

Mixx’s management team discusses its vision of reshaping AI infrastructure through silicon-integrated optical interconnects.
-
-
“Mixx, still in stealth mode, is developing an interconnect optimised for AI inferencing (tokens-per-second, latency, and power).
-
The start-up has developed a 25.6 terabit-per-second (Tbps) optical engine (chiplet) to enable large AI clusters.
-
Mixx raised $33 million in Series A funding in late 2025.
-
“When you’re stressed about closing your funding, you get horizontal lines,” Vivek Raghuraman, CEO and co-founder of Mixx Technologies, notes wryly, gesturing to his forehead. “Then, the lines go vertical because now we are focused on execution.”
It is a sentiment that will resonate with many start-up CEOs.
Founded in 2023, the San Jose-based company has set out to tackle the escalating data-movement bottleneck in AI clusters.
“At every layer of the AI, we are integrating photonics,” says Raghuraman. “The fundamental thesis for Mixx is mixing optics and electronics in a way that brings efficiency,” he says.
Interconnect challenge
AI training and inference workloads are increasingly limited not by compute but by data movement. Power-hungry electrical links, retimers, and multi-hop switch fabrics have latency and energy overheads, constraining the cluster’s size.
“The fundamental thesis for Mixx is mixing optics and electronics in a way that brings efficiency”
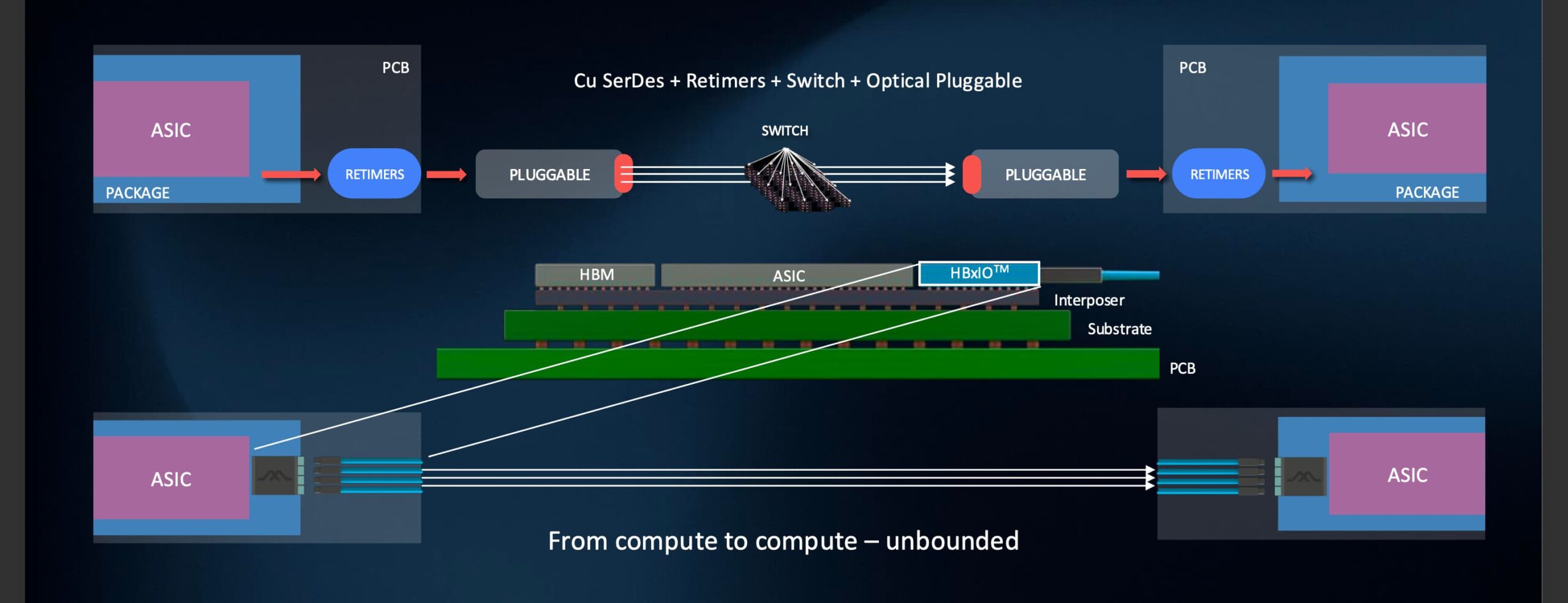
Mixx has developed its ‘HBxIO’ optical engine, a high-density input/output (I/O) chiplet that can be co-packaged with GPUs, custom AI accelerators and other chips such as network interface card controllers and switch chips.

The first-generation HBxIO delivers 25.6 Terabit-per-second (Tbps) of bi-directional bandwidth – 12.8Tbps in each direction – achieved using 200 gigabit-per-second optical lanes.
Bandwidth density is a key metric in advanced packaging where a die’s perimeter edges – its ’beachfront’ – used for I/O are highly valued.
Traditional electrical serial-deserialiser (serdes) interfaces occupy north/south edges of the ASIC, often the shorter edges (some 27mm). In contrast, the ASIC’s east/west beachfronts such as a GPU are used to interface to high-bandwidth memory (HBM).
Mixx’s focus is to achieve high densities by fitting more than 300 fibres across the 27mm die edge. Such density enables a high radix to connect many endpoints without intermediate switches.
