
Neil McRae: What’s next for the telecom industry
In a talk at the FutureNet World conference, held in London on May 3-4, Neil McRae explains why he is upbeat about the telecoms industry’s prospects
Neil McRae is tasked with giving the final talk of the two-day FutureNet World conference.
“Yeah, I’m on the graveyard shift,” he quips.
McRae, the former chief network architect at BT, is now chief network strategist at Juniper Network.
The talk’s title is “What’s Next”, McRae’s take on the telecom industry and how it can grow.
McRae starts with how, as a 15-year-old, he had attended an Apple Macintosh computer event at a Novotel Hotel in Hammersmith, London, possibly even this one hosting this conference.
An Apple representative had asked for his feedback as a Macintosh programmer. McRae then listed all the shortfalls programming the PC. Later, he learnt that he had been talking to Steve Jobs.
Perhaps this explains his continual focus on customers and meeting their needs.
What customers care about, says McRae, is ‘new stuff’ that makes a difference in their lives. “Quite often in telecoms, we accidentally change the world without even thinking about it,” he says
McRae cites as an example using FaceTime to watch a newborn grandchild halfway across the world.
“We do it all the time; it is a phenomenal thing about our industry,” says McRae.
The Unvarnished Truth
McRae moves to showing several market and telco survey charts from IDC and Analysys Mason, what he calls ‘The unvarnished truth’.
The first slide shows how the European enterprise communication service market is set to grow at a compound annual growth rate (CAGR) of 3% between 2020 and 2025.
“Three per cent growth, who thinks that is a great business for telcos?” says McRae. “And enterprise is what we are all depending on for big growth and change because [the] consumer [market] is pretty much flat,” says McRae.
Another chart shows similar minimal growth: a forecast that Western Europe’s mobile retail service market will grow from $102 billion in 2016 to $109 billion by 2026. Yet mobile is where the telcos spend a ton of money, he says.
“So, who thinks we should continue doing what we are doing?” McRae asks the audience.
Another forecast showing global fixed and mobile service revenues is marginally better since it includes developing nations that still lack telecommunications services.
In the UK, 95 per cent of the population is on the internet, in Europe it is 84%, says McRae: “The UK is a tough place to be to grow business.”
Telco transformation
Another slide (see above), the results of a telco survey, shows a list of topics and their impact on telco transformation. McRae asks the audience to respond to those they think will ‘save’ the industry.
He goes through the list: cloud and cloudification, artificial intelligence (AI) and machine learning, 5G, and data analytics. The audience remains muted.
The next item is application programming interfaces (APIs). Again the audience is quiet. “You have been talking about APIs for two days!” says McRae.
“The right APIs,” shouts an audience member. “Ah, yes, the right APIs,” says McRae.
McRae continues down the list, virtualisation and software-defined infrastructure, OpenRAN elements – “not sure what the elements mean” – orchestration platforms, advanced process automation (OSS/BSS), micro-services, and blockchain.
McRae says he has spent the equivalent of a small nation’s budget over his career on OSS and BSS. “Nothing is automated, and I can’t get the data I need,” he says.
McRae gives his view. He believes the cloud will help telcos, but what most excites him is AI and machine learning, and data analytics.
“Learning the insights the data tells us and using them, putting a pound sign on them,” says McRae. “We have done some of that, but there is much more to do.”
He puts up a second survey showing the priorities of European operators: customer experience and increasing operational agility.
“Finally, after years, telcos realise that customers are important,” he says.
Opportunities
The survey also highlights the telcos’ belief that they can deliver solutions for industries and enterprise customers.
“This is a massive opportunity for telcos that allows us to grow revenues, create cool technology and hire amazing engineers,” says McRae.
The transformation needed in telecoms is about customers and taking risks with customers, he says.
One opportunity is digitalisation. McRae points outs that digitalisation is a process that never stops.
The three leading Chinese operators are keenly pursuing what they call industrial digitalisation or industrial internet. For China Telecom, industrial digitalisation now accounts for a quarter of its service revenues.
“Today, it is about cloud, cloud technologies, and smartphones, but tomorrow it could be about wearables or technology that is tracking what you are doing and making your life easier,” says McRae.
Digitalisation is an expertise that the telecom industry is not putting enough effort into, he says: “And as telcos, we have a massive right to play here.”
Another opportunity is AI and data, learning from the insights present in data to grow revenue.
“We have more data than most organisations, we haven’t used it very well, and we can build upon it,” says McRae, adding that AI needs the network to be valuable and improve our lives.
With data and AI, trust is vital. “If we are not trusted as an industry, we are dead,” says McRae. But because telcos are trusted entities, they can help other organisations improve trustworthiness.
Another opportunity is using the network for humans to interact in advanced ways. Since telecoms is a resource-heavy industry, such network-aided interaction would be immediately beneficial.
For this, what is needed is a cloud-native platform that integrates well with the network, and cloud platforms are generally poorly integrated with the network, he says.
He ends his talk by returning to customers and what they want: customers expect networks and services to be always present.
This explains the telcos’ continual marginal growth, he says: “The reason we have this is because there is a big chunk of customers’ lives where they can’t rely upon the network.”
Different thinking is needed if the network is to grow beyond the smartphone. Population coverage is not enough; what is needed is total coverage.
“Wherever I am, I want to use my device, to be connected, for the things that I don’t even know is doing stuff to be able to do them without worrying about connectivity,” he says.
And that is why 6G must be about 100 per cent connectivity,” says McRae: “Either we can do it, or someone else is going to.”
With that, FutureNet comes to ends, and McRae quickly departs to embark on the next chapter in his career. `
Neil McRae will be one of the speakers at the DSP Leaders World Forum, May 23-24, 2023.

