’s iFIC 1000, which features an FPGA and four QSFP28s. However, the iFIC 2500 supports the PCIe 5.0 generation bus and the Compute Express Link (CXL) protocols. The two other FIC cards are the tFIC 2500 and rFIC 2500.
“The iFIC and tFIC are the same card, but different software images,” says Koss. “The iFIC fits into a compute node or server while the tFIC fits into our Photonic Resource Unit (PRU) unit, which holds GPUs, FPGAs, DPUs, NVMe, and the like.”
The rFIC provides RDMA over photonics for GPU-to-GPU memory sharing. The rFIC card for CPU-to-CPU memory transfers is due later in 2024.
Miglani explains that PCIe is used to connect the GPUs and CPUs, but for GPU-to-GPU communication, RDMA is used since even PCIe over photonics has limitations.
Certain applications will use hundreds and even thousands of accelerators, so a PCIe lane count is one limitation, distance is another; a 5ns delay is added for each metre of fibre. “There is a window where the PCIe specification starts to fall off,” says Miglani.
The final component is DynamicXcelerator’s software. There are two software systems: the Drut fabric manager (DFM), which controls the system’s hardware configuration and traffic flows, and the Drut software platform (DSP) that interfaces applications onto the architecture.
Co-packaged optics
Drut knew it would need to upgrade the iFIC 1000 card. DynamicXcelerator uses PCIe 5.0, each lane being 32 gigabit-per-second (Gbps). Since 16 lanes are used, that equates to 512 gigabits of bandwidth.
