
OFC 2025 industry reflections - Final Part

Gazettabyte has been asking industry figures for their thoughts after attending the OFC conference held in San Francisco.
In the final part, Arista’s Vijay Vusirikala and Andy Bechtolsheim, Chris Doerr of Aloe Semiconductor, Adtran’s Jörg-Peter Elbers, and Omdia’s Daryl Inniss share their learnings. Vusirikala, Doerr, and Elbers all participated in OFC’s excellent Rump Session.
Vijay Vusirikala, Distinguished Lead, AI Systems and Networks, and Andy Bechtolsheim, Chief Architect, at Arista Networks.
OFC 2025 wasn’t just another conference. The event felt like a significant momentum-gaining inflexion point, buzzing with an energy reminiscent of the Dot.com era optical boom.
This palpable excitement, reflected in record attendance and exhibitor numbers, was accentuated for the broader community by the context set at Nvidia’s GTC event held two weeks before OFC, highlighting the critical role optical technologies play in enabling next-generation AI infrastructure.
This year’s OFC moved beyond incremental updates, showcasing a convergence of foundational technologies and establishing optics not just as a supporting player but a core driver in the AI era. The scale of innovation directed towards AI-centric solutions – tackling power consumption, bandwidth density, and latency – was striking.
Key trends that stood out were as follows:
Lower Power Interconnect technologies
The overarching topic was the need for more power-efficient optics for high-bandwidth AI fabrics. Legacy data centre optics are impacting the number of GPUs that fit into a given data centre’s power envelope.
Three main strategies were presented to address the power issue.
First, whenever possible, use copper cables, which are far more reliable and cost less than optics. The limitation, of course, is copper’s reach, which at 200 gigabit-per-lane is about 1-2m for passive copper cables and 3-4m for active redriven copper cables.
Second, eliminate the traditional digital signal processor (DSP) and use linear interface optics, including Linear Pluggable Optics (LPO), Near Package Optics (NPO), and Co-Packaged Optics (CPO), all of which offer substantial (60%) power savings, lower latency, and higher reliability compared to traditional DSP solutions.
The biggest difference between linear pluggable optics and co-packaged optics is that linear pluggable optics retains the well-known operational advantages of pluggable modules: configurability, multi-vendor support, and easy field serviceability (hot-swapping at module level), compared to fixed optics like co-packaged optics, which require chassis-level RMAs (return materials authorisation). It remains to be seen whether co-packaged optics can overcome the serviceability issues.
Third, developments in a host of new technologies – advances in copper interconnects, microLED-based interconnects, and THz-RF-over-waveguides – promise even lower power consumption than current silicon photonics-based interconnect technologies.
We look forward to hearing more about these new technologies next year.
Transition from 200 gigabit-per-lambda to 400 gigabit-per-lambda
With the 200 gigabit-per-lambda optical generation just moving into volume production in 2025-26, attention has already turned to the advancement and challenges of 400 gigabit-per-lambda optical technologies for future high-speed data transmission, aiming towards 3,200 gigabit (8×400 gigabit) modules.
Several technical approaches for achieving 400 gigabit-per-lambda were discussed, including PAM-4 intensity modulation direct detection (IMDD), PAM-4 dual-polarisation, and optical time division multiplexing (OTDM). The technology choices here include indium phosphide, thin-film lithium niobate (TFLN), and silicon photonics, which are compared based on RF (radio frequency) loss, integration, cost, and high-volume readiness.
For 400 gigabit lambda optics, indium phosphide and thin-film lithium niobate are strong candidates, as silicon photonics will struggle with the high bandwidth.
At this point, it is impossible to predict which platform will emerge as the high-volume winner. Delivering power and cost-effective 400-gigabit lambda optics will require a concerted industry effort from optical component suppliers, connector suppliers, and test and measurement vendors.
Multi-core fibre
A new pain point in large AI data centres is the sheer number of fibre cables and their associated volume and weight. One way to solve this problem is to combine multiple fibre cores in a single fibre, starting initially with four cores, which would offer a 4:1 reduction in fibre count, bulk, and weight.
Hollow-core fibre
Innovation continues in the foundational fibre itself. Hollow-core fibre generated significant buzz, with its potential for lower latency and wider bandwidth attracting intense interest.
The maturing hollow-core fibre ecosystem, including cabling and interconnection progress, suggests deployments beyond niche applications like high-frequency trading may be approaching, reaching areas like distributed AI processing.
AI-driven network evolution
AI isn’t just driving network demand, it is increasingly becoming a network management tool.
Numerous demonstrations showcased AI/machine learning applications for network automation, traffic prediction, anomaly detection, predictive maintenance – e.g., analysing optical time-domain reflectometer (OTDR) traces, configuration management, and resource optimisation. This represents a fundamental shift towards more efficient, reliable, self-configuring, self-healing, and self-optimising networks.
Along with the many technical talks and tutorials, show floor demos, and customer and supplier meetings, OFC attendees also had a chance to combine technology with some light-hearted fun at the rump session.
This year’s topic was rebuilding global communication infrastructure after an alien invasion, and three teams came up with thought-provoking ideas for this theme.
Chris Doerr, CEO of Aloe Semiconductor
The best way to describe OFC 2025 is a giant Mars dust storm that raged for days. The swirling sand made it difficult to see anything clearly, and the sound was so loud you couldn’t think.
Acronyms ending in “O” were hitting you from all sides: LPO, LRO, NPO, CPO, OIO. The wind blew away sand that had buried old technologies, such as lithium niobate, electro-optic polymer, and indium-phosphide modulators, and they joined the fray.
Only now that the storm has somewhat subsided can we start piecing together what the future holds.
The main driver of the storm was, of course, artificial intelligence (AI) systems. AI requires a vast number of communication interconnects. Most interconnects, at least within a rack, are still copper. While copper keeps making incredible strides in density and reach, a fibre-optic interconnect takeover seems more and more inevitable.
The Nvidia announcements of co-packaged optics (CPO), which go beyond co-packaged optics and deserve a new name, such as optical input-output (OIO) or system-on-chip (SOC), created a great deal of excitement and rethinking. Nvidia employs a silicon interposer that significantly increases the electrical escape density and shortens the electrical links. This is important for the long-term evolution of AI computing.
The CPO/OIO/SOC doesn’t mean the end of pluggables. Pluggables still bring tremendous value with attributes such as time-to-market, ecosystem, replaceability, etc.