Enfabrica’s chip tackles AI supercomputing challenges

- Enfabrica’s accelerated compute fabric chip is designed to scale computing clusters comprising CPUs and specialist accelerator chips.
- The chip uses memory disaggregation and high-bandwidth networking for accelerator-based servers tackling artificial intelligence (AI) tasks.
For over a decade, cloud players have packed their data centres with x86-based CPU servers linked using tiers of Ethernet switches.
“The reason why Ethernet networking has been at the core of the infrastructure is that it is incredibly resilient,” says Rochan Sankar, CEO and co-founder of Enfabrica.
But the rise of AI and machine learning is causing the traditional architecture to change.
What is required is a mix of processors: CPUs and accelerators. Accelerators are specialist processors such as graphics processing units (GPUs), programmable logic (FPGAs), and custom ASICs developed by the hyperscalers.
It is the accelerator chips, not the CPUs, that do the bulk of the processing. Accelerators also require vast data, creating challenging input-output (I/O) and memory requirements.
At Optica’s Executive Forum event, held alongside the OFC show in March, Ryohei Urata, director and principal engineer at Google, mentioned how Google uses two computing pods – comprising 6,000 TPU accelerators – to run its large language models.
A key concern for Google is scaling such clusters while ensuring their reliability and availability. It is critical that the system is available when running a large language model, says Urata,
“As an engineer, when you’re putting stuff down, at least when you’re first start to put it together, you think, okay, this is going to work perfectly,” says Urata. “This is a perfect design, you don’t factor in failing gracefully, so that’s a key lesson.”
Google’s concern highlights that accelerator-based clusters lack the reliability of data centre server-Ethernet networks.
Accelerated compute fabric
Start-up Enfabrica has developed a chip, dubbed the accelerated compute fabric, to scale computing clusters.
“The focus of Enfabrica is on how networking and fabric technologies have to evolve in the age of AI-driven computing,” says Sankar.
AI models are growing between 8x to 275x annually, placing enormous demands on a data centre’s computing and memory resources.
“Two hundred and seventy-five times are of the order of what the large language models are increasing by, 8x is more other models including [machine] vision; recommender models are somewhere in between,” says Sankar.
Another AI hardware driver is growing end-user demand; ChatGPT gained 100 million users in the first months after its launch.
Meeting demand involves cascading more accelerators but the I/O bandwidth connected to the compute is lagging. Moreover, that gap is growing.
Sankar includes memory bandwidth as part of the I/O issue and segments I/O scaling into two: connecting CPUs, GPUs, accelerators and memory in the server, and the I/O scaling over the network.
A computing architecture for AI must accommodate greater CPUs and accelerators yet tackle the I/O bottleneck.
“To scale, it requires disaggregation; otherwise, it becomes unsustainable and expensive, or it can’t scale enough to meet processing demands,” says Sankar
“Memory disaggregation represents the last step in server disaggregation, following storage and networking,” says Bob Wheeler, principal analyst at Wheeler’s Network.
Memory expansion through disaggregation has become more urgent as GPUs access larger memories for AI training, particularly for large language modules like ChatGPT, says Wheeler.
Rethinking data connectivity
In the data centre, servers in a rack are linked using a top-of-rack switch. The top-of-rack switch also connects to the higher-capacity leaf-spine Ethernet switching layers to link servers across the data centre.
Enfabrica proposes that the higher capacity Ethernet switch leaf layer talks directly to its accelerated compute fabric chip, removing the top-of-rack switch.
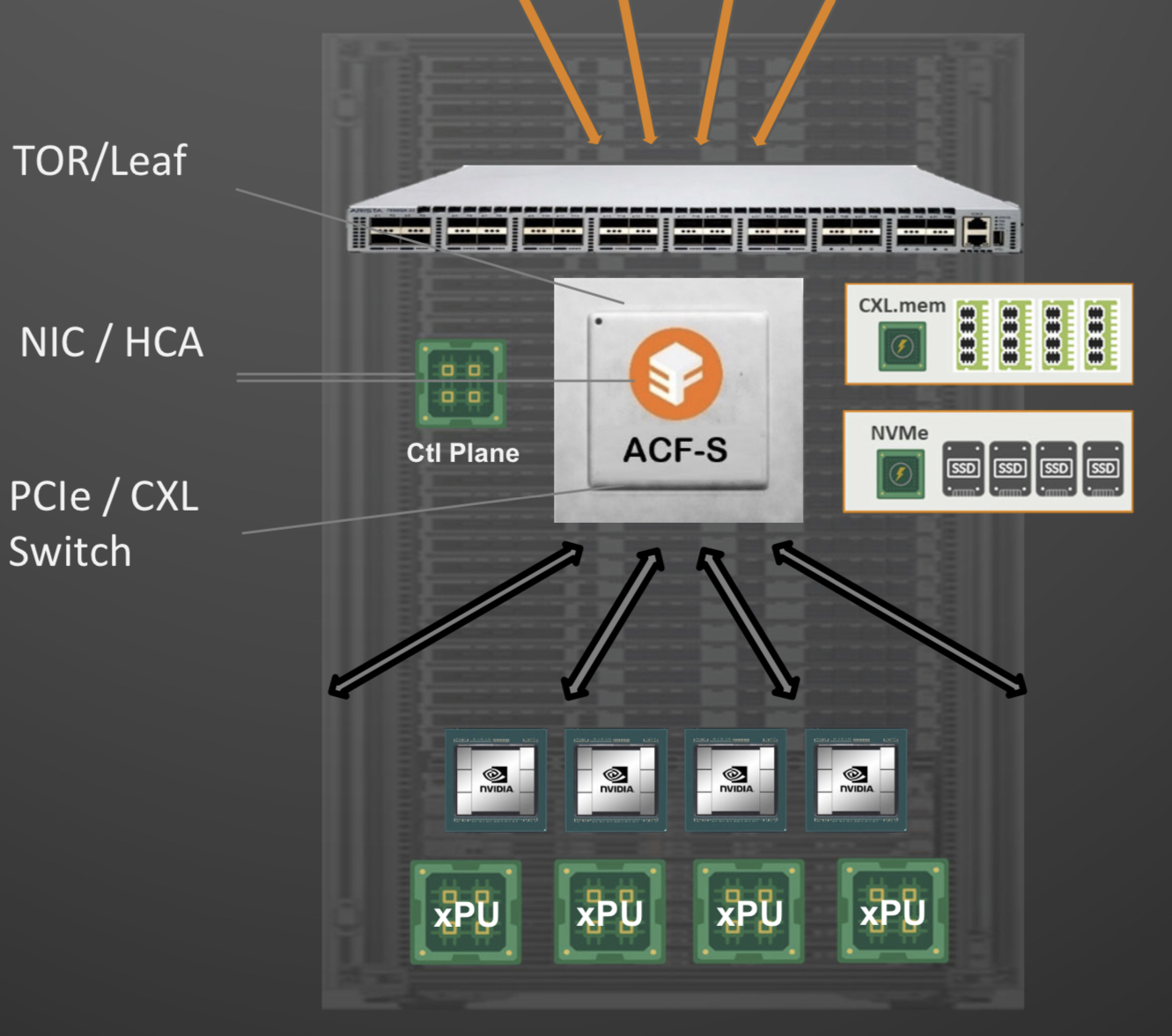
In turn, the accelerated compute fabric uses memory mapping to connect CPUs, accelerators, disaggregated memory pools using CXL, and disaggregated storage (see diagram above).
The memory can be a CPU’s DDR DRAM, a GPU’s high-bandwidth memory (HBM), a disaggregated compute express link (CXL) memory array, or storage.
“It [the accelerated compute fabric] connects to them over standard memory-mapped interfaces such as PCI Express (PCIe) or CXL,” says Sankar.
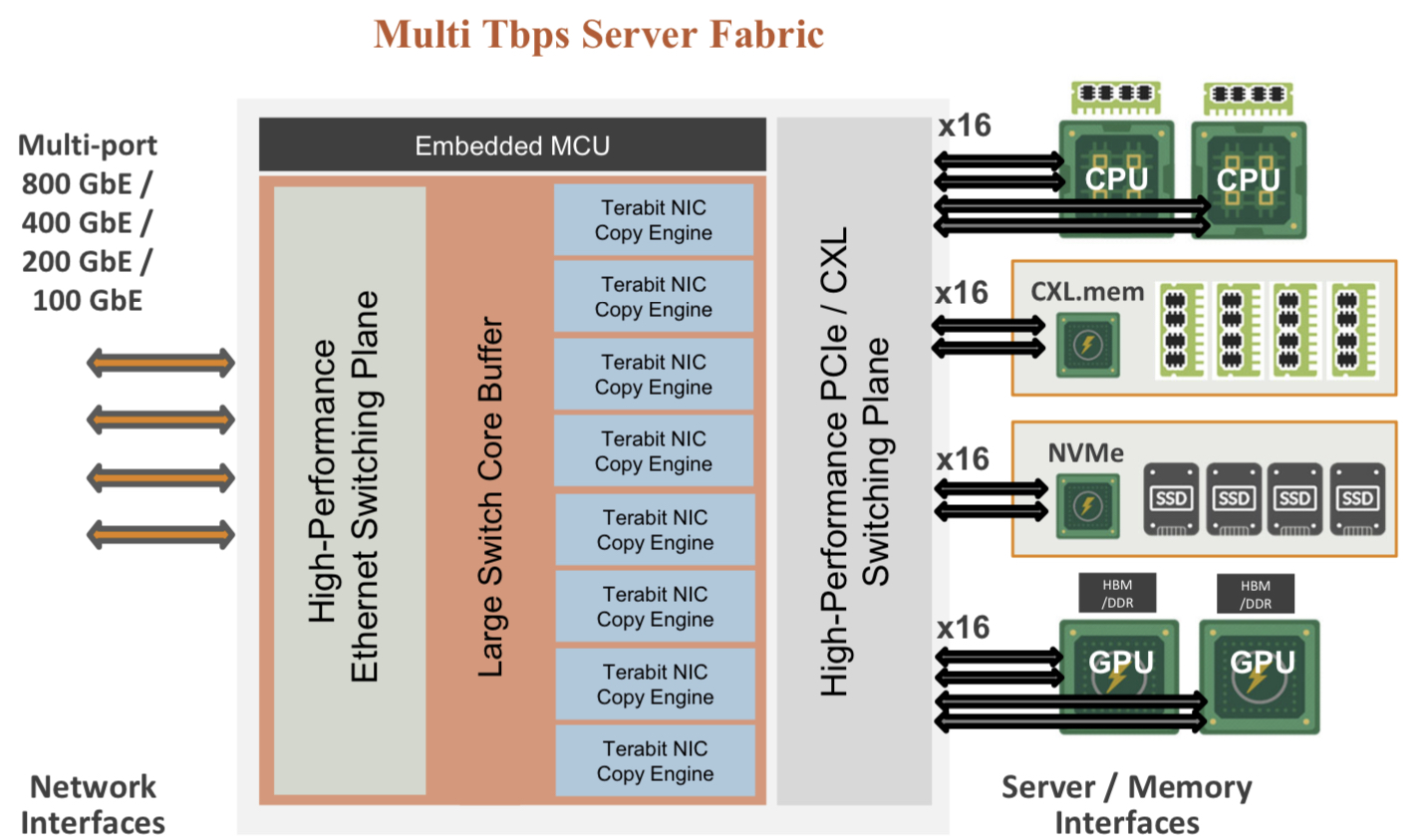
The chip uses ‘copy engines’ to move data to and from any processing element’s native memory. And by performing memory transfers in parallel, the chip is doing what until now has required PCIe switches, network interface cards (NICs), and top-of-rack switches.
The accelerated compute fabric also has 800-gigabit network interfaces so that, overall, the chip has terabits of bandwidth to move data across the network.
“CXL provides a standard way to decouple memories from CPUs, enabling DRAM disaggregation,” says Wheeler. “Enfabrica’s copy engines connect the GPUs to the pool of CXL memory. The network side, using RDMA (remote direct memory access), enables scaling beyond the limits of CXL.”
Sankar stresses that the accelerated compute fabric is much more than an integration exercise using an advanced 5nm CMOS process.
“If you were to integrate eight NICs, four PCIe switches and a top-of-rack switch, it would not fit into a single die,” says Sankar.
As for software, Enfabrica has designed its solution to fit in with how GPUs, CPUs and memory move data.
Significance
Sankar says the accelerated compute fabric IC will shorten job completion time because the scheduler is finer-grained and the chip can steer I/O to resources as required.
Computing clusters will also become larger using the IC’s high-density networking and CXL.
Wheeler says that CXL 3.x fabrics could provide the same capabilities as the accelerated compute fabric, but such advanced features won’t be available for years.
“History suggests some optional features included in the specifications will never gain adoption,” says Wheeler.
“The CXL/PCIe side of the [accelerated compute fabric] chip enables memory disaggregation without relying on CXL 3.x features that aren’t available, whereas the RNIC (RDMA NIC) side allows scaling to very large systems for workloads that can tolerate additional latency,” says Wheeler.
System benefits
Sankar cites two GPU platforms – one proprietary and one an open system – to highlight its chip benefits. The platforms are Nvidia’s DGX-H100 box and the open-design Grand Teton announced by Meta.
“The DGX has become a sort of fundamental commodity or a unit of AI computing,” says Shankar.
The DGX uses eight H100 GPUs, CPUs (typically two), I/O devices that link the GPUs using NVlink, and Infiniband for networking. The Meta platform has a similar specification but uses Ethernet.
Both systems have eight 400-gigabit interfaces. “That is 3.2 terabits coming out of the appliance, and inside the device, there is 3.2 terabit connected to a bunch of compute resources,” says Sankar.
The Meta platform includes layers of PCIe switches, and Open Compute Project (OCP 3.0) NICs running at 200 gigabits, going to 400 gigabits in the next generation.
The Grand Teton platform also uses eight NICs, four PCIe switches, and likely a top-of-rack switch to connect multiple systems.
Enfabrica’s vision is to enable a similarly composable [GPU] system. However, instead of eight NICs, four PCIe switches and the external top-of-rack switch, only three devices would be needed: two Enfabrica accelerated compute fabric chips and a control processor.
Enfabrica says the design would halve the power compared to the existing NICs, PCIe switches and the top-of-rack switch. “That represents 10 per cent of the rack’s power,” says Sankar.
And low-latency memory could be added to the space saved by using three chips instead of 12. Then, the eight GPUs would have tens of terabytes of memory to share whereas now each GPU has 80 gigabytes of HBM.
What next?
Enfabrica is unveiling the architecture first, and will detail its product later this year.
It is key to unveil the accelerated compute fabric concept now given how AI architectures are still nascent, says Sankar.
But to succeed, the start-up must win a sizeable data-centre customer such as a hyperscaler, says Wheeler: “That means there’s a very short list of customers, and winning one is paramount.”
The supplier must deliver high volumes from the start and guarantee supply continuity, and may also have to provide the source code to ensure that a customer can maintain the product under any circumstances.
“These are high hurdles, but Innovium proved it can be done and was rewarded with an exit at a valuation of greater than $1 billion,” says Wheeler.