“That’s a lot of bandwidth, way more that you can crank out with four 100-gigabit pluggables,” says Koss, who revealed co-packaged optics will replace pluggable modules for the iFIC 2500 and tFIC 2500 cards.
The card for the iFIC and tFIC will use two co-packaged optical engines, each 8×100 gigabits. The total bandwidth of 1.6 terabits – 16×100-gigabit channels – is a fourfold increase over the iFIC 1000.
System workings
The system’s networking can be viewed as a combination of circuit switching and packet switching.
The photonic fabric, implemented as a 3D torus (see diagram), supports circuit switching. Using a 3D torus, three hops at most are needed to link any two of the system’s endpoints.
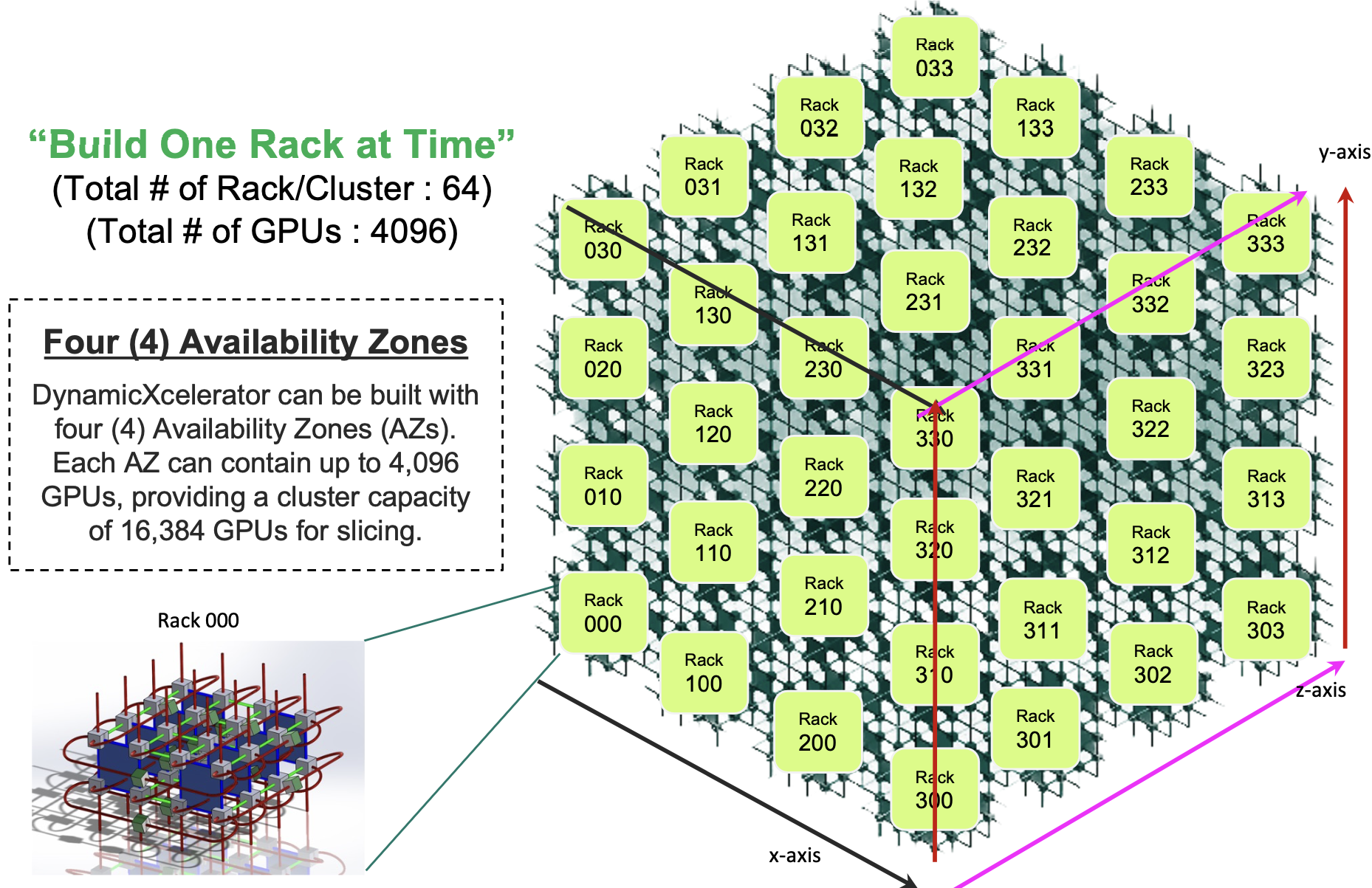
One characteristic of machine learning training, such as large language models, is that traffic patterns are predictable. This suits an architecture that can set the resources and the connectivity for a task’s duration.
Packet switching is not performed using Infiniband. Nor is a traditional spine-leaf Ethernet switch architecture used. The DynamicXcelerator does uses Ethernet but in the form of a small, distributed switching layer supported in each interface card’s FPGA.
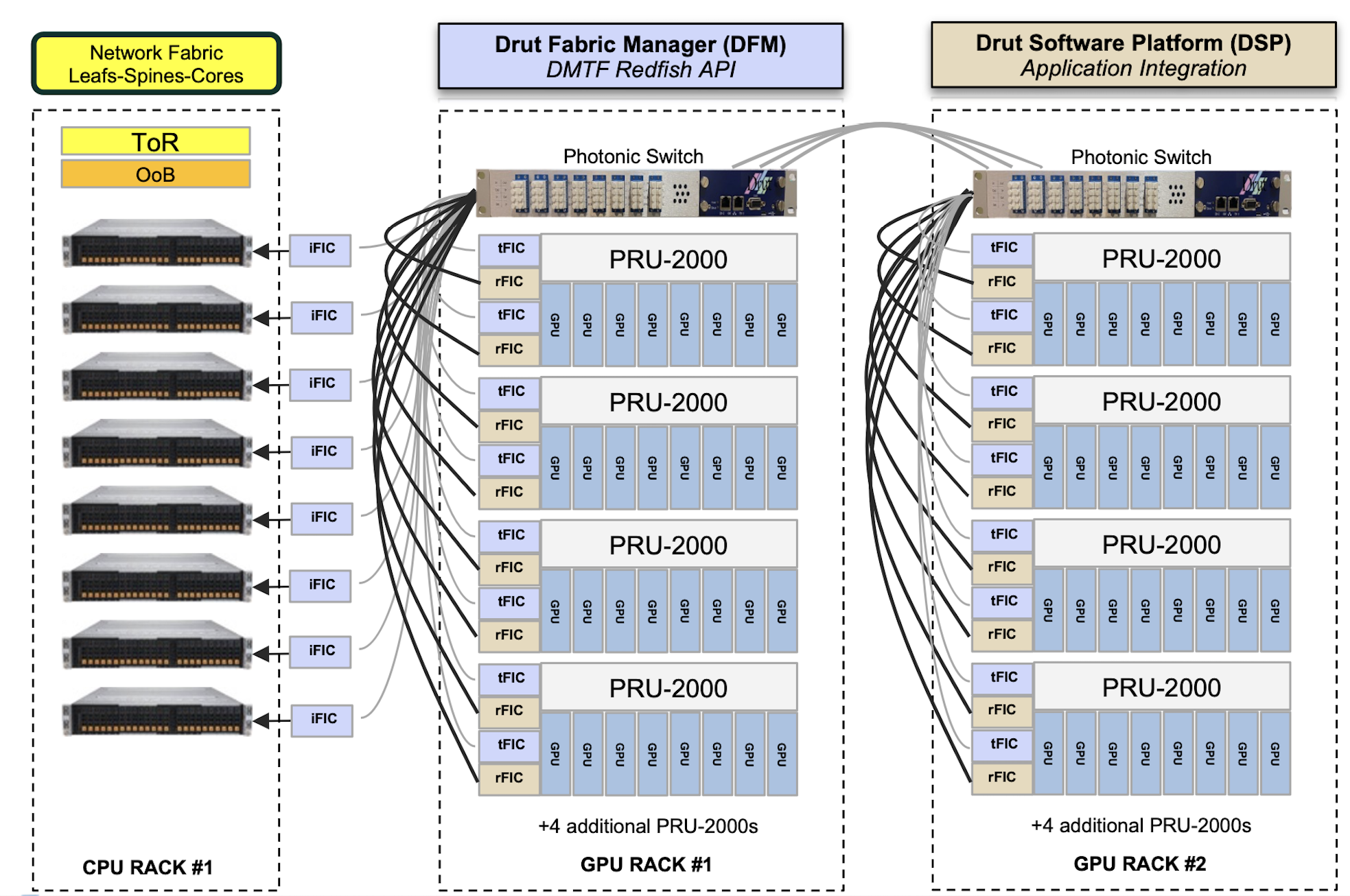
The smallest-sized DynamicXcelerator would use two racks of stacked PRU-2000s (see diagram). Further racks would be added to expand the system.