Most pluggables will still be fully retimed, but 100 gigabit-per-lane seems comfortable with linear pluggable optics (LPO), and 200 gigabit-per-lane is starting to accept linear receive optics (LRO).
For 200 gigabit per lane, electro-absorption modulated lasers (EMLs) and silicon photonics have comfortably taken the lead. However, for 400 gigabit per lane, which had two main demos on the show floor by Ciena and Marvell, many technologies are jockeying for position, mostly EMLs, thin-film lithium niobate (TFLN), indium phosphide, and silicon photonics.
Many companies are abandoning silicon photonics, but this author feels this is premature. There were demos at OFC of silicon photonics attaining near 400 gigabit-per-lane, and the technology is capable of it.
An important thing to remember is that the new OIO/SOC technology is silicon photonics and comes from a CMOS foundry. Putting non-CMOS materials such as thin-film lithium niobate or indium phosphide in such a platform could take years of expensive development and is thus unlikely.
In summary, OFC 2025 was very active and exciting. Significant technology improvements and innovations are needed.
The dust is far from settled, so we must continue wading into the storm and trying to understand it all.
Jörg-Peter Elbers, Senior Vice President, Advanced Technology, Standards and IPR, Adtran
OFC 2025 marked its largest attendance since 2003 with nearly 17,000 visitors, as it celebrated its 50th anniversary.
Discussions in 1975 centred around advances in fibre technology for telecommunications. This year’s hottest topic was undoubtedly optical interconnects for large-scale AI clusters.
Following an insightful plenary talk by Pradeep Sindhu from Microsoft on AI data centre architecture, sessions were packed in which co-packaged optics (CPO) and associated technologies were discussed. The excitement had been fueled by Nvidia’s earlier announcement of using co-packaged optics in its next generation of Ethernet and Infiniband switches.
The show floor featured 800 gigabit-per-second (Gbps), 1.6 terabit-per-second (Tbps), and the first 3.2Tbps interconnect demonstrations using different interface standards and technologies.
For access, 50G-PON was showcased in triple PON coexistence mode, while interest in next-generation very high-speed PON spurred the technical sessions.
Other standout topics included numerous papers on fibre sensing, stimulating discussions on optical satellite communications, and a post-deadline paper demonstrating unrepeated hollow-core fibre transmission over more than 200km.
OFC 2025 was fun too. When else do you get to reimagine communications after an alien attack, as in this year’s rump session?
No visit to San Francisco is complete without trying one of Waymo’s self-driving taxis. Having been proud of Dmitri Dolgov, Waymo’s CEO, for his plenary talk at OFC 2019, it was thrilling to see autonomous driving in action. I love technology!
Daryl Inniss, Omdia Consultant, Optical Components and Fibre Technologies
I worked on commercialising fibre technology for emerging applications at OFS – now Lightera – from 2016 to 2023. I spent the prior 15 years researching and analysing the optical components market.
Today, I see a market on the cusp of a transition due to the unabated bandwidth demand and the rise of computing architectures to support high-performance computing (HPC) and artificial intelligence (AI).
Even optical fibre, the fundamental optical communications building block, is under intense scrutiny to deliver performance suitable for the next 30 to 50 years. Options include hollow-core and multi-core fibre, two of the three fibre technologies that caught my attention at OFC 2025.
The third, polarisation-maintaining fibre arrays for co-package optics, is one part of the conference’s biggest story. OFC 2025 provided a status update on these technologies.
Hollow-core fibre
OFC’s first day hollow-core fibre workshop (S2A) illustrated its niche status and its potential to remain in this state until the fibre is standardised. The industry ecosystem was well represented at the session.
Not surprisingly, challenges highlighted and summarised by Russ Ellis, Microsoft’s Principal Cloud Network Engineer, included manufacturing, field installation, field splicing, cabling, and termination inside the data centre. These are all expected topics and well understood.
I was surprised to hear Microsoft report that the lack of an established ecosystem was a challenge, and I’ll explain why below.
Coming into OFC, the biggest market question was fibre manufacturing scalability, as most reported draws are 5km or less. Supplier YOFC put this concern to rest by showcasing a +20 km spool from a single fibre draw on the show floor. And Yingying Wang, CEO of Linfiber, reported that 50 to 100km preforms will be available this year.
In short, suppliers can scale hollow-core fibre production.
From a field performance perspective, Microsoft highlighted numerous deployments illustrating successful fibre manufacturing, cabling, splicing, termination, installation, and testing. The company also reported no field failures or outages for cables installed over five years ago.
However, to my knowledge, the hollow-core fibre ecosystem challenge is a consequence of a lack of standardisation and discussion about standardisation.
Each fibre vendor has a different fibre design and a different glass outer diameter. Microsoft’s lack-of-an-ecosystem comment mentioned above is therefore unsurprising. Only when the fibre is standardised can an ecosystem emerge, generating volumes and reducing costs,
Today, only vertically integrated players benefit from hollow-core fibre. Until the fibre is standardised, technology development and adoption will be stunted.
Multi-core fibre
I was pleasantly surprised to find multiple transceiver vendors showcasing modules with integrated fan-in/fan-out (FIFO). This is a good idea as it supports multi-core fibre adoption.
One vendor is targeting FR4 (TeraHop for 2x400G), while another is targeting DR8 (Hyper Photonix for 8x100G). There is a need to increase core density, and it is good to see these developments.
However, we are still very far from multi-core fibre commercialisation as numerous operational factors, for example, are impacted. The good news is that multi-core fibre standardisation is progressing.
Polarisation-maintaining fibre
According to Nick Psaila, Intel’s principal engineer and technology development manager, polarisation-maintaining fibre arrays remain expensive.
The comment was made at Optica’s February online Industry Meeting and verified in my follow-up conversation with Psaila.
Using an external laser source is the leading approach to deliver light for co-packaged optics, highlighting an opportunity for high-volume, low-cost polarisation-maintaining fibre arrays.
Co-packaged optics were undoubtedly the most significant topic of the show.
Coherent showcased a 3Tbps concept product of VCSELs to be used in co-packaged optics. Given that multimode fibre is used in the shortest optical connections in data centres and that VCSELs have very low power consumption, I’m surprised I’ve not heard more about their use for this application.
Testing of emerging photonic solutions for HPC and AI devices has been identified as a bottleneck. Quantifi Photonics has taken on this challenge. The company introduced an oscilloscope that provided quality results comparable to industry-leading ones and is designed for parallel measurements. It targets photonic devices being designed for co-packaged optics applications.