OpenLight's CEO on its silicon photonics strategy
Adam Carter, recently appointed the CEO of OpenLight, discusses the company’s strategy and the market opportunities for silicon photonics.
Adam Carter’s path to becoming OpenLight’s first CEO is a circuitous one.
OpenLight, a start-up, offers the marketplace an open silicon photonics platform with integrated lasers and gain blocks.
Having worked at Cisco and Oclaro, which was acquired by Lumentum in 2018, Carter decided to take six months off. Covid then hit, prolonging his time out.
Carter returned as a consultant working with firms, including a venture capitalist (VC). The VC alerted him about OpenLight’s search for a CEO.
Carter’s interest in OpenLight was immediate. He already knew the technology and OpenLight’s engineering team and recognised the platform’s market potential.
“If it works in the way I think it can work, it [the platform] could be very interesting for many companies who don’t have access to the [silicon photonics] technology,” says Carter.
Offerings and strategy
OpenLight’s silicon photonics technology originated at Aurrion, a fabless silicon photonics start-up from the University of California, Santa Barbara.
Aurrion’s heterogeneous integration silicon photonics technology included III-V materials, enabling lasers to be part of the photonic integrated circuit (PIC).
Juniper Networks bought Aurrion in 2016 and, in 2022, spun out the unit that became OpenLight, with Synopsys joining Juniper in backing the start-up.
OpenLight offers companies two services.
The first is design services for firms with no silicon photonics design expertise. OpenLight will develop a silicon photonics chip to meet the company’s specifications and take the design to production.
“If you don’t have a silicon photonics design team, we will do reference architectures for you,” says Carter.
The design is passed to Tower Semiconductor, a silicon photonics foundry that OpenLight, and before that, Juniper, worked with. Chip prototype runs are wafer-level tested and passed to the customer.
OpenLight gives the company the Graphic Data Stream (GDS) file, which defines the mask set the company orders from Tower for the PIC’s production.
OpenLight also serves companies with in-house silicon photonics expertise that until now have not had access to a silicon photonics process with active components: lasers, semiconductor optical amplifiers (SOAs), and modulators.
The components are part of the process design kit (PDK), the set of files that models a foundry’s fabrication process. A company can choose a PDK that best suits its silicon photonics design for the foundry to then make the device.
OpenLight offers two PDKs via Tower Semiconductor: a Synopsys PDK and one from Luceda Photonics.
OpenLight does not make components, but offers reference designs. OpenLight gets a small royalty with every wafer shipped when a company’s design goes to production.
“They [Tower] handle the purchasing orders, the shipments, and if required, they’ll send it to the test house to produce known good die on each wafer,” says Carter
OpenLight plans to expand the foundries it works with. “You have to give customers the maximum choice,” says Carter.
Design focus
OpenLight’s design team continues to add components to its library.
At the OFC show in March, held in San Diego, OpenLight announced a 224-gigabit indium phosphide optical modulator to enable 200-gigabit optical lanes. OpenLight also demoed an eight-by-100-gigabit transmitter alongside Synopsys’s 112-gigabit serialiser-deserialiser (serdes).
OpenLight also offers a ‘PDK sampler’ for firms to gain confidence in its process and designs.
The sampler comes with two PICs. One PIC has every component offered in OpenLight’s PDK so a customer can probe and compare test results with the simulation models of Tower’s PDKs.
”You can get confidence that the process and the design are stable,” says Carter.
The second PIC is the eight by 100 gigabit DR8 design demoed at OFC.
The company is also working on different laser structures to improve the picojoule-per-bit performance of its existing design.
“Three picojoules per bit will be the benchmark, and it will go lower as we understand more about reducing these numbers through design and process,” says Carter.
The company wants to offer the most updated components via its PDK, says Carter.
OpenLight’s small design team can’t do everything at once, he says: “And if I have to license other people’s designs into my PDK, I will, to make sure my customer has a maximum choice.”
Market opportunities
OpenLight’s primary market focus is communications, an established and significant market that will continue to grow in the coming years.
To that can be added artificial intelligence (AI) and machine learning, memory, and high-speed computing, says Carter.
“If you listen to companies like Google, Meta, and Amazon, what they’re saying is that most of their investment in hardware is going into what is needed to support AI and machine learning,” says Carter. “There is a race going on right now.”
When AI and machine learning take off, the volumes of optical connections will grow considerably since the interfaces will not just be for networking but also computing, storage, and memory.
“The industry is not quite ready yet to do that ramp at the bandwidths and the densities needed,” he says, but this will be needed in three to four years.
Large contract manufacturers also see volumes coming and are looking at how to offer optical subassembly, he says.
Another market opportunity is telecoms and, in particular coherent optics for metro networks. However, unit volumes will be critical. “Because I am in a foundry, at scale, I have to fill it with wafers,” says Carter.
Simpler coherent designs – ‘coherent lite’ – connecting data centre buildings could be helpful. There is much interest in short-reach connections, for 10km distances, at 1.6 terabit or higher capacity where coherent could be important and deliver large volumes, he says.
Emerging markets for OpenLight’s platform include lidar, where OpenLight is seeing interest, high-performance computing, and healthcare.
“Lidar is different as it is not standardised,” he says. It is a lucrative market, given how the industry has been funded.
OpenLight wants to offer lidar companies early access to components that they need. Many of these companies have silicon photonics design teams but may not have the actives needed for next-generation products, he says.
“I have a thesis that says everywhere a long-wavelength single-mode laser goes is potential for a PIC,” says Carter
Healthcare opportunities include a monitoring PIC placed on a person’s wrist. Carter also cites machine vision, and cell phone makers who want improved camera depth perception in handsets.
Carter is excited by these emerging silicon photonics markets that promise new incremental revenue streams. But timing will be key.
“We have to get into the right market at the right time with the right product,” says Carter. “If we can do that, then there are opportunities to grow and not rely on one market segment.”
As CEO, how does he view success at OpenLight?
“The employees here, some of whom have been here since the start of Aurrion, have never experienced commercial success,” says Carter. “If that happens, and I think it will because that is why I joined, that would be something I could be proud of.”

Marvell’s CTO: peering into the future is getting harder
CTO interviews part 4: Noam Mizrahi
In a wide-ranging interview, Noam Mizrahi (pictured), executive vice president and corporate chief technology officer (CTO) at Marvell, discusses the many technologies needed to succeed in the data centre. He also discusses a CTO’s role and the importance of his focussed thinking ritual.
Noam Mizrahi has found his calling.
“I’m inspired by technology,” he says. “Every time I see an elegant technical solution – and it can be very simple – it makes me smile.”
Marvell hosts an innovation contest, and at one event, Mizrahi mentioned this to participants. “So they issued stickers saying, ‘I made Noam smile’,” he says.
Marvell’s broad portfolio of products spans high-end processors, automotive Ethernet, storage, and optical modules.
“This technology richness means that every day I come to work, I feel I learn something new,” he says.
Chip design
The interview with Mizrahi occurred before the passing away on March 24th of Gordon Moore, aged 94, who co-founded Intel.
In his article published in Electronics in 1965, Moore observed how chip transistor count doubled roughly yearly, what became known as Moore’s law.
The law has driven the semiconductor industry for decades and, like all exponential trends, is reaching its limit.
Since Marvell’s business is infrastructure ICs, it is experiencing the law’s demise first hand.
While the core definition of Moore’s law is ending, technology and process advancement are still enabling the cramming of more transistors on a die, says Mizrahi. However, greater processing performance and lower power consumption are occurring at a different pace and cost structure.
It is now very costly to make chips using the latest 5nm and 3nm CMOS process nodes.
The cost is not just the chip mask (reticle) but also such aspects as intellectual property (IP), architecture, design verification, electronics design automation (EDA) tools, and design validation.
Getting to the first product using 5nm CMOS can cost as high as $450 million, while for 3nm, the estimate is $600 million.
Also, development flow takes longer due to the complexity involved and will cause a redefinition of what is meant by a ‘current generation’ of a chip, says Mizrahi.
Design reuse is also increasingly required; not just reusing IP but the validation process in order to speed up a chip’s introduction.
In turn, designers must be innovative since processing performance and lower power consumption are harder to achieve.
Areas include package design optimisation, chip input-output (I/O), and the software to claw back processing performance that previously came from using the latest CMOS process.
IC designers will also be forced to choose which chips to make using the latest CMOS process node.
Overall, fewer chip companies will be able to afford chips made in leading CMOS processes, and fewer companies will buy such ICs, says Mizrahi.
Rise of chiplets
Chiplets will also play a role in a post-Moore’s law world.
“Chiplets are currently a very hot topic,” says Mizrahi.

A chiplet is a die implementing a functional block. The chiplet is added alongside a central die for a system-on-chip (SoC) design. Using chiplets, designs can exceed the theoretical limit of the mask size used to make a chip.
Marvell has long been a chiplet pioneer, says Mizrahi. “Today, it all seems reasonable, but when we did all that, it was not so obvious.” Marvell makes one chip that has 17 dies in a package.
Chiplets are particularly suited for artificial intelligence (AI) ASICs, what Mizrahi describes as ‘monsters of chips’.
Chiplets enable designers to control yield, which is essential when each 3nm CMOS chip lost to a defect is so costly.
Using chiplets, a design can be made using a mix of CMOS process nodes, saving power and speeding up a chip’s release.
Mizrahi applauds the work of the Universal Chiplet Interconnect Express (UCIe) organisation, creating chiplet standards.
But the chiplets’ first use will be as internally-designed dies for a company’s product, he says. Chip designers buying best-in-class chiplets from third parties remains some way off.
A CTO’s role
Mizrahi’s role is to peer into the future to identify the direction technologies will take and their impact on Marvell’s markets and customers.
He says a company-level longer-term technological strategy that combines the strengths of Marvell’s product lines is needed to secure the company’s technical lead.
“That is my job, and I love it,” he says.
It’s also challenging; predicting the future is hard, especially when the marketplace is dynamic and constantly changing. Technology is also very costly and time-consuming to develop.
“So, making the right decision as to what technology we need to invest in for the future, that is tough,” says Mizrahi.
Rapidly changing market dynamics are also challenging Marvell’s customers, who don’t always know what they need to do.
“Creating this clarity with them is challenging but also a great opportunity if done correctly,” says Mizrahi. “That is what keeps me motivated.”
Job impact
How does Mizrahi, Marvell’s CTO since 2020, assess his impact?
The question stems from a comment by Coherent’s Dr Julie Eng that assessing a CTO’s impact is more complicated than, say, a product line manager’s. On becoming CTO, Eng discussed with Coherent’s CEO how best to use her time to benefit the company. She also called other CTOs about the role and what works for them.
“I would say that my goals are tangible and clear, but the environment and the topics that I deal with are far less tangible and clear,” says Mizrahi.
He is required to identify technology trends and determine which ones need to be ’intercepted’. “What do we need to do to get there and ensure that we have the right technologies in place,” he says.
But how technologies play out is hard to determine and becoming harder given the longer development cycles.
“It’s critical to identify these technologies and their impact ahead of time to give yourself enough time to prepare for what must be done, so you can start the development in time for when the wave hits.”
Marvell’s strategy
Marvell’s company focus is infrastructure IC.
“We deal with the network, connectivity, storage, security, all the infrastructure around the processor,” says Mizrahi.
Marvell has been acquiring companies to bolster its technology portfolio and system expertise. The acquisitions include Cavium, Inphi, and Innovium. Last year, Marvell also bought CXL specialist Tanzanite Silicon Solutions.
“It’s going to be very important that you possess all the components in the infrastructure because, otherwise, it is tough to design a solution that brings value,” says Mizrahi.
Being able to combine all the pieces helps differentiate a company.
“I’m not sure there are many other companies that possess all the components needed to make effective infrastructure,” he says.
Disaggregation
Mizrahi gave a talk at Marvell’s Industry Analyst Day last December entitled Disaggregation using Optics.
During the talk, he described how data centres have been flexible enough to absorb new use cases and applications in the past, but now this is changing.
“AI training clusters are going to require a different type of data centre,” says Mizrahi. “It is more like a supercomputer, not the same traditional server architecture we see today.”
His analyst day talk also highlighted the need to disaggregate systems to meet the pace of scaling required and remove dependencies between components so they can be disaggregated and scaled independently.
Compute Express Link (CXL) and memory is one such component disaggregation example.
The CXL protocol optimises several memory parameters in computing systems, namely latency, bandwidth, and memory semantics. Memory semantics is about overseeing correct access by several devices using a shared memory.
CXL enables the disaggregation of memory currently bound to a host processor, thereby not only optimising the performance metrics but reducing overall cost.
Mizrahi cites the issue of poor memory usage in data centres. Microsoft Azure issued research that showed half of its virtual machines never touch half the memory.
“This means that memory is stranded when virtual machines are rented and are unavailable to other users,” says Mizrahi. “And memory is one of the largest spends in data centres.”
CXL enables memory pooling. From this pool, memory is assigned to an application in real time and released when workload execution is completed.
Pooled memory promises to save hyperscalers hundreds of millions of dollars.
“Of course, it’s not easy to do, and it will take time, but that’s just one motivation for doing things [using CXL].”
His analyst talk also stated how optics is the one media that addresses all the disaggregation issues: bandwidth, power, density, and the need for larger clusters.
“We’re going to see an all-optical type of connectivity if you look far enough into the future,” he says. “Of course, not today and not tomorrow.”
Mizrahi’s talk also suggested that AI will need even larger scale computing than supercomputers.
He cites Tesla’s supercomputer used to train its autonomous vehicle neural network.
“If you look at what it is composed of, it is a supercomputer,” says Mizrahi. “Some say it’s one of the top five or top 10 supercomputers, and its only purpose is to train autonomous vehicle neural networks.”
Last year, Meta also announced a supercomputer for training purposes.
Such AI training systems are the tip of the iceberg, he says.
“Ask yourself, what is a unit for a training cluster,“ says Mizrahi. “Is it eight GPUs (graphics processing units), 256 GPUs, 4k TPUs (tensor processing units), or maybe it is an entire data centre in one cluster?”
That is where it is all going, he says.
Pluggable modules and co-packaged optics
Co-packaged optics continues to evolve, but so are standard pluggable modules.
There is a good reason why pluggable optics remain in favour, and that will continue, says Mizrahi. But at some point, designers won’t have a choice, and co-packaged optics will be needed. That, however, is some way off.
In time, both these technologies will be used in the data centre.
Co-packaged optics is focussed on high-capacity networking switches. “And we are right in the middle of this and developing into it,” says Mizrahi.
Another place where co-packaged optics will be used, potentially even sooner, is for AI clusters.
Such co-packaged optics will connect switches to compose AI clusters, and, longer term, the GPUs will use optical I/O as their primary interface.
Such optical I/O helps meet bandwidth, power reduction, and power density requirements.
“Let’s say you want to build a cluster of GPUs, the larger the cluster, the better, but these are so power-hungry. If you do it with electrical connectivity, you must maintain proximity to achieve high speeds,” says Mizrahi. “But that, of course, limits your ability to put more GPUs into a cluster because of power density limitations.”
Using optical I/O, however, somewhat eases the density requirement, enabling more GPUs in a cluster.
But there are issues. What happens if something fails?
Today, with pluggables, one link is affected, but with co-packaged optics, it is less simple. “Also how do you scale production of these things to the scale of a data centre?” says Mizrahi.
These questions will ensure the coexistence of these different solutions, he says.
But AI is driving the need for the newer technology. Mizrahi cites how, in data centres, high-end switches have a capacity of 25 terabits while servers use a 50-gigabit interface. “That means, if for simplicity we ignore topologies and redundancies, you can connect 500 servers to that switch,” he says.
GPUs today have a 3.6 terabit-per-second full duplex I/O connectivity to talk to their peer GPUs.
“It only takes seven GPUs to saturate that very same [25.6-terabit capacity] switch,” he says. “The bandwidth requirement, it just explodes, and it’s going to be very hard to keep doing that electrically.”
This is why co-packaged optics will be needed.
Typical workday
Mizrahi is based in Israel, whereas Marvell’s headquarters is in Santa Clara, California.
“It [Israel] is the centre of my life and where my family is,” says Mizrahi. “I travel a lot, to the point where I think my biological clock is somewhere over the ocean.”
His day spreads across many time zones. Early morning calls are to the Far East before he turns to local issues. Then, his afternoon coincides with morning US Eastern time, while his evening aligns with morning US Western time.
That said, Marvell’s CEO repeatedly emphasises his desire for all employees to balance work and family.
“He encourages and insists to see that happen, which helps me keep a balance,” says Mizrahi.
Prime focus time
Mizrahi loves sports and is a keen runner.
He ensures he does not miss his seven or eight-mile daily run, even on days when he has a long flight.
“Every morning, it is my alone time,” he says. “It’s when I let my brain work, and it is my prime focus time.”
He is also a family man and has three children. He is keen to spend as much time as possible with his wife and kids.
“It’s not going to be long before they [the children] start their journey away from home, so I try to cherish every minute I have with them,“ he says.
He reads a lot, including technical material. “I told you, I’m inspired by technology.”