“The idea is that you can take a very large construct of things and create virtual PODs,” says Koss. “All of a sudden, you have flexible and fluid resources.”
Koss says a system can scale to 16,384 units by combining four clusters, each of 4,096 accelerators. “Each one can be designated as an ‘availability zone’, with users able to call resources in the different zones,” he says.
Customers might use such a configuration to segment users, run different AI models, or for security reasons. “It [a 16,384 unit system] would be huge and most likely something that only a service provider would do or maybe a government agency,” says Koss.
Capital and operation savings
Drut claims the architecture costs 30 per cent less than conventional systems, while operational cost-savings are 40 per cent.
The numbers need explaining, says Koss, given the many factors and choices possible.
The bill of materials of a 16, 32, 64 or 128-GPU design has a 10-30 per cent saving solely from the interconnect.
“The bigger the fabric, the better we scale in price as solutions using tiered leaf-spine-core packet switches involving Ethernet-Infiniband-PCIe are all built around the serdes of the switch chip in the box,” says Koss. “We have a direct-connect fabric with a very high radix, which allows us to build the fabric without stacked tiers like legacy point-to-point networks.”
There are also the power savings, as mentioned. Less power means less heat and hence less cooling.
“We can also change the physical wires in the network,” says Koss, something that can’t be done with leaf-spine-core networks, unless data centre staff change the cabling.
“By grouping resources around a workload, utilisation and performance are much better,” says Koss. “Apps run faster, infrastructure is grouped around workloads, giving users the power to do more with less.”
The system’s evolution is another consideration. A user can upgrade resources because of server disaggregation and the ability to add and remove resources from active machines.
“Imagine that you bought the DynamicXcelerator in 2024. Maybe it was a small sized, four-to-six rack system of GPUs, NVMe, etc,” says Koss. If, in mid-2026, Nvidia releases a new GPU, the user can take several PRU-2000s offline and replace the existing GPUs with the new ones.
“Also if you are an Nvidia shop but want to use the new Mi300 from AMD, no problem,” says Koss. “You can mix GPU vendors with the DynamicXcelerator.” This is different from today’s experience, where what is built is wasteful, expensive, complex, and certainly not climate-conscious, says Koss.
Plans for 2024
Drut has 31 employees, 27 of which are engineers. “We are going on a hiring binge and likely will at least double the company in 2024,” says Koss. “We are hiring in engineering, sales, marketing, and operations.”
Proof-of-concept DynamicXcelerator hardware will be available in the first half of 2024, with general availability then following.

Books in 2023
Gazettabyte asks industry figures to pick their reads of the year. William Koss, Dean Bubley and Scott Wilkinson kick off this year’s recommended reads.
William R Koss, CEO at Drut Technologies
My 2023 reading list is less than normal as the year has been full of technical reading and presentation materials for work. I enjoy history books as well as business history that tell the rise and fall of some company, industry or person.
In Progress
Target Tokyo: The Story of the Sorge Spy Ring by Gordon W. Prange: I picked this book out of Amazon’s recommendation list. Gordon Prange being the author of At Dawn We Slept and Tora, Tora, Tora. Currently plowing through this book that was unfinished at the time of his death.