Multiple channels, each with wavelength-division multiplexing lasers, must be tested in addition to all the electrical channels. This is time-consuming, expensive process, particularly using existing equipment.
Polymer modulators continue to be interesting because they have high bandwidth and the potential to be inexpensive. However, reliability is their challenge. Another vendor, NLM Photonics, is targeting this application.
The many vendors offering optical circuit switches was a surprising development. I wonder if this opportunity is sufficiently large to justify the number of vendors. I’m told that numerous internet content providers are interested in the technology. Moreover, these switches may be adopted in telecom networks. This is a topic that needs continual attention, specifically regarding the requirements based on the application.
Lastly, Lightmatter provided a clear description of its technology. An important factor is the optical interposer that removes input-output connectivity from the chip’s edge, thereby overcoming bandwidth limitations.
I was surprised to learn that the laser is the company’s design, although Lightmatter has yet to reveal more.

ECOC 2024 industry reflections - Part III
Gazettabyte is asking industry figures for their thoughts after attending the recent 50th-anniversary ECOC show in Frankfurt. Here are contributions from Aloe Semiconductor’s Chris Doerr, Hacene Chaouch of Arista Networks, and Lumentum’s Marc Stiller.
Autumn morning near the ECOC congress centre in Frankfurt
If there was one overall message from ECOC 2024 this year, it is that incumbent technologies are winning in the communications market.
Copper is not giving up. It consumes less power and is cheaper than optics, and now, more electronics such as retimers are being applied to keep direct-attach copper (DAC) cables going. Also, 200-plus gigabaud (GBd) made a debut in coherent optics, but in intensity-modulation direct-detect (IMDD), 50GBd and 100GBd look like they are here to stay for several more years.
Pluggables are entrenching themselves more deeply. For large-scale co-packaged optics to unseat them seems further away than ever. The reason for the recent success of incumbent technologies is practicality. Large computing clusters and data centres need more bandwidth immediately, and there is not enough time to develop new technologies.
Probably the most significant practical constraint is power consumption. Communications is becoming a significant fraction of total power consumption, further driven by the desire to disaggregate to spread out the power consumption. Liquid cooling demonstrations are becoming commonplace.
Power consumption may limit the market as customers cannot obtain more power. This may mean the lowest power solution will win, making cost, complexity, and size secondary considerations.
Hacene Chaouch, Distinguished Engineer, Arista Networks
Unlike the 2023 edition, ECOC 2024 overwhelmingly and unanimously put power consumption on a pedestal.
Sleepwalking the last decade on incremental power-per-bit improvements, the AI boom has caught the optics industry off guard. Every extra Watt wasted on optics and the associated cooling systems matters since that power is not available to the Graphics Processing Units (GPUs) that generate revenue.
In this context, seeing 30W 1.6-terabit digital signal processor (DSP) optical modules demonstrated at the show floor was disappointing. This is especially so when compared to 1.6-terabit linear pluggable optics (LPO) with prototypes consuming only 10W.
The industry must and can do better to address the power gap of 1.6-terabit DSP-based optics.
Marc Stiller, Lumentum’s Vice President of Product Line Management, Cloud and Networking
ECOC 2024 saw AI emerge as a focal point for many discussions and technology drivers, continuing trends we observed at OFC earlier this year. ECOC showcased numerous new technologies and steady progress on products addressing the insatiable appetite for bandwidth.
LPO was visible, with steady advancements in performance and interoperability and a new multi-source agreement (MSA) pending. There was an overall emphasis on power efficiency and cooling solutions, driven by the increasing scale of machine learning/ AI clusters and the power availability to cool them.
Another focus was 1.6-terabit interfaces with multiple suppliers showcasing their progress. Electro-absorption modulated laser (EML) and silicon photonics solutions continue to evolve, with EMLs showing an early lead.
Other notable demonstrations emphasised breakthroughs in higher data rates and energy-efficient solutions, addressing the critical challenge of increasing memory bandwidth. Nvidia signalled their commitment to driving the pace of optics with a newly developed PAM4 DSP.
From a networking perspective, 800-gigabit is becoming the new standard, particularly with C- and L-bands gaining traction as the industry approaches the Shannon limit. Integration is more critical than ever for achieving power and cost efficiencies, especially as 800-gigabit ZR and ZR+ solutions become more prominent.
Lumentum showcased high-performance transceivers and provided critical insights into the future of networking at ECOC, reinforcing our leadership in driving these innovations forward.

The market opportunity for linear drive optics
A key theme at OFC earlier this year that surprised many was linear drive optics. Its attention at the optical communications and networking event was intriguing because linear drive – based on using remote silicon to drive photonics – is not new.
“I spoke to one company that had a [linear drive] demo on the show floor,” says Scott Wilkinson, lead analyst for networking components at Cignal AI. “They had been working on the technology for four years and were taken aback; they weren’t expecting people to come by and ask about it. “
The cause of the buzz? Andy Bechtolsheim, famed investor, co-founder and chief development officer of network switching firm Arista Networks and, before that, a co-founder of Sun Microsystems.
“Andy came out and said this is a big deal, and that got many people talking about it,” says Wilkinson, author of a recent linear drive market research report.
Linear Drive
A data centre’s switch chip links to the platform’s pluggable optics via an electrical link. The switch chip’s serialiser-deserialiser (serdes) circuitry drives the signal across the printed circuit board to the pluggable optical module. A digital signal processor (DSP) chip inside the pluggable module cleans and regenerates the received signal before sending it on optically.