He cites two recently read books.
One, in Hebrew, is called Red Skies by Daniel Shinar.
“It talks about a friendship between two young guys from two sides of the fence,” he says. A friendship that proves impossible due to the reality of the situation.
The second book, one he found fascinating and meaningful, was part of a training course given at Marvell, called The Leadership Challenge by James Kouzes and Barry Posner.
“It gives you practices that the authors see as key for exemplary leadership, and it gave me so many things to think about,” he says. “To recognise things in my behaviour or other people, I view as leaders.”

How DSP smarts continue to improve optical transport
- Kim Roberts explains the signal processing techniques Ciena is using for its WaveLogic 6 coherent DSP.
- Roberts explains how the techniques squeeze, on average, a 15 per cent improvement in spectral efficiency.
- The WaveLogic 6 Extreme chip can execute 1,600 trillion (1.6 x 1015) operations per second and uses the equivalent of 4km of on-chip copper interconnect.
Part 2: WaveLogic 6’s digital signal processing toolkit
Bumping into Kim Roberts on the way to the conference centre at OFC, held in San Diego in March, I told him how, on the Ciena briefing about its latest WaveLogic 6 coherent digital signal processor (DSP), there had been insufficient time to dive deeply into the signal processing techniques used.
“What are you doing now?” said Roberts.
“I’m off to the plenary session to catch the keynotes.”
Chatting some more, I realised I was turning down a golden opportunity to sit down with a leading DSP and coherent modem architect.
“Is that offer still open?” I asked.
He nodded.
We grabbed a table at a nearby cafe and started what would prove to be an hour-long conversation.
High-end coherent DSPs
Many leading coherent modem vendors unveiled their latest designs in the run-up to the OFC show. It is rare for so many announcements to be aligned, providing a valuable glimpse of the state of high-performance optical transport.
Nokia announced its PSE-6s, which has a symbol rate of up to 130 gigabaud (GBd) and supports 1.2 terabit wavelengths. Infinera announced its 1.2-terabit ICE-7, which has a baud rate of up to 148GBd, while Fujitsu detailed it is using its 135GBd 1.2-terabit wavelength coherent DSP for its 1FINITY Ultra optical platform.
Meanwhile, Acacia, a Cisco company, revealed its 140GBd Jannu 1.2-terabit DSP has been shipping since late 2022. Acacia announced the Jannu DSP in March 2022.
All these coherent DSPs are implemented using 5nm CMOS and are shipping or about to.
And Ciena became the first company to detail a coherent DSP fabricated using a 3nm CMOS process. The WaveLogic 6 Extreme supports 1.6-terabit wavelengths and has a symbol rate of up to 200GBd.
Ciena’s WaveLogic 6 Extreme improves spectral efficiency by, on average, 15 per cent. WaveLogic 6 Extreme-based coherent modems will be available from the first half of 2024.
Customer considerations
Kim Roberts begins by discussing what customers want.
“With terrestrial systems, it is cost-per-bit [that matters], and if you’re not going very far, it is cost-per-modem,” says Roberts.
For the shortest reaches (tens of km), 100 gigabit may be enough while 200 gigabit or more is overkill. Here, a coherent pluggable module does the job.
“What matters is the cost per modem to get the flexibility of coherent connectivity so that you can plug it in and it works,” says Roberts.
With medium and long-haul terrestrial routes, cost-per-bit and heat-per-bit are the vital issues. With heat, area and volume of the coherent design are important. “I need volume to get the heat out of the chip on the card and into the air,” says Roberts.
Another use case is where spectral efficiency is key, for networks where fibre is scarce. An operator could be leasing dark fibre, or it could be a submarine network.
Ciena’s WaveLogic 6 Extreme’s 15 per cent improvement in spectral efficiency improves capacity over the same link. “Equivalently, you can go a dB (decibel) further or have a dB more signal margin,” says Roberts.
A common refrain heard is that spectral efficiency is no longer improving due to the Shannon limit being approached. Shannon’s limit is being approached because of the considerable progress already made by the industry in coherent optics.
“There is no 6dB to be had like in the old days,” says Roberts. “WaveLogic 3 was 2.5dB better than WaveLogic 2, but those multiple dBs are no longer there.”
The returns are diminishing, but striving for improvements remains worthwhile. “If you’re an operator that cares about spectral efficiency, that’s important,” he says.
Nonlinearity mitigation
Roberts returns to the issue of Shannon’s limit, based on the work of famed mathematician and information theorist, Claude Shannon.
“Shannon defines a theoretical limit for the capacity of a channel having linear propagation with additive Gaussian noise,” says Roberts.
This defines a strict mathematical limit, and it is pointless to go beyond that; he says: “In terms of linear performance, modems are getting close to the limit, within a couple of dB.”
Shannon’s limit doesn’t wholly define fibre since the channel is nonlinear.
Roberts says there is a whole research area addressing the bounds given such nonlinearities.
“We’re a long way from those theoretical nonlinear limits, but what matters is what’s the practical limit, and it’s getting hard,” he says
Increasing transmit power improves the optical signal-to-noise ratio (OSNR) and strengthens nonlinearities. Indeed, the nonlinearities grow faster with increased transmit power until, eventually, they dominate.
Because tackling nonlinearities is so complicated, Ciena’s approach is to approximate the problem as a linear Gaussian noise channel and do everything possible to mitigate the effects of nonlinearity rather than embrace it.
This is done by compensating at the transmitter the nonlinearities expected to happen along the fibre. The receiver performs measurements on a second-by-second basis and sends the results back. These are used as estimates of the anticipated nonlinearity about to be encountered and subtracted from the symbols to be sent.
Even though the exact nonlinearity is unknown, this is still a valid approximation. “It gives a quarter to one dB of performance improvement,” says Roberts
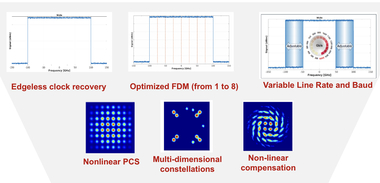
Edgeless clock recovery
Robert explains other clever signal processing techniques that buy a 6 per cent spectral efficiency improvement.
With wavelength division multiplexing (WDM), the laser-generated signals are placed next to each other across the fibre’s spectrum.
For WaveLogic 6, when running at its maximum symbol rate of 200 gigabaud, the spectrum occupies a 200GHz-wide channel.
Usually, the signal in the frequency domain is not perfectly square-shaped; the signal rolls off in the frequency domain so that in the time domain there is no inter-symbol interference. “But [as a result] you’re wasting spectrum; you are not fully using that spectrum,” says Roberts.
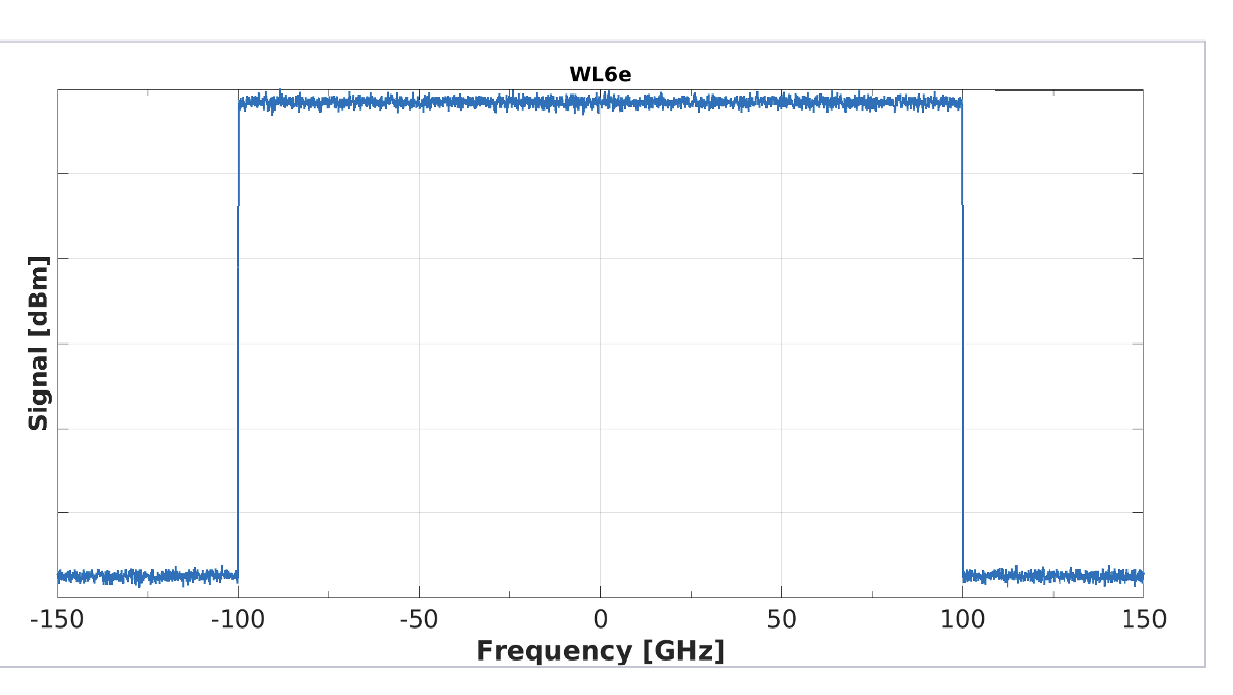
With WaveLogic 6, Ciena has created an idealised flat-topped, vertically edged signal spectra allowing the signals to be crammed side by side thereby making best use of the fibre’s spectrum (see diagram).
The challenge is that the clocking information used for data recovery at the receiver resided in this roll-off region. Now, that is no longer there so Cienahas developed another method to recover clock information.
A second challenge with signal recovery is that the transmit laser and the receive laser are not rigidly fixed in frequency. Being so close together, care is needed to recover only the wavelength – signal – of interest.
Yet another complication is how a rectangle in the frequency domain causes the signal in the time domain to ‘ring’ and go on forever.
“There are several signal processing methods that we had to develop to make this possible,” says Roberts.
Frequency-division multiplexing
Ciena also uses frequency division multiplexing (FDM), a technique it first introduced with the WaveLogic 5 Extreme.
The difference between WDM and FDM, explains Roberts, is that WDM uses different lasers to generate the wavelengths while FDM is generated by applying digital techniques to the same laser. “You are digitally combining different streams,” he says.
This is useful because it turns out that each fibre route has an optimum baud rate because of nonlinearities.
“If I’m using the full symbol rate of 200GBd, I can divide that into parallel streams, which behave as if they were independent circuits as far as nonlinearity is concerned,” says Roberts. “The optimum number of FDM in your spectrum is proportional to the square root of the total amount of dispersion, so high dispersion, more FDMs, low dispersion, just one.”
Ciena first added the option of four FDM with the WaveLogic 5. Now, WaveLogic 6 implements 1,2,4, and 8 FDM channels.