The Crusades: The War for the Holy Land by Thomas Asbridge. My knowledge of the Crusades was thin and I was looking for a book that provided a grand overview. So far it has not disappointed, but I have had to familiarize myself with many new names.
Completed Reads
Band of Brothers: E Company, 506th Regiment, 101st Airborne, from Normandy to Hitler’s Eagle’s Nest by Stephen E. Ambrose. A second read for me as I watched the series on Netflix over the summer and the thought occurred to read the book and compare and contrast the series to the book. Ambrose is a wonderful writer.
Going Infinite: The Rise and Fall of a New Tycoon by Michael Lewis. I was raising venture capital during the crypto craze from the same firms SBF raised capital and I admit that reading this book is part schadenfreude.
Circle of Treason: CIA Traitor Aldrich Ames and the Men He Betrayed by Sandra Grimes and Jeanne Vertefeuille.A second read for me. Something triggered the thought of Aldrich Ames and I read the book in two days.
The Wager: A Tale of Shipwreck, Mutiny and Murder by David Grann. A very fun read and puts into perspective the speed of news and information that we enjoy today. People thought along the time scale of years in the 1700s
This Kind of War: The Classic Korean War History by T.R. Fehrenbach. My father was in the Korean War and I have read many a book on the subject. It was a new read for me.
Duel in the Sun: Alberto Salazar, Dick Beardsley, and America’s Greatest Marathon by John Brant. My hobby is road cycling, but I have a colleague who has run the Boston Marathon a few times. The Boston Marathon route is within walking distance of my house and my colleague recommended this book as the best book written on marathon racing. I finished it on a couple of airplane rides.
Unscripted: The Epic Battle for a Media Empire and the Redstone Family Legacy by James B. Stewart and Rachel Abrams. A complete disappointment. The book was recommended by a former colleague and I just did not find all the personal details that interesting. I think I was hoping for a better read along the lines of the series Succession which had just ended and that was the reason for my reading.
Castles of Steel: Britain, Germany, and the Winning of the Great War at Sea by Robert K. Massie. Robert Massie is a master historian. One of the greats of our time. I have read Dreadnaught and Castles of Steel a few times. This book is master level history telling. Magnificent in all regards. Sections of the book can be read as short books. The story of Von Spee’s journey from the Pacific to Atlantic could be a single book. I am about to start his book Nicholas and Alexandra about the fall of the Romanov Dynasty.
Dean Bubley, technology industry analyst & futurist at Disruptive Analysis
A recent stand-out for me is Material World: The Six Raw Materials That Shape Modern Civilization by Ed Conway.
I found the book fascinating. It helped me gain a new angle on a lot of the issues faced in the economy and society overall, as well as specific bits of the tech sector.
It tells the stories of the production, processing, transport and use of some of the core minerals we use throughout society and technology. The book covers:
- sand/silicon used for concrete and also semiconductors and optical fibre
- lithium for batteries
- copper for cables, generators and motors
- oil & gas and why they’re still necessary at least for creating products rather than combustion (such as carbon anodes in batteries)
- salt(s) for multiple purposes
- iron & steel
One of the things I often realise is that it is easy to get wrapped up in technology including telecoms. We talk about virtualisation, AI, cloud, orchestration and software all the time.
There’s also a lot of physics. I often talk about radio spectrum and wireless propagation, including 5G and WiFi indoors and through walls. But I don’t pay much attention to the chemistry and materials involved.
This book poses some hard questions, such as where we get enough lithium (and also cobalt and other metals) for decarbonisation, or enough copper for new generators and grid capacity.
My takeout is that the next 20-30 years involve a tightrope walk, buffeted by the winds of physical materials, economics, geopolitics and hidden dependencies. It’s all very well saying ‘just stop doing X’, but sometimes (at least some) of X is essential in order to continue making Y or doing Z.
We also must be careful not just about “supplier diversity” for complex systems like radio access network equipment, or even the components and chips, but all the way down to the raw materials, which may be mined or refined in only a few places around the world.
Worth a read or a listen. I’m an audiobook devotee & this is narrated well enough to listen at 3x speed.
Scott Wilkinson, lead analyst, networking components, Cignal AI
There have been several books this year that I recommended to friends and colleagues. The Cartel by Don Winslow provides unique insights (for fiction) into the crisis at the southern US border.
My son, a Biomechanical Engineering Master’s student at Virginia Tech, and I both read Andy Weir’s Project Hail Mary. It’s like candy to engineers and I enjoyed discussing it with him as he made his way through the chapters.
I recently finished Rod Chernow’s massive biography, Grant, which was fascinating on every page, especially to those who were erroneously taught that he was a mediocre general who won the Civil War due only to attrition and not due to his strategic genius.