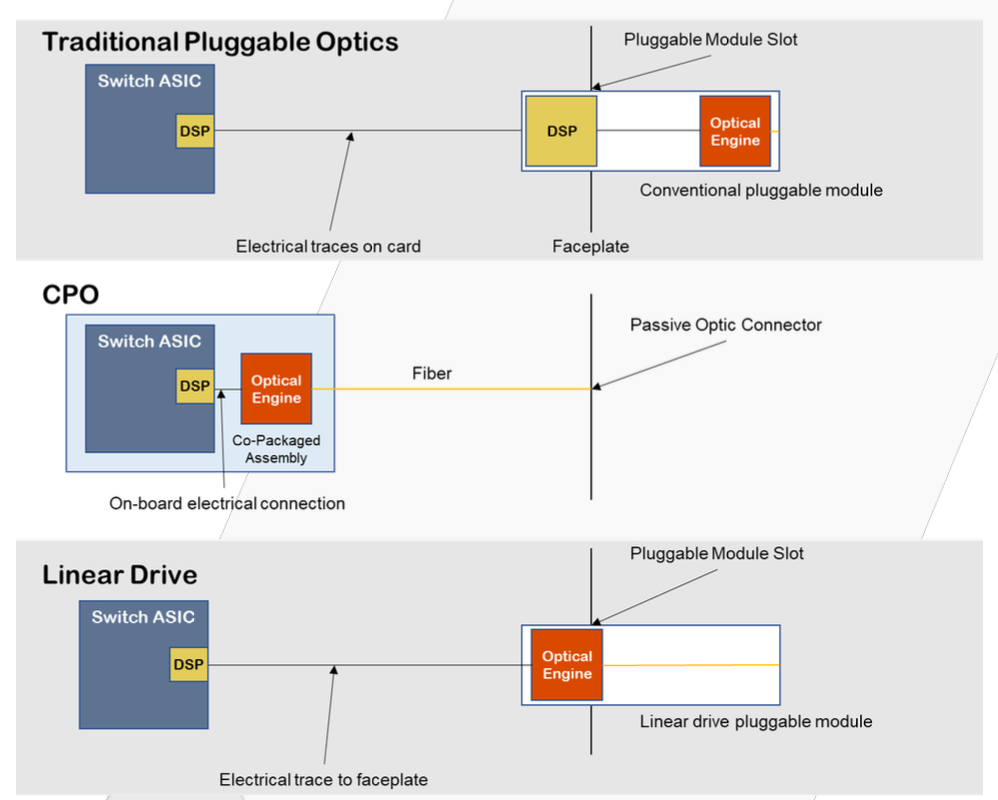
With linear drive optics, the switch ASIC’s serdes directly drives the module optics, removing the need for the module’s DSP chip. This cuts the module’s power consumption by half.
The diagram above contrasts linear drive optics compared with traditional pluggables and the emerging technology of co-packaged optics where the optics are adjacent to the switch chip and are packaged together. Linear drive optics can be viewed as a long-distance variant of co-packaged optics that comntinues to advance pluggable modules.
Proponents of linear drive claim that the power savings are a huge deal. “There will probably also be some cost savings, but it is not entirely clear how big they will be,” says Wilkinson. “But the only thing people want to discuss is the power savings.”
Misgivings
If linear drive’s main benefit is reducing power consumption, the technology’s sceptics counter with several technical and business issues.
One shortfall is that a module’s electrical and optical lanes must match in number and hence data rate. If there is a mismatch, the signal speeds must be translated between the electrical and optical lane rates, known as gearboxing. This task requires a DSP. Linear drive optics is thus confined to 800-gigabit optical modules: 800GBASE-DR8 and 800-gigabit 2xFR4. “There are people who think that at least 800 Gig – eight lanes in and eight lanes out – will continue to exist for a long time,” says Wilkinson.
Another question mark concerns the use of optics for artificial intelligence workloads. Adopters of AI will be early users of 200 gigabit-per-lane optics, requiring a gearbox-performing DSP.
Moreover, the advent of 200-gigabit electrical lanes will challenge serdes developers and, hence, linear drive designs. “It will be a technical challenge, the distances will be shorter, and some think it may never work,” says Wilkinson. “No matter how good the serdes is, it will not be easy.”
Co-packaged optics will also hit its stride once 200-gigabit serdes-based switch chips become available.
Another argument is that there are many ways to save power in the data centre; if linear drive introduces complications, why make it a priority?
Linear drive optics requires the switch chip vendors to develop high-quality serdes. Wilkinson says the leading switch vendors remain agnostic to linear drive, which is not a ringing endorsement. And while hyperscalers are investing time and resources into linear-drive technology, none have endorsed the technology such that they can withdraw at any stage without penalty.
“There is one story for linear drive and many stories against it,” admits Wilkinson. “When you compile them, it’s a pretty big story.”
Market opportunity
Cignal AI believes linear-drive optics will prove a niche market, with 800-gigabit linear-drive modules capturing 10 per cent of overall 800-gigabit pluggable shipments in 2027.
Wilkinson says the most promising example of the technology is active optical cables, where the modules and cables are a closed design. And while many companies are invested in the technology, and it will be successful, the opportunity will not be as significant as the proponents hope.

Companies gear up to make 800 Gig modules a reality
Nine companies have established a multi-source agreement (MSA) to develop optical specifications for 800-gigabit pluggable modules.
The MSA has been created to address the continual demand for more networking capacity in the data centre, a need that is doubling roughly every two years. The largest switch chips deployed have a 12.8 terabit-per-second (Tbps) switching capacity while 25.6-terabit and 51-terabit chips are in development.
“The MSA members believe that for 25.6Tbps and 51.2Tbps switching silicon, 800-gigabit interconnects are required to deliver the required footprint and density,” says Maxim Kuschnerov, a spokesperson for the 800G Pluggable MSA.
A 1-rack-unit (1RU) 25.6-terabit switch platform will use 32, 800-gigabit modules while a 51.2-terabit 2RU platform will require 64.
The MSA has been founded now to ensure that there will be optical and electrical components for 800-gigabit modules...
Motivation
The founding members of the 800G MSA are Accelink, China Telecommunication Technology Labs, H3C, Hisense Broadband, Huawei Technology, Luxshare, Sumitomo Electric Industries, Tencent, and Yamaichi Electronics. Baidu, Inphi and Lumentum have since joined the MSA.
The MSA has been founded now to ensure that there will be optical and electrical components for 800-gigabit modules when 51.2-terabit platforms arrive in 2022.
And an 800-gigabit module will be needed rather than a dual 400-gigabit design since the latter will not be economical.
“Historically, the cost of optical short-reach interfaces has always scaled with laser count,” says Kuschnerov. “Pluggables with 8, 10 or 16 lasers have never been successful in the long run.”
He cites such examples as the first 100-gigabit module implemented using 10×10-gigabit channels, and the early wide-channel 400 Gigabit Ethernet designs such as the SR16 parallel fibre and the FR8 specifications. The yield for optics doesn’t scale in the same way as CMOS for parallel designs, he says.
That said, the MSA will investigate several designs for the different reaches. For 100m, 8-channel and 4-channel parallel fibre designs will be explored while for the longer reaches, single-fibre coarse wavelength division multiplexing (CWDM) technology will be used.