“For short distances, you want to go one signal at 200 gigabaud, or smaller if you’re reducing baud rate, but if you’re going very long distances, lots of dispersion, you go at eight parallel streams being sent at 25 gigabaud each,” he says.
But introducing FDM causes notches in the near-idealised rectangular spectrum mentioned earlier. Ciena has had to tackle that too.
“If you measure the spectrum, it’s completely flat, there are no notches between the FDMs, there is no wasted spectrum,” says Roberts.
Multi-dimensional coding
Multi-dimensional coding is a further technique used by Ciena to improve optical transmission, especially in troublesome cables where there are much nonlinearity and noise. It is challenging to get information through.
To understand multi-dimensional constellations, Roberts uses the example of a 16-QAM constellation, which he describes as a two-dimensional (2D) representation in one polarisation.
But if both polarisations of light are considered one signal, it becomes a 4D, 256-point (16×16) symbol. This can be further extended by including the symbols in adjacent time slots to form an 8D representation.
Ciena introduced this technique with its WaveLogic 3 Extreme coherent DSP, which supported the multi-dimension coding scheme 8D-2QAM to improve the reach or capacity of long-reach spans.
Now Ciena has introduced a family of such multi-dimensional schemes with WaveLogic 6 Extreme, executing in regions of very high nonlinearity and noise. These include 4, 8, and 16-dimensional constellations.
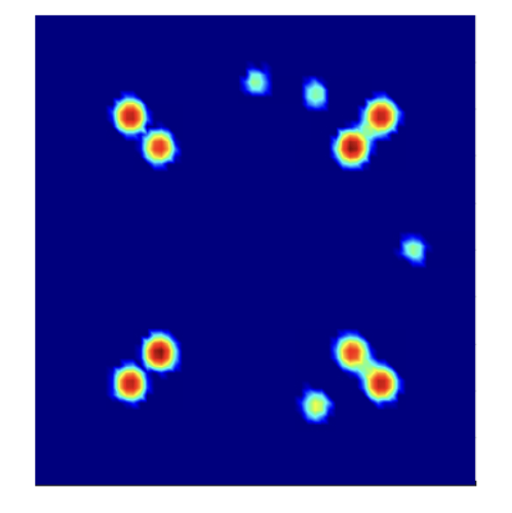
An example where the technique is used includes cases where there is twice as much noise as there is signal. “So the signal-to-noise ratio is -3dB,” says Roberts. Yet even here, 100 gigabits can still get through.
WaveLogic 6 Nano
Ciena also announced its 3nm CMOS WaveLogic 6 Nano DSP aimed at pluggable coherent modules. Is the Nano’s role to implement a subset of the signal processing capabilities of the Extreme?
Here, the customer’s requirements are different: heat, space and footprint are the dominant concerns. The Nano has to fit the heat envelope of the different sizes of pluggables, says Roberts. The optical performance is chosen based on fitting that heat requirement.
One of the merits of 3nm FinFET transistor technology is that if you don’t clock a circuit, only 1 per cent of the heat is generated compared to when it’s clocked, notes Roberts: “So, for different features, I can turn off the clock.”
A suitcase still full of tools?
At the time of the WaveLogic 5 launch, Roberts mentioned that there were still many tools left in the suitcase of ideas. Is this still true with the WaveLogic 6?
For Roberts, the question is: will it be economically viable to put in new capabilities based on the heat and performance and in terms of the size, schedule, and the amount of work involved?
Then, with a broad smile, he says: “There is room to occupy us as to how to get the next 10 to 20 per cent of spectral efficiency.”
And with that, we each set off for a day of meetings.
Roberts headed off to his hotel before his 10am meeting. I set off for the OFC exhibition hall and a meeting with the OIF.
As I walked to the convention centre, I kept thinking about the impromptu briefing and how I so nearly passed up on Roberts’ expertise and generosity.

Do optical DACs have a role in future coherent modems?

- A proposed optical digital-to-analogue converter (oDAC) concept offers several system benefits, including better signal performance, higher bit rates and lower power consumption.
- The oDAC design benefits coherent optics but can also be used in direct-detect designs. This article focusses on coherent optics.
- Coherent system vendors are aware of oDAC technology but it is not part of their current roadmaps.
Systems vendors continue to advance the performance of optical transmission systems. But they are the first to admit the task is getting more complex.
Long-distance transmission is challenging due to the channel impairments introduced by the optical fibre, such as noise, chromatic dispersion, and non-linearities.
Coherent modems have become the established technology that use a powerful digital signal processor (DSP) and optics to counter channel impairments.
In recent years the industry has progressed coherent technology to such a degree that it is now difficult to keep improving optical performance.
One critical component of the coherent DSP is the analogue front end: the transmitter’s digital-to-analogue converters (DACs) and the receiver’s analogue-to-digital converters (ADCs).
The DACs take the digital signal input and produce the analogue drive signal for the coherent optics’ Mach-Zehnder modulators. In turm, the DSP’s ADCs sample the signal at the receiver’s optics before recovering the transmitted data payload.
The challenge facing coherent DSP designers is to keep scaling the bandwidth of the DACs and ADCs while maintaining high resolution and high energy efficiency.
This growing challenge has led some researchers to propose alternatives.
One such proposal is an optical digital-to-analogue converter or oDAC.
The status of coherent DSPs
Recent announcements from leading coherent optic vendors, including Cisco’s Acacia, Ciena, Infinera, NEL, and Nokia, show the continual progress in hiking the symbol rate of coherent DSPs.

Vendors want to keep increasing the symbol rate – the frequency of the symbols where each symbol carries one or more bits, depending on the modulation scheme used – since it remains the best way to reduce the cost of sending network traffic.
First-generation coherent systems used a symbol of 32 gigabaud (GBd). Now, Acacia’s currently shipping 5nm CMOS Jannu DSP operates at up to 140GBd. Ciena, meanwhile, has detailed its WaveLogic 6 Extreme, the first coherent DSP implemented in 3nm CMOS that will work at up to 200GBd.
To scale the baud rate, all the sub-systems making up the coherent modem must scale.
The sub-systems include the DSP’s DACs and ADCs, the modulator drivers, and the trans-impedance amplifiers. The coherent optics – the coherent driver modulator (CDM) transmitter and the integrated coherent receiver (ICR) – must also scale.
For a 200GBd symbol rate, the bandwidth of all these components must reach 100GHz.
Looking ahead
The industry consensus is that coherent modems will reach 280-300GBd before the decade’s end. But to do so will require considerable engineering effort.
The industry offers less visibility after 300+GBd.
System vendors say that at some future point, it will not make economic sense to keep increasing the baud rate. It will be too costly to make the coherent modem and reducing the cost-per-bit will stop.
Already each new generation CMOS node is more costly while new materials are needed to scale the optics. Ciena says it is using silicon photonics for the integrated coherent receiver, while indium phosphide is being used for the transmitter’s modulators. Ciena is also looking at thin-film lithium niobate as a modulator technology.
As for DACs and ADCs, circuit designers face considerable challenges in achieving a 100GHz bandwidth.
Moreover, the DACs and ADCs sample faster than the baud rate, typically 1.2x. At OFC, imec, the Belgium technology research centre, outlined its work on 3nm coherent DSPs showing a sample rate of 250 giga-samples/s.