But the one book that I recommend the most to my engineering colleagues and history fans is The Great Bridge: The Epic Story of the Building of the Brooklyn Bridge by David McCullough. I’ve read several of McCullough’s histories, but never got around to reading this, his first. The Great Bridge tells the story of the building of the Brooklyn Bridge. It was an engineering feat that is hard to comprehend today.
Anyone driving or taking a subway train across the East River nay have difficulty imagining a time when Brooklyn and Manhattan were separate cities. The only way to get from one to the other was by ferry, and the residents in Brooklyn were worried that any more permanent connection might bring NYC corruption across the river. Washington Roebling took over the project when his father unexpectedly died early in the planning stages. With only his mind and his pencil, he designed every aspect of the bridge from the caissons sunk deep into the river to the cables spanning the towers. Plagued by an unknown disease he contracted after repeatedly descending into the pressurized caissons (what we now know as the bends), Roebling – and his very underappreciated wife, Emily – nevertheless managed a feat that boggles the mind, especially for engineers who let computers do the heavy lifting today.
The book describes challenges ranging from river currents to corruption to political interference, and parallels to modern times are not hard to make. Yet, almost 100 years later, when the bridge was inspected, the only recommendation was to add a coat of paint. The engineering is breathtaking, but the ability of the Chief Engineer to accomplish it with the tools of his time and with all of the roadblocks thrown up is awe-inspiring.
On a recent visit to New York to visit my daughter during her internship at the AMNH, I tried to convince the family to all travel down to the Brooklyn Bridge, just to look at it again in person. I was overruled, but that’s ok. It’ll still be there the next time, and for a long time after.

The long arm of PCI Express
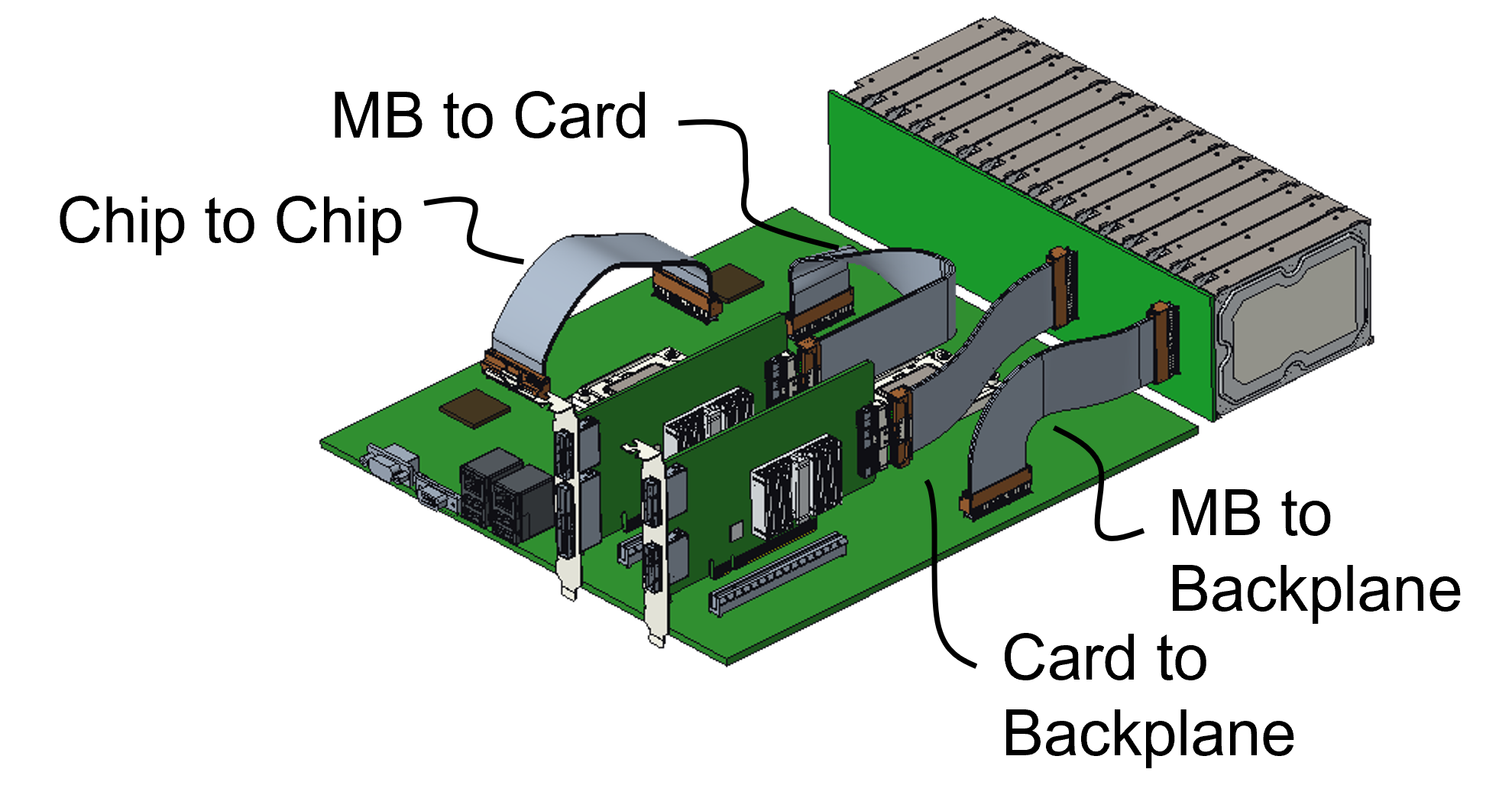
- Optical is being added as a second physical medium to the PCI Express (PCIe) data transfer protocol.