Shown from left to right are a PSM8 and a PSM4 module for 100m spans, and the CWDM4 design for 500m and 2km reaches. Source: 800G Pluggable MSA.
“Right now, we are discussing several technical options, so there’s no conclusion as to which design is best for which reach class,” says Kuschnerov.
The move to fewer channels is similar to how 400 Gigabit Ethernet modules have evolved: the 8-channel FR8 and LR8 module designs address early applications but, as demand ramp, they have made way for more economical four-channel FR4 and LR4 designs.
Specification work
The MSA will focus on several optical designs for the 800G Pluggable MSA, all using 112Gbps electrical input signals.
The first MSA design, for applications up to 100m, will explore 8×100-gigabit optical channels as a fast-to-market solution. This is a parallel single-mode 8-channel (PSM8) design, with each 100-gigabit channel carried over a dedicated fibre. The module will use 16 fibres overall: eight for input and eight for output. The MSA will also explore a PSM4 design – ‘the real 800G’ – where each fibre carries 200 gigabits.
The CWDM designs, for 500m and 2km, will require a digital signal processor (DSP) to implement four-level pulse-amplitude modulation (PAM4) signalling that generates the 200-gigabit channels. An optical multiplexer and demultiplexer will also be needed for the two designs.

The MSA will explore the best technologies for each of the three spans. The modulation technologies to be investigated include silicon photonics, directly modulated lasers (DML) and externally modulated lasers (EML).
Challenges
The MSA foresees several technical challenges at 800 gigabits.
One challenge is developing 100-gigabaud direct-detect optics needed to generate the four 200 gigabit channels using PAM4. Another is fitting the designs into a QSFP-DD or OSFP pluggable module while meeting their specified power consumption limitations. A third challenge is choosing a low-power forward error correction scheme and a PAM4 digital signal processor (DSP) that meet the MSA’s performance and latency requirements.
“We expect first conclusions in the fourth quarter of 2020 with the publication of the first specification,” says Kuschnerov.
The 800G Pluggable MSA is also following industry developments such as the IEEE proposal for the 8×100-gigabit SR8 over multi-mode fibre that uses VCSELs. But the MSA believes VCSELs represent a higher risk.
“Our biggest challenge is creating sufficient momentum for the 800-gigabit ecosystem, and getting key industry contributors involved in our activity,” says Kuschnerov.
Arista Networks, the switch vendor that has long promoted 800-gigabit modules, says it has no immediate plans to join the MSA.
“But as one of the supporters of the OSFP MSA, we are aligned in the need to develop an ecosystem of technology suppliers for components and test equipment for OSFP pluggable optics at 800 gigabits,” says Martin Hull, Arista’s associate vice president, systems engineering and platforms.
Hull points out that the OSFP pluggable module MSA was specified with 800 gigabits in mind.
Next-generation Ethernet
The fact that there is no 800 Gigabit Ethernet standard will not hamper the work, and the MSA cannot wait for the development of such a standard.
“The IEEE is in the bandwidth assessment stage for beyond 400-gigabit rates and we haven’t seen too many contributions,” says Kuschnerov. The IEEE would then need to start a Call For Interest and define an 800GbE Study Group to evaluate the technical feasibility of 800GbE. Only then will an 800GbE Task Force Phase start. “We don’t expect the work on 800GbE in IEEE to progress in line with our target for component sampling,” says Kuschnerov. First prototype 800G MSA modules are expected in the fourth quarter of 2021.
Arista’s Hull stresses that an 800GbE standard is not needed given that 800-gigabit modules support standardised rates based on 2×400-gigabit and 8×100-gigabit.
Moreover, speed increments for Ethernet are typically more than 2x. “That would suggest an expectation for 1 Terabit Ethernet (TbE) or 1.6TbE speeds,” says Hull. This was the case with the bandwidth transition from 10GbE to 40GbE (4x), and 40GbE to 100GbE (2.5x).
“It would be unusual for Ethernet’s evolution to slow to a 2x rate and make 800 Gigabit Ethernet the next step,” says Hull. “The introduction of 112Gbps serdes allows for a doubling of input-output (I/O) on a per-physical interface but this is not the next Ethernet speed.”
Pluggable versus co-packaged optics
There is an ongoing industry debate as to when switch vendors will be forced to transition from pluggable optics on the front panel to photonics co-packaged with the switch ASIC.
The issue is that with each doubling of switch chip speed, it becomes harder to get the data on and off the chip at a reasonable cost and power consumption. Driving the ever faster signals from the chip to the front-panel optics is also becoming challenging.
Packaging the optics with the switch chip enables the high-speed serialiser-deserialiser (serdes), the circuitry that gets data on and off the chip, to be simplified; no longer will the serdes need to drive high-speed signals across the printed circuit board (PCB) to the front panel. Adopting co-packaged optics simplifies the PCB design, constrains the switch chip’s overall power consumption given how hundreds of serdes are used, and reduces the die area reserved for the serdes.
But transitioning to co-packaged optics represents a significant industry shift.
The consensus at a panel discussion at the OFC show, held in March, entitled Beyond 400G for Hyperscaler Data Centres, was that the use of front-panel pluggable optics will continue for at least two more generations of switch chips: at 25.6Tbps and at 51.2Tbps.
It is a view shared by the 800G Pluggable MSA and one of its motivating goals.
“The MSA believes that 800-gigabit pluggables are technically feasible and offer clear benefits versus co-packaging,” says Kuschnerov. “As long as the industry can support pluggables, this will be the preferred choice of the data centre operators.”
It has always paid off to bet on the established technology as long as it is technically feasible due to the sheer amount of investment already made, says Kuschnerov.
Major shifts in interconnects such as coherent replacing direct detect, or PSM/ CWDM pushing out VCSELs, or optics replacing copper have happened only when legacy technologies approach their limits and which can’t be overcome easily, he says: “We don’t believe in such fundamental limitations for 800-gigabit pluggables.”
So when will the industry adopt co-packaged optics?
“We believe that beyond 51.2Tbps there is a very high risk surrounding the serdes and thus co-packaging might become necessary to overcome this limitation,” says Kuschnerov.
Switch-chip-maker, Broadcom, has said that co-packaged optics will be adopted alongside pluggables, enabling the hyperscalers to lessen the risk of the new technology’s introduction. Broadcom believes that co-packaged optics solutions will appear as early as the advent of 25.6-terabit switch chips.