Such huge sampling rates explain the interest in optical DACs which can process a high-baud rate signal to generate, using optical parallelism, an ultra-high bit-rate signal based on either multi-level Pulse Amplitude Modulation (PAM) or Quadradure Amplitude Modulation (QAM) signals.
Two prominent professors promoting an optical DAC design are Ioannis Tomkos of the department of electrical and computer engineering at the University of Patras, Greece, and Moshe Nazarathy at the faculty of electrical engineering at the Technion University, Israel.
Limitations of DACs
Tomkos starts by highlighting the shortcomings of conventional DACs.
DACs not only have to operate sampling rates at least as high as the baud rate but they also have a finite resolution. Typically, 6-8 bits are used for coherent designs.
The effective number of bits (ENOB) available are even lower due to the clock jitter when operating the electrical circuits at such high speeds.
The finite effective number of bits limit the use of higher-order modulation schemes. Today, coherent systems use up to 16-ary quadrature amplitude modulation (16-QAM), except for the highest capacity, shortest-distance links.
A second issue is the non-linear nature of the optical modulator’s transfer function. “It’s a sine non-linearity type of response in Mach-Zehnder modulators due to the nature of interference,” says Tomkos.
This requires operating the modulator over a reduced range, the linear region of its transfer function around its biasing voltage.
Such curtailing of the driver saves power but results in ‘modulator loss’; the area occupied by the modulator’s constellation points is less than the ideal available (see top left diagram).
“You not driving the modulator to the limit,” says Tomkos. “Modulation loss can be as high as 9-12dB which impacts signal recovery at the receiver.”
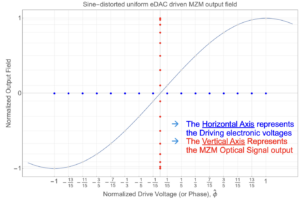
The relation between the driving DAC inputs and the discrete optical outputs is generally nonlinear (see diagram above). This means the constellation points look warped and are not spaced equally apart causing signal distortion.
Such optical distortion can be tackled using various specialised DAC architectures but the cost is either higher power, limited speed or extra modulation loss.
“Ideally, we would like to have equal distances between the symbols so we can robustly separate each symbol from the others since we also have electronic errors coming from the DACs that impact the quality of the symbols and shift them from their optimal points,” says Tomkos.
The impact of modulation loss and optical distortion also worsen when higher modulation schemes above 16-QAM are used.
The oDAC
Mention the term optical DAC, and specific thoughts come to mind. Is the optical signal sampled? Is the DAC electrical in its input and output, but its inner workings are photonic?
The optical DAC, as proposed by Nazarathy and Tomkos, is neither of the above. Moreover, it uses existing driver electronics based on the simplest traditional lowest-order DACs.
Indeed, the oDAC looks similar to a conventional coherent optics transmitter in terms of components, but the differences in operation and achieved performance are significant.
The oDAC can also be implemented in several ways bringing critical benefits for various system requirements.
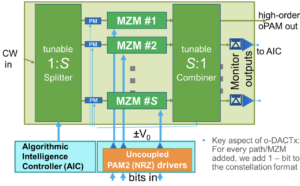
Architecture
A conventional coherent optical transmitter splits the incoming laser source and feeds the light equally to the in-phase and quadrature Mach-Zehnder modulators (one arm of which includes a 90-degree phase shifter).

The two Mach-Zehnder modulators are driven, as shown. In this example, two drivers implement a bipolar 4-level pulse amplitude modulation (PAM-4) signal such that the coherent transmitter produces a 16-QAM output signal.
The oDAC architecture is subtly different.
The oDAC’s main two components are a variable splitter and combiner at the input and output and the Mach-Zehnder modulator pair. Here, both modulators are identical; there is no 90o phase shifter but the differential phase is maintained at 0o degrees and the modulators are operated at full-scale resulting in zero modulation loss (see diagram at the article’s start).

Each modulator arm is driven by an electrical PAM-4 signal, and the variable splitter-combiner produces the bipolar PAM-16 optical output.
For 16-PAM, 4/5 of the laser signal is fed to one arm and the remaining 1/5 to the other. The PAM-4 DAC drivers for both Mach-Zehnder modulators are identical.
“In the first case, we had 16 symbols in two dimensions (i.e. QAM16); here we have 16 symbols, but in one dimension (i.e. PAM16), the other dimension is missing due to the absence of the 90-degree phase shifter,” says Tomkos.
According to Tomkos, the sine nonlinearity of the optical modulators here is an advantage. “The generated signal does not suffer from modulation loss and optical distortion due to electronic driver mismatch errors, as the noise coming from the electronic DACs gets squelched,” he says.
Higher-order modulation
As mentioned, the oDACs can be implemented and arranged in several ways.
For example, two oDACs can be used, one orthogonal in phase to the other, in a conventional coherent transmitter structure to generate a higher modulation signal. For example, two optical DAC arms, each 16-PAM, used as I and Q, will produce a 256-QAM signal.
But even more strikingly, more than two parallel modulation paths (by stacking-up more modulators in parallel, see diagram) can be used as an alternative approach to generating higher-order modulation schemes and higher bit rates, and at reduced power consumption per bit.
“The ratio between the bit rate and the baud rate is exactly the number of parallel paths,” says Nazarathy. “Another name for it is spectral efficiency: how many bits each symbol carries.”
The oDAC uses straightforward drivers. The professors say only PAM-2 or PAM-4 drivers are used. This way, power savings are maximised.
“The big picture is that we offload the electronics burden by going parallel optically,” says Nazarathy, adding that what is being traded is electronic DAC complexity and the associated performance limitations of the drivers for optical parallelism of replicated blocks of Mach-Zehnder modulators.
“You don’t want to stack things [photonic componentry] serially as if you keep stacking that way, you incur an optical loss because the loss is compounded,” says Nazarathy. Here, the modulators are stacked in parallel, the preferred integration approach.
Moreover, the more paths used, the higher-order the generated optical constellation is. “Eventually, only PAM-2 (Non-return-to-zero) drivers are used and that’s the minimum power consumption you can get,” says Tomkos.
“So we have parallelism (at the same laser power) that generates for the same baud rate, double or triple the bit rate [depending on whether 2 or 3 paths are used],” says Nazarathy. And the resulting constellations are near ideal: there is no modulation loss, nor is there optical distortion.
Nazarathy explains such benefits as the result of a ‘divide-and-conquer’ approach.
“If you keep the modulation paths simple, you have more freedom to optimise the drive point of the modulators,” he says. “The modulators benefit you more because they are more simply driven.” Then, by adding more modulator paths, the system performance improves overall.”
He also notes how the optical implementation is robust to imperfections generated by the electronic circuitry.
Optical DAC: A definition
- Two or more optical modulator units and some static or slowly-tuned ‘glue’ optics.
- The electrical drivers feeding the optical modulators are simple for lowest-power, either PAM2 (NRZ) or PAM4 drivers. Electronic DACs generating higher-order PAM are not needed.
- No high-speed power-hungry digital encoder (mapper) is used. The number of Mach-Zehnder modulators is B where the constellation size is C=2B. This is referred to as Direct Digital Drive. This last condition ensures the lowest power consumption.
Status
The oDAC work is currently at the research stage.
The working of the oDAC has been simulated and verified, and several papers have been published. Patents have also been filed.
At the recent OFC event in San Diago in March, Professor Tomkos met with hyperscalers, systems and components vendors to explain the oDAC technology and its benefits.
The two academics are focused on the oDAC in the optical transmitter, but Nazarathy says they also plan to surprise at the optical receiver end.
Tomkos says the optical DAC is an ideal fit for future coherent transmitters that will be used in 6G networks and datacenter networks, which will carry significant amounts of traffic at ultra-high rates.
The oDAC approach also bodes well for the trend of using linear drive optics. Indeed, the implementation of the oDAC hardware is carried out within the framework of a major R&D project called FLEX-SCALE that Tomkos is co-ordinating and is funded under the first phase of the 6G Smart Networks and Services (SNS) Partnership.
Tomkos believes that the first use of the optical DAC may likely be for data centre interconnect, a more mature market where higher-order modulation formats can be used and low-power is at a premium.
The professors are looking for partners and exploring options to commercialise the technology.

Ciena advances coherent technology on multiple fronts
- Ciena has unveiled the industry’s first coherent digital signal processor (DSP) to support 1.6-terabit wavelengths
- Ciena announced two WaveLogic 6 coherent DSPs: Extreme and Nano
- WaveLogic 6 Extreme operates at a symbol rate of up to 200 gigabaud (GBd) while the Nano, aimed at coherent pluggables, has a baud rate from 118-140GBd
Part 1: WaveLogic 6 coherent DSPs
Ciena has leapfrogged the competition by announcing the industry’s first coherent DSP operating at up to 200GBd.
The WaveLogic 6 chips are the first announced coherent DSPs implemented using a 3nm CMOS process.
Ciena’s competitors are – or will soon be – shipping 5nm CMOS coherent DSPs. In contrast, Ciena has chosen to skip 5nm and will ship WaveLogic 6 Extreme coherent modems in the first half of 2024.
Using a leading CMOS process enables the cramming of more digital logic and features in silicon. The DSP also operates a faster analogue front-end, i.e. analogue-to-digital converters (ADC) and digital-to-analogue (DAC) converters.
The WaveLogic 6 matches Ciena’s existing WaveLogic 5 family in having two DSPs: Extreme, for the most demanding optical transmission applications, and Nano for pluggable modules.
WaveLogic 6 Extreme is the first announced DSP that supports a 1.6-terabit wavelength; Acacia’s (Cisco) coherent DSP supports 1.2-terabit wavelengths and other 1.2-terabit wavelength DSPs are emerging.
WaveLogic 6 Nano addresses metro-regional networks and data centre interconnect (up to 120km). Here, cost, size, and power consumption are critical. Ciena will offer the WaveLogic 6 in QSFP-DD and OSFP pluggable form factors.
Class 3.5
Network traffic continues to grow exponentially. Ciena notes that the total capacity of its systems shipped between 2010 and 2021 has grown 150x, measured in petabits per second.
Increasing the symbol rate is the coherent engineers’ preferred approach to reduce the cost per bit of optical transport.
Doubling the baud rate doubles the data sent using the same modulation scheme. Alternatively, the data payload can be sent over longer spans.
However, upping the symbol rates increases the optical wavelength’s channel width. Advanced signal processing is needed to achieve further spectral efficiency gains.
One classification scheme of coherent modem symbol rate defines first-generation coherent systems operating at 30-34GBd as Class 1. Class 2 modems double the rate to 60-68GBd. The OIF’s 400ZR standard operating at 64GBd is a Class 2 coherent modem.
Currently-deployed optical transport systems operating at 90-107GBd reside between Class 2 and Class 3 (120-136GBd). Ciena’s WaveLogic 5 Extreme is one example, with its symbol rate ranging from 95-107GBd. Ciena has shipped over 60,000 WaveLogic 5 Extreme DSPs to over 200 customers.
Acacia’s latest CIM-8 coherent modem, now shipping, operates at 140GBd, making it a Class 3 design. Infinera, NEL, and Nokia announced their Class 3 devices before the OFC 2023 conference and exhibition.
Now Ciena, with its 200GBd WaveLogic 6 Extreme, sits alone between Class 3 and Class 4 (240-272GBd).
WaveLogic 6 Extreme
Ciena has extended the performance of all the components of the Extreme-based coherent modem to work at 200GBd.
These components include the DSP’s analogue front-end: the ADCs and DACs, the coherent optics and the modulator drivers and TIAs. All must operate with a 100GHz bandwidth.
To operate at 200GBd, the ADCs and DACs must sample over 200 giga-samples a second. This is pushing ADC and DAC design to the limit.
The coherent modem’s optics and associated electronics must also have a 100GHz operating bandwidth. Ciena developed the optics in-house and is also working with partners to bring the coherent optics to market with a 100GHz bandwidth.
Ciena uses silicon photonics for the Extreme’s integrated coherent receiver (ICR) optics. For the coherent driver modulator (CDM) transmitter, Ciena is using indium phosphide and is also evaluating other technology such as thin-film lithium niobate.