- PCI Express is an electrical standard, but now the Peripheral Component Interconnect Special Interest Group (PCI-SIG) has created a working group to standardise PCIe’s delivery optically.
- PCI-SIG is already developing copper cabling specifications for the PCI Express 5.0 and 6.0 standards.
Since each generation of PCIe doubles the data transfer rate, PCI-SIG member companies want copper cabling to help with the design of high-speed PCIe interconnects on a printed circuit board (PCB), between PCBs, and between racks (see diagram).
“We’ve seen a lot of interest over recent months for an optical cable that will support PCI Express,” says Al Yanes, PCI-SIG president and chairperson.
He cites the trends of the decreasing cost and size of optics and how silicon photonics enables the adding of optics alongside ASICs.
“We have formed a workgroup to deliver an optical cable,” says Yanes. “There are many applications, but one is a longer-distance reach for PCI Express.”
“It is a void in the market [the lack of optical support for PCIe], and it needs to be filled,” says Bill Koss, CEO of Drut Technologies. “These efforts tend to take longer than estimated, so better to start sooner.”
Drut has developed a PCIe over photonics solution as part of its photonic direct connect fabric for the data centre.
The data centre is going photonic, says Koss, so there is a need for such working standards as photonics get closer to processors.
The PCIe protocol
PCIe is used widely across many industries.
In the data centre, PCIe is used by general-purpose microprocessors and accelerator chips, such as FPGAs, graphics processing units and AI hardware, to connect to storage and network interface cards.
The PCIe bus uses point-to-point communications based on a simple duplex scheme – serial transmissions in both directions which is referred to as a lane.
The bus can be bundled in various lane configurations – x1, x2, x4, x8, x12, x16 and x32 – with x4, x8 and x16 the configurations most used.
The first two PCIe versions, 1.0 and 2.0, delivered 2.5 and 5 giga transfers-per-second (GT/s) per lane per direction, respectively.
A transfer refers to an encoded bit. The first two PCIe versions use an 8b/10b encoding scheme such that for every ten-bit payload sent, 8 bits are data. This is why the data transfer rates per lane per direction are 2Gbps and 4Gbps (250 and 500 gigabytes per second), respectively.
With PCIe 3.0, the decision was made to increase the transfer rate to 8GT/s per lane, which assumed that no equalisation would be needed to counter inter-symbol interference at that speed. However, equalisation was required, which explains why PCIe 3.0 adopted 8GT/s and not 10GT/s.