An earlier transitional introduction is also a view shared by Hugo Saleh, vice president of marketing and business development at silicon photonics specialist at Ayar Labs, which recently unveiled its optical I/O chiplet technology is being co-packaged with Intel’s Stratix 10 FPGA.
Saleh says the consensus is that the node past 51.2Tbps must use in-packaged optics. But he also expects overlap before then, especially for high-end and custom solutions.
“It [co-packaged optics] is definitely coming, and it is coming sooner than some folks expect,” says Saleh.
Several companies have contacted the MSA since its 800-gigabit announcement. The 800G MSA is also in discussion with several component and module vendors that are about to join, from Asia and elsewhere. Inphi and Lumentum have joined since the MSA was announced.
Discussions have started with system vendors and hyperscale data center operators; Baidu is one that has since signed up.

Arista adds coherent CFP2 modules to its 7500 switch
 Martin Hull
Martin Hull
Several optical equipment makers have announced ‘stackable’ platforms specifically to link data centres in the last year.
Infinera’s Cloud Xpress was the first while Coriant recently detailed its Groove G30 platform. Arista’s announcement offers data centre managers an alternative to such data centre interconnect platforms by adding dense wavelength-division multiplexing (DWDM) optics directly onto its switch.
For customers investing in an optical solution, they now have an all-in-one alternative to an optical transport chassis or the newer stackable data centre interconnnect products, says Martin Hull, senior director product management at Arista Networks. Insert two such line cards into the 7500 and you have 12 ports of 100 gigabit coherent optics, eliminating the need for the separate optical transport platform, he says.
The larger 11RU 7500 chassis has eight card slots such that the likely maximum number of coherent cards used in one chassis is four or five - 24 or 30 wavelengths - given that 40 or 100 Gigabit Ethernet client-side interfaces are also needed. The 7500 can support up to 96, 100 Gigabit Ethernet (GbE) interfaces.
Arista says the coherent line card meets a variety of customer needs. Large enterprises such as financial companies may want two to four 100 gigabit wavelengths to connect their sites in a metro region. In contrast, cloud providers require a dozen or more wavelengths. “They talk about terabit bandwidth,” says Hull.
With the CFP2-ACO, the DSP is outside the module. That allows us to multi-source the optics
As well as the CFP2-ACO modules, the card also features six coherent DSP-ASICs. The DSPs support 100 gigabit dual-polarisation, quadrature phase-shift keying (DP-QPSK) modulation but do not support the more advanced quadrature amplitude modulation (QAM) schemes that carry more bits per wavelength. The CFP2-ACO line card has a spectral efficiency that enables up to 96 wavelengths across the fibre's C-band.
Did Arista consider using CFP coherent optical modules that support 200 gigabit, and even 300 and 400 gigabit line rates using 8- and 16-QAM? “With the CFP2-ACO, the DSP is outside the module,” says Hull. “That allows us to multi-source the optics.”
The line card also includes 256-bit MACsec encryption. “Enterprises and cloud providers would love to encrypt everything - it is a requirement,” says Hull. “The problem is getting hold of 100-gigabit encryptors.” The MACsec silicon encrypts each packet sent, avoiding having to use a separate encryption platform.
CFP4-ACO and COBO
As for denser CFP4-ACO coherent modules, the next development after the CFP2-ACO, Hull says it is still too early, as it is with for 400 gigabit on-board optics being developed by COBO and which is also intended to support coherent. “There is a lot of potential but it is still very early for COBO,” he says.
“Where we are today, we think we are on the cutting edge of what can be delivered on a line card,” says Hull. “Getting everything onto that line card is an engineering achievement.”
Future developments
Arista does not make its own custom ASICs or develop optics for its switch platforms. Instead, the company uses merchant switch silicon from the likes of Broadcom and Intel.
According to Hull, such merchant silicon continues to improve, adding capabilities to Arista’s top-of-rack ‘leaf’ switches and its more powerful ‘spine’ switches such as the 7500. This allows the company to make denser, higher-performance platforms that also scale when coupled with software and networking protocol developments.
Arista claims many of the roles performed by traditional routers can now be fulfilled by the 7500 such as peering, the exchange of large routing table information between routers using the Border Gateway Protocol (BGP). “[With the 7500], we can have that peering session; we can exchange a full set of routes with that other device,” says Hull.
"We think we are on the cutting edge of what can be delivered on a line card”
The company uses what it calls selective route download where the long list of routes is filtered such that the switch hardware is only programmed with the routes to be communicated with. Hull cites as an example a content delivery site that sends content to subscribers. The subscribers are typically confined to a known geographic region. “I don’t need to have every single Internet route in my hardware, I just need the routes to reach that state or metro region,” says Hull.
By having merchant silicon that supports large routing tables coupled with software such as selective route download, customers can use a switch to do the router’s job, he says.
Arista says that in 2016 and 2017 it will continue to introduce leaf and spine switches that enable data centre customers to further scale their networks. In September Arista launched Broadcom Tomahawk-based switches that enable the transition from 10 gigabit server interfaces to 25 gigabit and the transition from 40 to 100 gigabit uplinks.
Longer term, there will be 50 GbE and iterations of 400 and one terabit Ethernet, says Hull. And all this relates to the switch silicon. At present 3.2 terabit switch chips are common and already there is a roadmap to 6.4 and even 12.8 terabits by increasing both the chip’s pin count and using PAM-4 alongside the 25 gigabit signalling to double input/ output again. A 12.8 terabit switch may be a single chip, says Hull, or it could be multiple 3.2 terabit building blocks integrated together.
“It is not just a case of more ports on a box,” says Hull. “The boxes have to be more capable from a hardware perspective so that the software can harness that.”
Interconnection networks - an introduction
 Source: Jonah D. Friedman
Source: Jonah D. Friedman
If moving information between locations is the basis of communications, then interconnection networks represent an important subcategory.
The classic textbook, Principles and Practices of Interconnection Networks by Dally and Towles, defines interconnection networks as a way to transport data between sub-systems of a digital system.
The digital system may be a multi-core processor with the interconnect network used to link the on-chip CPU cores. Since the latest processors can have as many as 100 cores, designing such a network is a significant undertaking.
Equally, the digital system can be on a far larger scale: servers and storage in a data centre. Here the interconnection network may need to link as many as 100,000 servers, as well as the servers to storage.
The number of servers being connected in the data centre continues to grow.