“We can bring in more than 300 fibres, connecting at least 128 GPUs,” says Raghuraman, thereby reducing the number of hops between GPUs. “Today, the name of the game is increasing GPUs in a cluster in a way that all can operate as one large processing unit.”
Nvidia’s NVL72 rack, for example, uses 18 switches to connect 72 GPUs in a scale-up architecture. Mixx’s approach enables a switch-less or a minimal-switch cluster for latency-sensitive workloads. Indeed, using both chip edges, 256 GPUs can be connected.
Beyond that, system architects have flexibility: they can add optical or electrical switches for dynamic workloads, or extend to a multi-cluster across 500 meters.
“We’re providing the ability to create a switch-less cluster if latency is the primary goal of the workload,” says Rebecca Schaevitz, co-founder and chief product officer at Mixx. “But if you want dynamic workloads, and can accommodate the extra latency of a switch, you can connect a cluster of more than 4,000 GPUs using one layer of switches.”
The 500-meter limit stems from pragmatic engineering. “The reach can be provided by high-power lasers, while still being within the spectrum of what is available at the right cost and the right reliability,” says Raghuraman.
Pushing the reach further narrows the choice of viable lasers—a non-starter for hyperscalers prioritising supply-chain robustness.
Modulators and manufacturability
Mixx uses Mach-Zehnder interferometer modulators for its optical engine, rather than the compact ring resonators favoured by firms such as Ayar Labs and Nvidia.
Mach-Zehnder interferometers are bulkier, but Mixx says its design is optimised for high-density silicon photonics. “The Mach-Zehnders fit within that beachfront density,” says Raghuraman. “Bulkiness is all an artefact of how Mach-Zehnder in the past have been used in optical transceivers; we can leverage CMOS-scale technologies to bring effective performance.”
The Mach-Zehnder interferometer modulator also suits thermally sensitive environments such as next to GPUs while meeting interoperability and standards requirements.
The start-up is also claiming a 72 per cent reduction in a typical AI cluster’s power consumption. This stems from multiple factors. By enabling higher compute usage—reducing GPU idle time through faster data delivery—overall system power consumption drops. Eliminating retimers and signal-conditioning circuits also helps, reducing the link to 5 pJ/bit. “We are making it interoperable to standards,” he says.
Link-budget savings of nearly 4dB are achieved through optimised fibre connectivity—a core innovation. “Every dB saves power, whether on the laser or recovery circuits,” says Raghuraman.
This connectivity approach tackles manufacturability at semiconductor volumes. Mixx has developed a bottom-up solution to be compatible with semiconductor flows. The start-up highlights how it has eliminated optical epoxies and UV curing to survive 300°C+ assembly temperatures, while also maintaining optical alignment.
“We had to come up with a technology that works with the true semiconductor manufacturing ecosystem,” says Raghuraman. “We focused on what it takes to develop a solution that is truly manufacturable at scale.”
System-Level Thinking
Beyond hardware, Mixx has developed software, called GuardBand, that handles orchestration between GPUs. “How we enable this orchestration between the GPUs is all done by GuardBand, software that integrates with the network operating system that gives the controllability, observability, and all the telemetrics needed to manage the data movement within the cluster.”
The platform will support standard protocols at the fibre level- Ethernet, Ultra Ethernet, InfiniBand- while die-to-die interfaces can use UCIe or custom protocols. This ensures backwards compatibility and broad integration—whether for scale-up (massive single clusters), scale-out (distributed), scale-in (disaggregated memory/compute), or scale-across (long-reach).
Market dynamics
Mixx is using the funding round to accelerate engineering-sample delivery—primarily of the HBxIO chiplet—for customer integration into custom packages.
Company recruitment is also taking place, covering photonics, electronics, advanced packaging, and opto-mechanics. The company has over 50 staff in the US, Taiwan, and India.
Asked about the recent wave of optical interconnect acquisitions – Ciena acquiring Nubis, and Marvell’s just-completed acquisition of Celestial AI – Mixx’s view is AI interconnect is nascent. “There is no one technology that is going to be the solution,” says Raghuraman.
Tackling the issue from a system perspective rather than at the device level is what differentiates Mixx, says Raghuraman. “We thought about the system level, and then we are targeting building products that satisfy that system.”
AI inference demands underscore the start-up’s focus: low time-to-first-token and inter-token latency. “These two are the fundamentals that are going to be extremely critical for inference,” he says.
Schaevitz also notes that AI model developments, such as the adoption of a mixture-of-experts, mirror the human brain in having localised processing, yet like the brain, there is a need for a central database.
“That’s where connectivity is still going to grow,” says Schaevitz. “The more the ‘experts’ are scattered around, the more that this sloshing of data is important, because otherwise you’re waiting.”
Mixx will give a progress update at the upcoming OFC show in March. The company is working with select partners to build tier-one ecosystems that lower barriers to hyperscaler adoption.
“Most important for hyperscalers is the barrier to entry,” says Raghuraman. “We chose to solve one fundamental problem and leverage qualified technologies, where volume data is available.”
Mixx’s system, manufacturability, and efficiency-driven strategy aims to unlock the next phase of AI intelligence: large clusters with reduced power and latency that keep pace with evolving models.