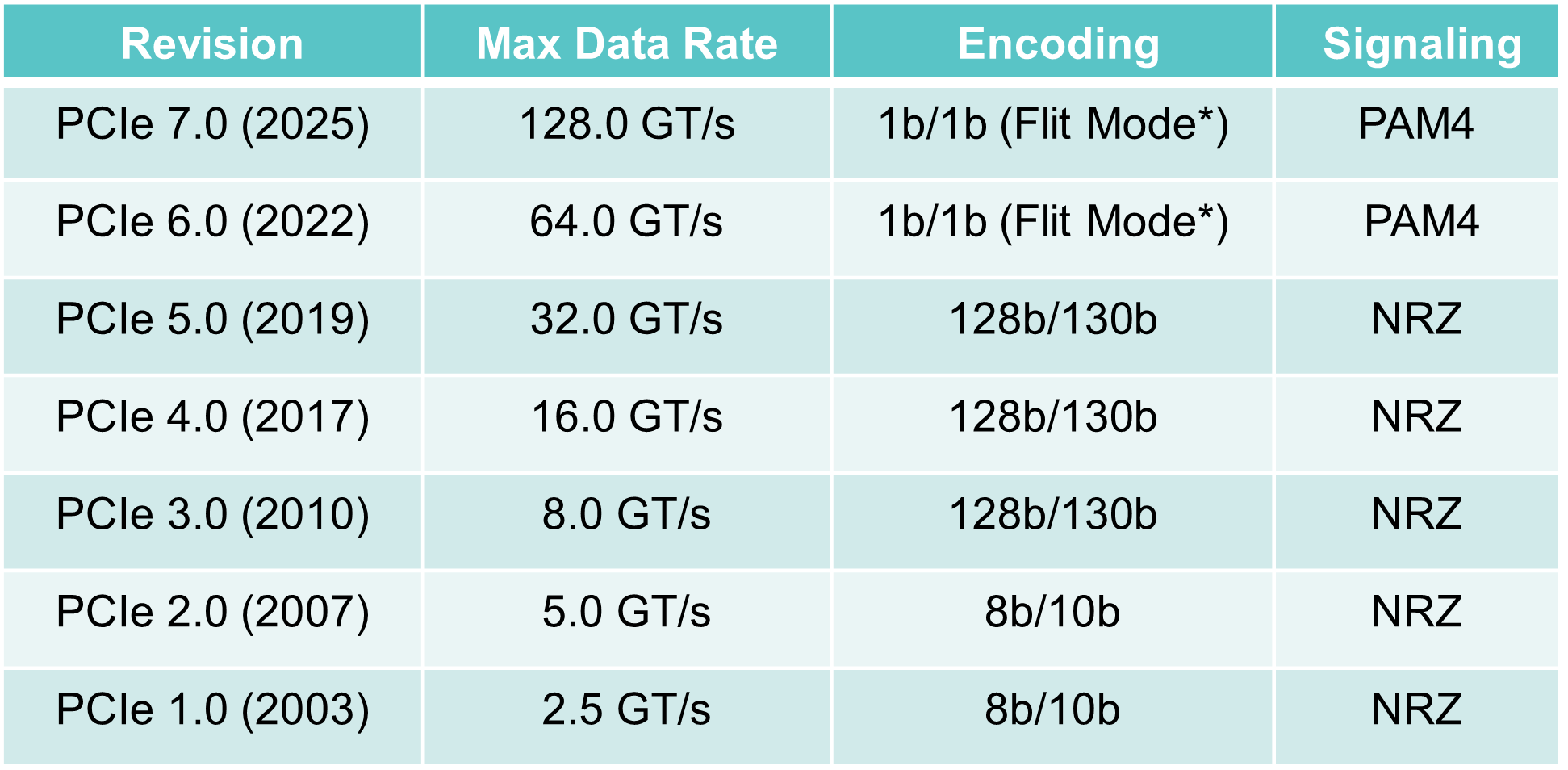
Another PCIe 3.0 decision was to move to a 128b/130b scheme to reduce the encoding overhead from 20 per cent to over 1 per cent. Now the transfer and bit rates are almost equal from the PCIe 3.0 standard onwards.
PCIe 4.0 doubles the transfer rate from 8GT/s to 16GT/s, while PCIe 5.0 is 32GT/s per lane per direction.
Since then, PCIe 6.0 has been specified, supporting 64GT/s per lane per direction. PCIe 6.0 is the first standard for 4-level pulse amplitude modulation (PAM4) signalling.
Now the PCIe 7.0 specification work is at version 0.3. PCIe 7.0 uses PAM-4 to deliver 128GT/s per lane per direction. The standard is expected to be completed in 2025, with industry adoption in 2027.
Optical cabling for PCIe
The PCI Express 5.0 and 6.0 copper cabling specifications are expected by the year-end. The expected distance using copper cabling and retimers is 5-6m.
The reach of an optical PCIe standard will ‘go a lot further’ than that, but how far is to be determined.
Yanes says optical cables for PCIe will also save space: “An optical cable is not as bulky nor as thick as a copper cable.”
Whether the optical specification work will support all versions of PCIe is to be determined.
“There’s some interest to support them all; the copper solution supports all the negotiations,” says Yanes. “It’s something that needs to be discussed, but, for sure, it will be the higher speeds.”
The working group will decide what optical options to specify. “We know that there are some basic things that we need to do to PCI Express technology to make it support optics,” says Yanes.
The working group aims to make the specification work generic enough that it is ‘optical friendly’.
“There are many optical techniques in the industry, and there is discussion as to which of these optical techniques is going to be the winner in terms of usage,” says Yanes. “We want our changes to make PCI Express independent of that discussion.”