“The market simply demands you have more servers,” says Andrew Rickman, chairman and CEO of UK start-up Rockley Photonics. “You can’t keep up with demand simply with the advantage of [processors and] Moore’s law; you simply need more servers.”
Scaling switches
To understand why networking complexity grows exponentially rather than linearly with server count, a simple switch scaling example is used.
With the 4-port switch shown in Figure 1 it is assumed that each port can connect to the any of the other three ports. The 4-port switch is also non-blocking: if Port 1 is connected to Port 3, then the remaining input and output can also be used without affecting the link between ports 1 and 3. So, if four servers are connected to the ports, each can talk to any other server as shown in Figure 1.
 Figure 1: A 4-port switch. Source: Gazettabyte, Arista Networks
Figure 1: A 4-port switch. Source: Gazettabyte, Arista Networks
But once five or more servers need to be connected, things get more complicated. To double the size to create an 8-port switch, several 4-port basic building switches are needed, creating a more complex two-stage switching arrangement (Figure 2).
 Figure 2: An 8-port switch made up of 4-port switch building blocks. Source: Gazettabyte, Arista Networks.
Figure 2: An 8-port switch made up of 4-port switch building blocks. Source: Gazettabyte, Arista Networks.
Indeed the complexity increases non-linearly. Instead of one 4-port building block switch, six are needed for a switch with twice the number of ports, with a total of eight interconnections (number of second tier switches multiplied by the number of first tier switches).
Doubling the number of effective ports to create a 16-port switch and the complexity more than doubles again: now three tiers of switching is needed, 20 4-port switches and 32 interconnections (See Table 1).
 Table 1: How the number of 4-port building block switches and interconnects grow as the number of switch ports keep doubling. Source: Gazettabyte and Arista Networks.
Table 1: How the number of 4-port building block switches and interconnects grow as the number of switch ports keep doubling. Source: Gazettabyte and Arista Networks.
The exponential growth in switches and interconnections is also plotted in Figure 3.
 Figure 3: The exponential growth in N-sized switches and interconnects as the switch size grows to 2N, 4N etc. In this example N=4. Source: Gazettabyte, Arista Networks.
Figure 3: The exponential growth in N-sized switches and interconnects as the switch size grows to 2N, 4N etc. In this example N=4. Source: Gazettabyte, Arista Networks.
This exponential growth in complexity explains Rockley Photonics’ goal to use silicon photonics to make a larger basic building block. Not only would this reduce the number of switches and tiers needed for the overall interconnection network but allow larger number of servers to be connected.
Rockley believes its silicon photonics-based switch will not only improve scaling but also reduce the size and power consumption of the overall interconnection network.
The start-up also claims that its silicon photonics switch will scale with Moore’s law, doubling its data capacity every two years. In contrast, the data capacity of existing switch ASICs do not scale with Moore’s law, it says. However the company has still to launch its product and has yet to discuss its design.
Data centre switching
In the data centre, a common switching arrangement used to interconnect servers is the leaf-and-spine architecture. A ‘leaf’ is typically a top-of-rack switch while the ‘spine’ is a larger capacity switch.
A top-of-rack switch typically uses 10 gigabit links to connect to the servers. The connection between the leaf and spine is typically a higher capacity link - 40 or 100 gigabit. A common arrangement is to adopt a 3:1 oversubscription - the total input capacity to the leaf switch is 3x that of its output stream.
To illustrate the point with numbers, a 640 gigabit top-of-rack switch is assumed, 480 gigabit (or 48 x10 Gig) capacity used to connect the servers and 160 gigabit (4 x 40 Gig) to link the top-of-rack switch to the spine switches.
In the example shown (Figure 4) there are 32 leaf and four spine switches connecting a total of 1,536 servers.
 Figure 4: An example to show the principles of a leaf and spine architecture in the data centre. Source: Gazettabyte
Figure 4: An example to show the principles of a leaf and spine architecture in the data centre. Source: Gazettabyte
In a data centre with 100,000 servers, clearly a more complicated interconnection scheme involving multiple leaf and spine clusters is required.
Arista Network’s White Paper details data centre switching and leaf-and-spine arrangements, while Facebook published a blog (and video) discussing just how complex an interconnection network can be (see Figure 5).
 Figure 5: How multiple leaf and spines can be connected in a large scale data centre. Source: Facebook
Figure 5: How multiple leaf and spines can be connected in a large scale data centre. Source: Facebook
Arista Networks embeds optics to boost 100 Gig port density
Arista Networks' latest 7500E switch is designed to improve the economics of building large-scale cloud networks.
The platform packs 30 Terabit-per-second (Tbps) of switching capacity in an 11 rack unit (RU) chassis, the same chassis as Arista's existing 7500 switch that, when launched in 2010, was described as capable of supporting several generations of switch design.

"The CFP2 is becoming available such that by the end of this year there might be supply for board vendors to think about releasing them in 2014. That is too far off."
Martin Hull, Arista Networks
The 7500E features new switch fabric and line cards. One of the line cards uses board-mounted optics instead of pluggable transceivers. Each of the line card's ports is 'triple speed', supporting 10, 40 or 100 Gigabit Ethernet (GbE). The 7500E platform can be configured with up to 1,152 10GbE, 288 40GbE or 96 100GbE interfaces.
The switch's Extensible Operating System (EOS) also plays a key role in enabling cloud networks. "The EOS software, run on all Arista's switches, enables customers to build, manage, provision and automate these large scale cloud networks," says Martin Hull, senior product manager at Arista Networks.
Applications
Arista, founded in 2004 and launched in 2008, has established itself as a leading switch player for the high-frequency trading market. Yet this is one market that its latest core switch is not being aimed at.
"With the exception of high-frequency trading, the 7500 is applicable to all data centre markets," says Hull. "That it not to say it couldn't be applicable to high-frequency trading but what you generally find is that their networks are not large, and are focussed purely on speed of execution of their transactions." Latency is a key networking performance parameter for trading.
The 7500E is being aimed at Web 2.0 companies and cloud service providers. The Web 2.0 players include large social networking and on-line search companies. Such players have huge data centres with up to 100,000 servers.
The same network architecture can also be scaled down to meet the requirements of large 'Fortune 500' enterprises. "Such companies are being challenged to deliver private cloud as the same competitive price points as the public cloud," says Hull.
The 7500 switches are typically used in a two-tier architecture. For the largest networks, 16 or 32 switches are used on the same switching tier in an arrangement known as a parallel spine.