“There are multiple options that are available and being looked at,” says Helen Xenos, senior director of portfolio marketing at Ciena.
Much innovation has been required to achieve the fidelity with 100GHz electro-optics and get the signalling right between the transmitter-receiver and the ASIC, says Xenos.
Ciena introduced frequency division multiplexing (FDM) sub-carriers with the WaveLogic 5 Extreme, a technique to help tackle dispersion. With the introduction of edgeless clock recovery, Ciena has created a near-ideal rectangular spectrum with sharp edges.
“First, inside this signal, there are FDM sub-carriers, but you don’t see them because they are right next to each other,” says Xenos. “Getting rid of this dead space between carriers enables more throughput.”
Making the signal’s edges sharper means that wavelengths are packed more tightly, better using precious fibre spectrum. Edgeless clock recovery alone improves spectral efficiency by between 10-13 per cent, says Xenos.
Moving to 3nm allows additional signal processing. As an example, Ciena’s WaveLogic 6 Extreme DSP can select between 1, 2, 4 and 8 sub-carriers based on the dispersion on the link. WaveLogic 5 Extreme supports 4 sub-carrier FDM only.
The baud rate is also adjustable from 67-200GBd, while for the line rate, the WaveLogic 6 supports 200-gigabit to 1.6-terabit wavelengths using probabilistic constellation shaping (PCS).
Another signal processing technique used is multi-dimensional constellation shaping. These are specific modulations that are added to support legacy submarine links.
“For compensated submarine cables that have specific characteristics, they need a specialised type of design also in the DSP,” says Xenos.
Ciena also uses nonlinear compensation techniques to squeeze further performance and allow higher power signals, improving overall link performance.
Ciena can address terrestrial and new and legacy submarine links with the WaveLogic 6 Extreme running these techniques.
Xenos cites performance examples using the enhanced DSP performance of the WaveLogic 6 Extreme.
Using WaveLogic 5, an 800-gigabit wavelength can be sent at 95GBd using a 112.5GHz-wide channel. The 800-gigabit signal can cross several reconfigurable optical add-drop multiplexer (ROADM) hops.
Sending a 1.6-terabit wavelength at 185GBd over a similar link, the signal occupies a 200GHz channel. “And you get better performance because of the extra DSP enhancements,” says Xenos.
The operator Southern Cross has simulated using the WaveLogic 6 Extreme on its network and says the DSP will be able to send one terabit of data over 12,000km.
Optical transport systems benefits
Systems benefits of the Extreme DSP include doubling capacity, transmitting a 1.6-gigabit wavelength, and halving the power consumed per bit.
The WaveLogic 6 Extreme will fit within existing Ciena optical transport kit.
Xenos said the design goal is to get to the next level of cost and power reduction and maximise the network coverage for 800-gigabit wavelengths. This is why Ciena chose to jump to 3nm CMOS for the WaveLogic 6 Extreme, skipping 5nm CMOS.
WaveLogic 6 Nano
The 3nm CMOS WaveLogic 6 Nano addresses pluggable applications for metro and data centre interconnect.
“The opportunity is still largely in front of us [for coherent pluggables],” says Xenos.
The current WaveLogic 5 Nano operating between 31.5-70GBd addresses 100-gigabit to 400-gigabit coherent pluggable applications. These include fixed grid networks using 50GHz channels and interoperable modes such as OpenROADM, 400ZR and 400ZR+. Also supported is the 200-gigabit CableLabs specification.
The WaveLogic 5 Nano is also used in the QSFP-DD module with embedded amplification for high-performance applications.
There is also a new generation of specifications being worked on by standards bodies on client side and line side 800-gigabit and 1.6-terabit interfaces.
Developments mentioned by Xenos include an interoperable probabilistic constellation shaping proposal to be implemented using coherent pluggables.
The advent of 12.8-terabit and 25.6-terabit Ethernet switches gave rise to 400ZR. Now with the start of 51.2-terabit and soon 102.4-terabit switches, the OIF’s 800ZR standard will be needed.

There is also a ‘Beyond 400 Gig’ ITU-T and OpenROADM initiative to combine the interoperable OpenZR+ and the 400-gigabit coherent work of the OpenROADM MSA for a packet-optimised 800-gigabit specification for metro applications.
Another mode is designed to support not just Ethernet but OTN clients.
Lastly, there will also be long-distance modes needed at 400, 600, and 800-gigabit rates.
“With WaveLogic 6 Nano, the intent is to double the capacity within the same footprint,” says Xenos.
In addition to these initiatives, the WaveLogic 6 Nano will address a new application class for much shorter spans – 10km and 20km – at the network edge. The aim is to connect equipment across buildings in a data centre campus, for example.
Some customers want a single channel design and straightforward forward-error correction. Other customers with access to limited capacity will want a wavelength division multiplexed (WDM) solution.
The Nano’s processing and associated optics will be tuned to each application class. “The engineering is done so that we only use the performance and power required for a specific application,” says Xenos.
A Nano-based coherent pluggable connecting campus buildings will differ significantly from a pluggable sending 800 gigabits over 1,000km or across a metro network with multiple ROADM stages, she says.
The WaveLogic 6 Nano will be used with silicon photonics-based coherent optics, but other materials for the coherent driver modulator transmitter may be used.
Availability
Ciena taped out the first 3nm CMOS Extreme and Nano ICs last year.
The WaveLogic 6 Extreme-based coherent modem will be available for trials later this year. Product shipments and network deployments will begin in the first half of 2024.
Meanwhile, shipments of WaveLogic 6 Nano will follow in the second half of 2024.

Nubis' bandwidth-packed tiny optical engine

- Nubis Communications has revealed its ambitions to be an optical input-output (I/O) solutions provider
- Its tiny 1.6-terabit optical engine measures 5mm x 7.5mm
- The optical engine has a power consumption of below 4 picojoule/bit (pJ/b) and a bandwidth density of 0.5 terabits per millimetre.
- “Future systems will be I/O with an ASIC dangling off it.”
Nubis Communications has ended its period of secrecy to unveil an optical engine targeted at systems with demanding data input-output requirements.
The start-up claims its optical engine delivers unmatched bandwidth density measured in terabits per millimetre (T/mm) and power consumption performance metrics.
“In the timeframe of founding the company [in 2020], it became obvious that the solution space [for our product] was machine learning-artificial intelligence,” says Dan Harding, the CEO of Nubis.
Company Background
Nubis has raised over $40 million, with the lead investor being Matrix Partners. Venture capital company Matrix Partners backed Acacia Communications, acquired by Cisco in 2021.
Other Nubis backers are Weili Dai, a co-founder of Marvell Technologies, and Belgium-based imec.xpand.

“We have raised enough money to get to production with our product,” says Harding, who joined Nubis in 2021 from Broadcom.
Peter Winzer is the CTO and founder of the company. Formerly at Nokia Bell Labs, Winzer was the 2018 winner of the Optica (then OSA) and IEEE Photonics Society’s John Tyndall Award for his work on coherent optical communications.
Nubis has 40 staff, mostly engineers.
“As a team, we are multidisciplinary,” says Winzer. The company’s expertise includes silicon photonics, analogue IC design including serialisers/ deserialisers (serdes), packaging – electrical and optical, and software including advanced simulation tools.
“It is all geared towards a systems solution,” says Winzer. “We are not just looking at the PIC [photonic integrated circuit] or the electronics; we have the system and the architecture in mind.”
The input-output challenge
Machine learning workloads continue to grow at a staggering pace, doubling more than twice each year. Not surprisingly, computing systems running such workloads are struggling to keep up.
Scaling such systems not only requires more processing – more graphics processing units (GPUs) – but also networking to connect clusters of GPUs.
What the compute vendors want is any-to-any connectivity between processors and between clusters. This is creating a tremendous input-output challenge in terms of bandwidth density while keeping the power consumption under control.
“Over half the power of that cluster can be taken up by traditional optics,” says Harding. “So it is clear that the industry wants new solutions.”
“Whatever cents-per-gigabit [figure] you use, if you multiply it by the I/O capacity, the number you’ll get is many times that of [the cost of] an ASIC,” adds Winzer. “We say that future systems will be I/O with an ASIC dangling off it.”

Design details
Nubis’ optical engine is a 16 x 112-gigabit design with a footprint of 5mm x 7.5mm.
“Because we have our electronics flip-chipped on top, that’s the entire footprint,” says Winzer. “We maintain that it is the highest density by far of any optical engine.”
Nubis says many parallel fibres can be interfaced to the optical engine despite its tiny size.
Supporting parallel fibres is essential for machine learning systems as the fibres are fanned out to enable any-to-any connectivity.
Nubis’ engine uses a 4 by DR4 fan-out architecture with 36 fibres arranged in a 3×12 array.
Surface coupling in a 2D array interfaces the 36 fibres to the PIC: 32 fibres are for data and four for the external laser light source.
There is only a physical limit to the number of fibres that can be connected if edge coupling is used, says Winzer. But surface coupling in a 2D array means the optical engine delivers 5-10x more density than its competitors.
The start-up also has designed the engine’s electronics: the optical modulator driver and the trans-impedance amplifier (TIA). The electronics use advanced equalisation to boost the electrical channel, given direct drive has demanding requirements, says Harding.
The XT1600 optical module
Nubis’ first product is the XT1600 optical module. Here, a substrate houses the company’s PIC and electronics onto which is packaged a lid containing the optical fibres.
Nubis has developed in-house the packaging and the fibre attach solution.
The substrate is 15x15mm, somewhat larger than the engine. Harding says this is deliberate to support products under development.
The 1.6 terabits – in fact, 16x112Gbps full duplex – module has a 2km reach. Its power consumption is below 4 pJ/b.
The fibres exit the module vertically and bend to the side. “[Going] vertical is good but the 2D is the much more important aspect here,” says Winzer.
A 2D approach is logical, says Nubis. An electrical ball grid array (BGA) all the bottom surface. It makes sense that the optics is similarly massively 2D, especially for designs where its a 100-gigabit electrical signal in and a 100-gigabit optical signal out.
Multiple rings of optical I/O engines can surround the ASIC because the fibres exit vertically. “Nobody else can do that because they are escaping from the [PIC] edge,” says Winzer.
Winzer highlights another benefit of the design.
The Universal Chiplet Interconnect Express (UCIe) specification calls for 2T/mm bandwidth escape density. An optical chiplet can only achieve this if wavelength-division multiplexing (WDM) is used due to the large fibre size. Nubis can achieve this density optically without having to use WDM because of 2D surface coupling.
Doing all-to-all at scale remains a big system challenge. “We’re just a part of that challenge,” says Harding. But for optical I/O to become pervasive in the data centre over the next five years, the optics must be significantly lower power, smaller, and efficient.
“If you crack that 2D nut, you can do many, many great things down the road,” says Winzer. “We’ve solved a huge technology problem that allows us to scale much better than anybody else.”
Status
Nubis has not named its foundry and contract manufacturing partners but says they are large, high-volume manufacturers.
Harding says there are now up to five credible silicon photonic foundries available.
“There was some early product definition which some foundries were better suited to support,“ says Harding. “And there was a robustness of the initial PDKs [process design kits] to get us an early product that was important to us.”
Choosing a contract manufacturer proved easier, given the maturity of the players.
Nubis’ first product has 16 optical channels each at 112 gigabit, but future designs will offer N by 224-gigabit channels.
Meanwhile, the XT1600 optical engine is available for sampling.