The organisation will make the required changes to the base specification of PCIe to suit optical transmission while identifying which optical solutions to address and build.
PCI-SIG will use the same Flit Mode and the same link training, for example, while the potential specification enhancements include coordinating speed transitions to match the optics, making side-band signals in-band, and making the specification more power-efficient given the extended reach.
Pluggable optical modules, active optical cables, on-board optics, co-packaged optics and optical input-output are all optical solutions being considered.
An optical solution for PCIe will also benefit technologies such as Compute Express Link (CXL) and the Non-Volatile Memory Express (NVMe) protocols implemented over PCIe. CXL, as it is adopted more broadly, will likely drive new uses that will need such technology.
The PCIe optical working group will complete the specifications in 12-18 months. Yanes says a quicker working solution may be offered before then.

Drut's agile optical fabric for the data centre
A US start-up has developed a photonic fabric for the data centre that pulls together the hardware needed for a computational task.
Drut Technologies offers management software and a custom line card, which, when coupled with the optical switch, grabs the hardware required for the workload.
“You can have a server with lots of resource machines: lots of graphic processing units (GPUs) and lots of memory,” says Bill Koss, CEO of Drut. “You create a machine, attach a workload to it and run it; forever, for a day, or 15 minutes.”
Drut first showcased its technology supporting the PCI Express (PCIe) bus over photonics at server specialist, SuperMicro’s exhibition stand, at the Supercomputing 22 show held last November in Dallas, Texas.
“This is a fully reconfigurable, direct-connect optical fabric for the data centre,” says Koss.
Drut says hyperscalers use between 40 and 60 per cent of the hardware in their data centres. With direct connectivity, resources can be used as needed and released, improving overall hardware utilisation.
Optical circuit switching
Drut’s system is a second recent example of a company using optics for the data centre to establish reconfigurable photonic paths between endpoints, referred to as optical circuit switching.
Google revealed in August 2022 that it had developed its own MEMS-based optical switch design, which the hyperscaler has used for several years in its data centres.
The optical circuit switches are used instead of the highest tier of Ethernet switches – the spine layer – in Google’s data centres.
Using optical circuit switching reduces networking costs by 30 per cent and power consumption by over 40 per cent. The optical switch layer also enables more efficient and less disruptive upgrading of the server endpoints.
Koss says the difference between its design and Google’s is scale: “Ours is more granular.”
Drut says its solution will enable racks of optically-attached machines, but unlike Google, the optical switching is much closer to the end equipment. Indeed, it is a second fabric independent of the data centre’s tiered Ethernet switches.

Product architecture
The main three elements of Drut’s technology are an FPGA-based line card, the fabric-manager software and a third-party optical switch.
Drut’s line card, the iFIC 1000, has an FPGA and four 100-gigabit transceivers. “That is as much as we can fit on,” says Koss.

The company uses its own transport protocol that runs over the fabric, an ‘out-of-band’ network design.
“You can dynamically attach and detach, and the machine doesn’t go into crazy land,” says Koss.
The fabric manager knows all the ports of the switch and the endpoints and sets up the desired system configurations.
With the fabric management software and the FPGA, the system can configure banks of graphic processing units (GPUs).
Drut has also demonstrated linking memory over its photonic fabric, although this is in development and still unavailable as a product.
Drut says a primary challenge was developing the FPGA that takes the out-of-band signalling off the main bus and supports it over the optical fabric.
A photonic fabric design promises to change the nature of a server. A user will request CPUs, accelerators such as GPUs and FPGAs, and memory, as needed, for each workload.
The merits of using an optical switch include its support for multiple ports, i.e. the switch’s large radix, and its being interface-speed agnostic.
The photonic switch also has a lower latency than switch ICs and simplifies cabling. “It is all single-mode fibre pluggable optics,” says Koss.

Status
Drut is developing a second line card which will use a larger FPGA. Each card generation will expand the number of optical ports to scale the endpoints supported.
The company is also working with a co-packaged optics player on a design for a hyperscaler.
“We use pluggable optics today because co-packaged optics isn’t available,” says Koss.
The advantage of co-packaged optics is that it will increase the port density on each line card and hence the overall scaling.
Koss says that Drut already has two customers: an enterprise and a cloud provider.
Drut, which means ‘high tempo’ in Sanskrit, has so far secured two rounds of funding.
“We did a good-sized seed round in June 2021 and closed a bigger seed extension last September; not an easy task in 2022,” says Koss. “We added Boston Seed Capital and another firm as new investors as well.”
The company has sufficient funding till 2024 and is talking to new investors for a Series A funding round.