A common switch architecture for traditional IT applications such as e-mail and e-commerce uses three tiers of switching. These include core switches linked to distribution switches, typically a pair of switches used in a given area, and top-of-rack or access switches connected to each distribution pair.
For newer data centre applications such as social networking, cloud services and search, the computation requirements result in far greater traffic shared on the same tier of switching, referred to as east-west traffic. "What has happened is that the single pair of distribution switches no longer has the capacity to handle all of the traffic in that distribution area," says Hull.
Customers address east-west traffic by throwing more platforms together. Eight or 16 distribution switches are used instead of a pair. "Every access switch is now connected to each one of those 16 distribution switches - we call them spine switches," says Hull.
The resulting two-tier design, comprising access switches and distribution switches, requires that each access switch has significant bandwidth between itself and any other access switch. As a result, many 7500 switches - 16 or 32 - can be used in parallel at the distribution layer.
 Source: Arista Networks
Source: Arista Networks
"If I'm a Fortune 500 company, however, I don't need 16 of those switches," says Hull. "I can scale down, where four or maybe two [switches] are enough." Arista also offers a smaller 4-slot chassis as well as the 8 slot (11 RU) 7500E platform.
7500E specification
The switch has a capacity of 30Tbps. When the switch is fully configured with 1,152 10GbE ports, it equates to 23Tbps of duplex traffic. The system is designed with redundancy in place.
"We have six fabric cards in each chassis," says Hull, "If I lose one, I still have 25 Terabits [of switching fabric]; enough forwarding capacity to support the full line rates on all those ports." Redundancy also applies to the system's four power supplies. Supplies can fail and the switch will continue to work, says Hull.
The switch can process 14.4 billion 64-byte packets a second. This, says Hull, is another way of stating the switch capacity while confirming it is non-blocking.
The 7500E comes with four line card options: three use pluggable optics while the fourth uses embedded optics, as mentioned, based on 12 10Gbps transmit and 12 10Gbps receive channels (see table).

Using line cards supporting pluggable optics provides the customer the flexibility of using transceivers with various reach options, based on requirements. "But at 100 Gigabit, the limiting factor for customers is the size of the pluggable module," says Hull.
Using a CFP optical module, each card supports four 100Gbps ports only. The newer CFP2 modules will double the number to eight. "The CFP2 is becoming available such that by the end of this year there might be supply for board vendors to think about releasing them in 2014," says Hull. "That is too far off."
Arista's board mounted optics delivers 12 100GbE ports per line card.
The board-mounted triple-speed ports adhere to the IEEE 100 Gigabit SR10 standard, with a reach of 150m over OM4 fibre. The channels can be used discretely for 10GbE, grouped in four for 40GbE, while at 100GbE they are combined as a set of 10.
"At 100 Gig, the IEEE spec uses 20 out of 24 lanes (10 transmit and 10 receive); we are using all 24," says Hull. "We can do 12 10GbE, we can do three 40GbE, but we can still only do one 100Gbps because we have a little bit left over but not enough to make another whole 100GbE." In turn, the module can be configured as two 40GbE and four 10GbE ports, or 40GbE and eight 10GbE.
Using board-mounted optics reduces the cost of 100Gbps line card ports. A full 96 100GbE switch configuration achieves a cost of $10k/port while using existing CFP modules the cost is $30k-50k/ port, claims Arista.
Arista quotes 10GbE as costing $550 per line card port not including the pluggable transceiver. At 40GbE this scales to $2,200. For 100GbE the $10k/ port comprises the scaled-up port cost at 100GbE ($2.2k x 2.5) to which is added the cost of the optics. The power consumption is under 4W/ port when the system is fully loaded.
The company uses merchant chips rather than an in-house ASIC for its switch platform. Can't other vendors develop similar performance systems based on the same ICs? "They could, but it is not easy," says Hull.
The company points out that merchant chip switch vendors use a CMOS process node that is typically a generation ahead of state-of-the-art ASICs. "We have high-performance forwarding engines, six per line card, each a discrete system-on-chip solution," says Hull. "These have the technology to do all the Layer 2 and Layer 3 processing." All these devices on one board talk to all the other chips on the other cards through the fabric.
In the last year, equipment makers have decided to bring silicon photonics technology in-house: Cisco Systems has acquired Lightwire while Mellanox Technologies has announced its plan to acquire Kotura.
Arista says it is watching silicon photonics developments with keen interest. "Silicon photonics is very interesting and we are following that," says Hull. "You will see over the next few years that silicon photonics will enable us to continue to add density."
There is a limit to where existing photonics will go, and silicon photonics overcomes some of those limitations, he says.
Extensible Operating System
Arista's highlights several characteristics of its switch operating system. The EOS is standards-compliant, self-healing, and supports network virtualisation and software-defined networking (SDN).
The operating system implements such protocols as Border Gateway Protocol (BGP) and spanning tree. "We don't have proprietary protocols," says Hull. "We support VXLAN [Virtual Extensible LAN] an open standards way of doing Layer 2 overlay of [Layer] 3."
EOS is also described as self-healing. The modular operating system is composed of multiple software processes, each process described as an agent. "If you are running a software process and it is killed because it is misbehaving, when it comes back typically its work is lost," says Hull. EOS is self-healing in that should an agent need to be restarted, it can continue with its previous data.
"We have software logic in the system that monitors all the agents to make sure none are misbehaving," says Hull. "If it finds an agent doing stuff that it should not, it stops it, restarts it and the process comes back running with the same data." The data is not packet related, says Hull, rather the state of the network.
The operating system also supports network virtualisation, one aspect being VXLAN. VXLAN is one of the technologies that allows cloud providers to provide a customer with server resources over a logical network when the server hardware can be distributed over several physical networks, says Hull. "Even a VLAN can be considered as network virtualisation but VXLAN is the most topical."
Support for SDN is an inherent part of EOS from its inception, says Hull. “EOS is open - the customers can write scripts, they can write their own C-code, or they can install Linux packages; all can run on our switches." These agents can talk back to the customer's management systems. "They are able to automate the interactions between their systems and our switches using extensions to EOS," he says.
"We encompass most aspects of SDN," says Hull. "We will write new features and new extensions but we do not have to re-architect our OS to provide an SDN feature."
Arista is terse about its switch roadmap.
"Any future product would improve performance - capacity, table sizes, price-per-port and density," says Hull. "And there will be innovation in the platform's software.