Teramount brings pluggability to co-packaged optics
Hesham Taha, the CEO and co-founder of Teramount, describes the last two years for his company as eventful.
“Many things have happened on many fronts,” he says.
Teramount has developed a fibre assembly technology for designs integrating photonics and chips.
The start-up has raised $20 million in funding and has 30 staff. In addition, the company is recruiting staff experienced in manufacturing processes.
“The funding helps to support what we are working on today, which is manufacturing readiness,” says Taha.
Taha also notes marketplace changes as when the rising interest in co-packaged caused some companies that had stepped out of silicon photonics to return.
The marketplace moves reflect silicon photonics’ changing role. The technology is central for integrated designs such as co-packaged optics, whereas before, it had a more peripheral role when used for pluggable optics.
“This is a big change that requires optical integration with electronics, a change in packaging, and how you assemble fibres,” says Taha.
Plugs and bumps
Teramount’s technology coupling fibre to silicon photonics chips has two elements: a photonic bump and a photonic plug. The two combined avoid having to bond the fibre to the chip directly.
This is important for two reasons.
First, fibre bonding is an extra manufacturing step that impacts adversely the yield of an expensive chip.
Second, the plug, which is on a separate plane from the chip, working together with the photonic bump, enables the fibres to be detached and serviced, much like pluggable optics.
The photonic plug holds the fibres using a V-groove mechanism and couples them to the silicon photonics chip via the photonic bump, a component manufactured as part of the silicon photonics design.
It is the plug and bump combined that deliver large assembly tolerances. “The large tolerances is what enables the detachability,” says Taha.

It means a semiconductor company can avoid dealing with fibres and focus on what it does best: designing chips. Foundries and outsourced semiconductor assembly and test (OSAT) companies can handle the wafer-level plug and connect the fibres.
“If the right foundations are set on the silicon photonics wafer, then silicon photonics packaging can become very easy with detachable optics,” says Taha.
Surface coupling and edge coupling
Silicon photonics uses two approaches to couple the optical signal from the fibre to a photonics chip.
One, known as surface coupling, uses a grating coupler, while the second uses side coupling.
Grating couplers are wavelength dependent and send the light beam out at a specific angle. Therefore, changing the wavelength affects the angle, complicating the interfacing.

As part of the silicon photonics chip design, the photonic bump – effectively a lens – is positioned accurately next to the grating coupler.
In contrast, side coupling collects the beam for the silicon photonic chip’s waveguide from the edge of the die. Here, there is no spectral dependency. “You can inject in and out multiple wavelengths,” says Taha.
Teramount says side coupling is not viable for the volume manufacturing of silicon photonic designs.
“You cannot connect a fibre from the edge of the die; you have to prepare for a photonic bump before wafer dicing for side coupling,” says Taha.
Teramount’s design enables light to go to the side of the die, but instead of collecting it from the edge, the photonic bump deflects the beam vertically.
“The photonic bump shifts side coupling into the wideband surface coupling,” says Taha.
The photonic bump has two components in the wideband surface coupling case: a wideband deflector and a lens mirror for beam expansion.
The photonic bump and plug combined forms what Teramount calls self-aligning optics. “You have added more complexity in wafer-level manufacturing, but you have relaxed the tolerances in the assembly domain,” he says.
The resulting design has assembly tolerances of +/- 30 microns. “Altogether, over 60 microns, you lose only half a dB in misalignment tolerances,” he says.
Teramount supports both solutions: surface coupling for a single wavelength and wideband surface coupling for multiple wavelengths. Most customers are working with the wideband solution, says Taha.
The assembly tolerances, wideband surface coupling, and planar separation of the fibres from the die, are what enable fibre detachability, says Taha.
“A technician can manually assemble hundreds of fibres on a co-packaged optics stack,” he says.
The fibre assembly process is compatible with semiconductor packaging techniques. No fibre reflow soldering is needed, improving co-packaged optics’ yield while enabling the servicing of the fibre assembly for co-packaged optics.

Status
Teramount announced in 2022 a collaboration with EV Group, an equipment and process solutions supplier, to tackle wafer-level optics.
Taha says Teramount is working with foundries, OSATs and wafer-level optics manufacturers, such as EV group, to create an ecosystem for its photonic bump and photonic plug technology.
“We want the customer to have the ability to use a foundry to include in their wafer a photonic bump,” says Taha. “Once there, a customer can enjoy the photonic plug connector, its relaxed assembly tolerances, and detachable fibre connectivity.”
Teramount is also working with vendors in networking and computing, developers of co-packaged optics and optical input-output for processor clusters used for machine learning, respectively.
“We’ve already sent samples to customers that we are working with, which includes 32 fibres,” says Taha.
Teramount intends to announce more collaborations with vendors and wafer-manufacturing suppliers.

OFC 2023 show preview
- Sunday, March 5 marks the start of the Optical Fiber Communication (OFC) conference in San Diego, California
- The three General Chairs – Ramon Casellas, Chris Cole, and Ming-Jun Li – discuss the upcoming conference
OFC 2023 will be a show of multiple themes. That, at least, is the view of the team overseeing and coordinating this year’s conference and exhibition.
General Chair Ming-Jun Li of Corning who is also the recipient of the 2023 John Tyndall Award (see profiles, bottom), begins by highlighting the 1,000 paper submissions, suggesting that OFC has returned to pre-pandemic levels.
Ramon Casellas, another General Chair, highlights this year’s emphasis on the social aspects of technology. “We are trying not to forget what we are doing and why we are doing it,” he says.
Casellas highlights the OFC’s Plenary Session speakers (see section, below), an invited talk by Professor Dimitra Simeonidou of the University of Bristol, entitled: Human-Centric Networking and the Road to 6G, and a special event on sustainability.
This year’s OFC has received more submissions on quantum communications totaling 66 papers.
In the past, papers on quantum communications were submitted across OFC’s tracks addressing networking, subsystems and systems, and devices. However, evaluating them was challenging given that only some reviewers are quantum experts, says Chris Cole, the third General Chair. Now, OFC has a subcommittee dedicated to quantum.
Another first is OFCnet, a production network that will run during the show.
Themes and topics
Machine learning is one notable topic this year. The subject is familiar at OFC, says Casellas, but people are discussing it more.
Casellas highlights one session at OFC 2021 that addressed machine learning for optics and optics for machine learning. “It showed the duality of how you can use photonic components to do machine learning and apply machine learning to optimise networking,” says Casellas.
This year there will be additional aspects of machine learning for networks, transmission, and operations, says Casellas.
Other General Chair highlighted subjects include point-to-multipoint coherent transmission, non-terrestrial and satellite networks, and optical switching and how its benefits networking in the data centre.
Google, for example, is presenting a paper detailing its use of optical switching in its data centres, something the hyperscaler disclosed at the ACM Sigcomm conference in August 2022.
There is also more interest in fibre sensors used in communications networks.
“We see an increasing trend because now if you want smart networks, you need sensors everywhere,” says Li.
“That is another theme that goes across all the tracks, which is a non-traditional optical fibre communication area that we’ve been embracing,” adds Cole.
As examples, Cole cites lidar, radio over fibre, free-space communications, microwave fibre sensing, and optical processing.
OFC has had contributions in these areas, he says, but now these topics have dedicated subcommittee titles.
Plenary session
This year’s three Plenary Session speakers are:
- Patricia Obo-Nai, CEO of Vodafone Ghana, who will discuss Harnessing Digitalization for Effective Social Change,
- Jayshree V. Ullal, president and CEO of Arista Networks, addressing The Road to Petascale Cloud Networking,
- and Wendell P. Weeks, chairman and CEO of Corning, whose talk is entitled Capacity to Transform.
“We thought that having someone who could explain how technology improves society would be very positive,” says Casellas. “I’m proud to have someone who can talk on the benefits of digitisation from the point of view of society, in addition to more technical topics.”
Li highlights how OFC celebrated the 50th anniversary of low-loss fibre two years ago and that last year, OFC celebrated the year of glass, displaying information on panels.
Corning has played an important role in both technologies. “Having a speaker [Wendell Weeks] from a glass company talking about both will be interesting to the OFC audience,” says Li.
Cole highlights the third speaker, Jayshree Ullal, the CEO of Arista. The successful networking player is one of the companies competing in what he describes as a very tough field.
Rump session
This year’s Rump Session tackles silicon photonics, a session moderated by Daniel Kuchta of IBM TJ Watson Research Center and Michael Hochberg of Luminous Computing.
Cole says silicon photonics has received tremendous attention, and the Rump Session is asking some tough questions: “Is silicon photonics for real now? Is it just one of the guys in the toolbox? Or is it being sunsetted or supplemented?”
Cole expects a lively session, not just challenging conventional thinking but having people representing exciting alternatives which are commercially successful alongside silicon photonics.
Show interests
The Chairs also highlight their interests and what they hope to learn from the show.
For Li, it is high-density fibre and cable trends.
Work on space division multiplexing (SDM) – multicore and multimode – fibre has been an OFC topic for over 15 years. One question Li has is whether systems will use SDM.
“It looks like multicore fibre is close, but we want to learn more from customers,” says Li.
Another interest is an alternative development of reduced coating diameter fibres that promise greater cable density. “I always think this is probably the short-term solution, but we’ll see what people think,” says Li.
AI drives interest in fibre density and latency issues in the data centre. Low latency is attracting interest in hollow-core fibre. Microsoft acquired Lumenisity, a UK hollow core fibre specialist, late last year.
Li is keen to learn more about quantum communications. “We want to understand, from a fibre component point of view, what to do in this area.”
Until now industry focus has been on quantum key distribution (QKD), but Li wants to learn about other applications of quantum in telecoms.
The bandwidth challenge facing datacom is Cole’s interest.
As the Rump Session shows, there has been an explosion of technologies to address data challenges, particularly in the data centre. “So I’m looking forward to continuing to see all the great ideas and all the different directions,” says Cole.
Another show interest for Cole is start-ups in components, subsystems and systems, and networking.
At Optica’s Executive Forum, held on Monday, March 6, a session is dedicated to start-ups. Casellas is looking forward to the talks on optical network automation.
Much work has applied machine learning to optical transmission and amplifier optimisation. Casellas wants to see how reinforcement learning is applied to optical network controllers. Telemetry and its use for network monitoring are another of his interests.
“Maybe because I’m an academic and idealistic, but I like everything related to disaggregation and the opening of interfaces,” says Casellas, who too wants to learn more about quantum.
“I have a basic understanding of this, but maybe it is hard to get into something new,” says Casellas. Non-terrestrial and satellite networks are other topics of interest.
Cole concludes with a big-picture view of photonics.
“It’s a great time to be in optics,” he says. “We’re seeing an explosion of creativity in different areas to solve problems.”
Ramon Casellas works at the Centre Tecnològic de Telecomunicacions de Catalunya (CTTC) research institution in Barcelona, Spain. His research focuses on networks – particularly the control plane, operations and management – rather than optical systems and devices.
Ming-Jun Li is a Corporate Fellow at Corning where he has that worked for 32 years.
Li is also this year’s winner of the John Tyndall Award, presented by Optica and the IEEE Photonics Society. The award is for Li’s ‘seminal contributions to advances in optical fibre technology.’
“It was a surprise to me and a great honour,” says Li. “The work is not only for myself but for many people working with me at Corning; I cannot achieve without working with meaningful colleagues.”
Chris Cole is a consultant whose background is in datacom optics. He will be representing the company, Coherent, at OFC.